Data Integration in Data Mining
Last Updated :
01 Feb, 2023
INTRODUCTION :
- Data integration in data mining refers to the process of combining data from multiple sources into a single, unified view. This can involve cleaning and transforming the data, as well as resolving any inconsistencies or conflicts that may exist between the different sources. The goal of data integration is to make the data more useful and meaningful for the purposes of analysis and decision making. Techniques used in data integration include data warehousing, ETL (extract, transform, load) processes, and data federation.
Data Integration is a data preprocessing technique that combines data from multiple heterogeneous data sources into a coherent data store and provides a unified view of the data. These sources may include multiple data cubes, databases, or flat files.
The data integration approaches are formally defined as triple <G, S, M> where,
G stand for the global schema,
S stands for the heterogeneous source of schema,
M stands for mapping between the queries of source and global schema.
What is data integration :
Data integration is the process of combining data from multiple sources into a cohesive and consistent view. This process involves identifying and accessing the different data sources, mapping the data to a common format, and reconciling any inconsistencies or discrepancies between the sources. The goal of data integration is to make it easier to access and analyze data that is spread across multiple systems or platforms, in order to gain a more complete and accurate understanding of the data.
Data integration can be challenging due to the variety of data formats, structures, and semantics used by different data sources. Different data sources may use different data types, naming conventions, and schemas, making it difficult to combine the data into a single view. Data integration typically involves a combination of manual and automated processes, including data profiling, data mapping, data transformation, and data reconciliation.
Data integration is used in a wide range of applications, such as business intelligence, data warehousing, master data management, and analytics. Data integration can be critical to the success of these applications, as it enables organizations to access and analyze data that is spread across different systems, departments, and lines of business, in order to make better decisions, improve operational efficiency, and gain a competitive advantage.
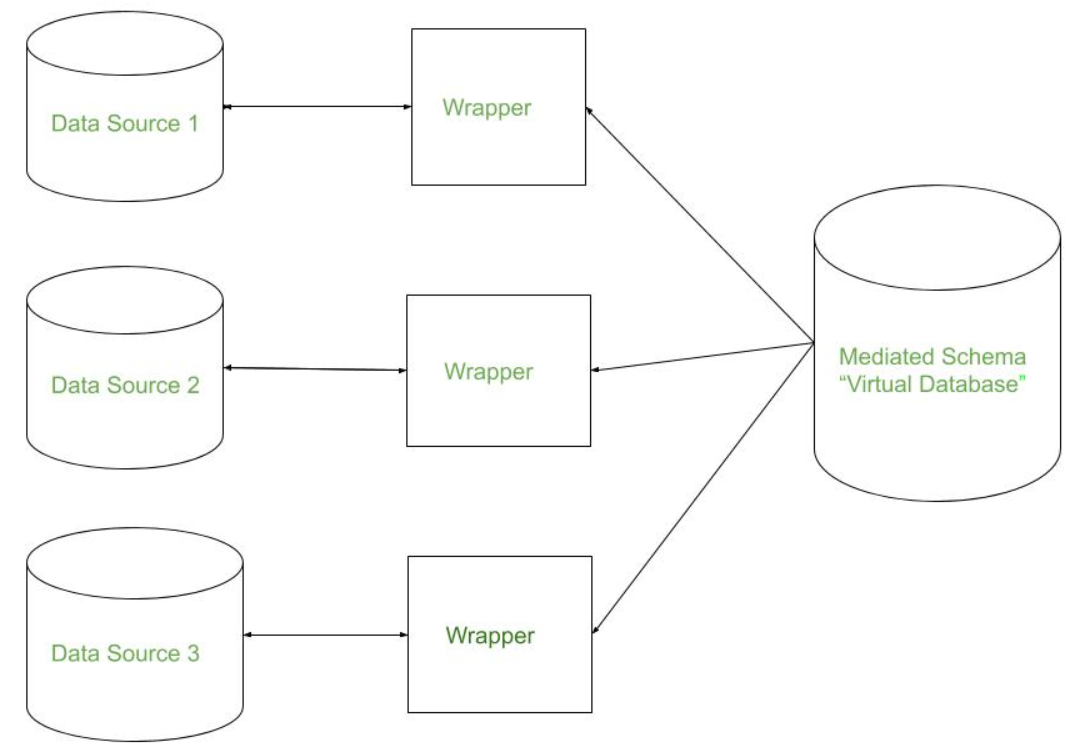
There are mainly 2 major approaches for data integration – one is the “tight coupling approach” and another is the “loose coupling approach”.
Tight Coupling:
This approach involves creating a centralized repository or data warehouse to store the integrated data. The data is extracted from various sources, transformed and loaded into a data warehouse. Data is integrated in a tightly coupled manner, meaning that the data is integrated at a high level, such as at the level of the entire dataset or schema. This approach is also known as data warehousing, and it enables data consistency and integrity, but it can be inflexible and difficult to change or update.
- Here, a data warehouse is treated as an information retrieval component.
- In this coupling, data is combined from different sources into a single physical location through the process of ETL – Extraction, Transformation, and Loading.
Loose Coupling:
This approach involves integrating data at the lowest level, such as at the level of individual data elements or records. Data is integrated in a loosely coupled manner, meaning that the data is integrated at a low level, and it allows data to be integrated without having to create a central repository or data warehouse. This approach is also known as data federation, and it enables data flexibility and easy updates, but it can be difficult to maintain consistency and integrity across multiple data sources.
- Here, an interface is provided that takes the query from the user, transforms it in a way the source database can understand, and then sends the query directly to the source databases to obtain the result.
- And the data only remains in the actual source databases.
Issues in Data Integration:
There are several issues that can arise when integrating data from multiple sources, including:
- Data Quality: Inconsistencies and errors in the data can make it difficult to combine and analyze.
- Data Semantics: Different sources may use different terms or definitions for the same data, making it difficult to combine and understand the data.
- Data Heterogeneity: Different sources may use different data formats, structures, or schemas, making it difficult to combine and analyze the data.
- Data Privacy and Security: Protecting sensitive information and maintaining security can be difficult when integrating data from multiple sources.
- Scalability: Integrating large amounts of data from multiple sources can be computationally expensive and time-consuming.
- Data Governance: Managing and maintaining the integration of data from multiple sources can be difficult, especially when it comes to ensuring data accuracy, consistency, and timeliness.
- Performance: Integrating data from multiple sources can also affect the performance of the system.
- Integration with existing systems: Integrating new data sources with existing systems can be a complex task, requiring significant effort and resources.
- Complexity: The complexity of integrating data from multiple sources can be high, requiring specialized skills and knowledge.
There are three issues to consider during data integration: Schema Integration, Redundancy Detection, and resolution of data value conflicts. These are explained in brief below.
1. Schema Integration:
- Integrate metadata from different sources.
- The real-world entities from multiple sources are referred to as the entity identification problem.ER
2. Redundancy Detection:
- An attribute may be redundant if it can be derived or obtained from another attribute or set of attributes.
- Inconsistencies in attributes can also cause redundancies in the resulting data set.
- Some redundancies can be detected by correlation analysis.
3. Resolution of data value conflicts:
- This is the third critical issue in data integration.
- Attribute values from different sources may differ for the same real-world entity.
- An attribute in one system may be recorded at a lower level of abstraction than the “same” attribute in another.
Share your thoughts in the comments
Please Login to comment...