Modal Collapse in GANs
Last Updated :
02 May, 2023
Prerequisites: General Adversarial Network
Although Generative Adversarial Networks are very powerful neural networks that can be used to generate new data similar to the data upon which it was trained upon, It is limited in the sense that it can be trained upon only single-modal data ie Data whose dependent variable consists of only one categorical entry.
Modal collapse in GANs (Generative Adversarial Networks) occurs when the generator model produces a limited set of outputs that fail to capture the full diversity of the real data distribution. In other words, the generator starts producing similar or identical samples, leading to a collapse in the modes of the data distribution. This can happen when the discriminator becomes too strong, such that the generator fails to produce diverse samples that can fool the discriminator.
Modal collapse is a significant problem in GANs because it leads to a loss of diversity in the generated samples, which can render the GAN useless for many applications. There are several strategies to address modal collapse in GANs, including:
- Increasing the capacity of the generator or discriminator model.
- Adjusting the learning rate or optimization algorithm.
- Using regularization techniques such as weight decay or dropout to prevent overfitting.
- Incorporating diversity-promoting techniques such as diversity regularization or adding noise to the input or output of the generator.
- Using alternative GAN architectures that are less prone to mode collapse, such as Wasserstein GANs or InfoGANs.
Modal collapse is an active area of research in the GAN community, and new techniques are being developed to address this problem and improve the stability and diversity of GAN-generated samples.
If a Generative Adversarial Network is trained on multi-modal data, it leads to Modal Collapse. Modal Collapse refers to a situation in which the generator part of the network generates only a limited amount of variety of samples regardless of the input. This means that when the network is trained upon multi-modal data directly, the generator learns to fool the discriminator by generating only a limited variety of data.
The following flow-chart illustrates training of a Generative Adversarial Network when trained upon a dataset containing images of cats and dogs:
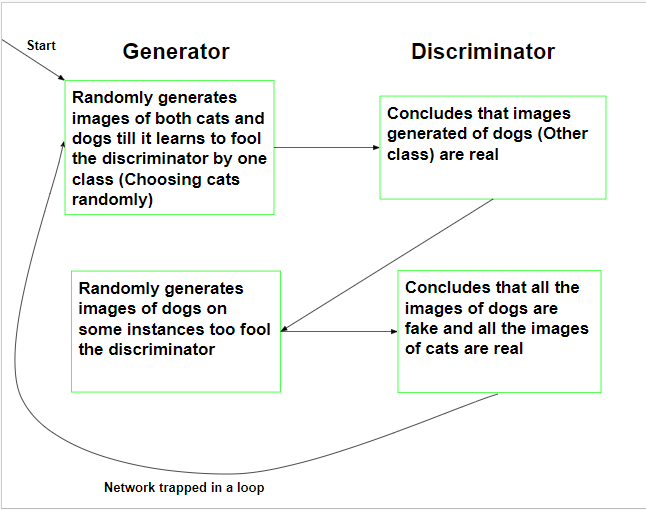
The following approaches can be used to tackle Modal Collapse:-
- Grouping the classes: One of the primary methods to tackle Modal Collapse is to group the data according to the different classes present in the data. This gives the discriminator the power to discriminate against sub-batches and determine whether a given batch is real or fake.
- Anticipating Counter-actions: This method focuses on removing the situation of the discriminator “chasing” the generator by training the generator to maximally fool the discriminator by taking into account the counter-actions of the discriminator. This method has the downside of increased training time and complicated gradient calculation.
- Learning from Experience: This approach involves training the discriminator on the old fake samples which were generated by the generator in a fixed number of iterations.
- Multiple Networks: This method involves training multiple Generative networks for each different class thus covering all the classes of the data. The disadvantages include increased training time and a typical reduction in the quality of the generated data.
Modal collapse in GANs is a disadvantage because it leads to a loss of diversity in the generated samples, which can render the GAN useless for many applications. However, there are no advantages to modal collapse in GANs. Instead, modal collapse is considered a significant problem that must be addressed for GANs to be effective in generating diverse and realistic samples.
To expand on this, some specific advantages and disadvantages of addressing modal collapse in GANs can be:
Advantages:
- Improved quality and diversity of generated samples.
- Enhanced usefulness of GANs for applications such as image generation, video generation, and text generation.
- Increased stability and reliability of GAN training.
- Better generalization performance of GANs.
- Ability to learn complex data distributions, making GANs well-suited for tasks such as image and video synthesis, data augmentation, and data denoising.
- Flexibility to generate samples in different styles, allowing for creative applications in art, fashion, and design.
- Potential for use in various fields including medicine, finance, and social sciences for tasks such as drug discovery, financial forecasting, and data analysis.
- GANs can learn from unstructured data, making them effective for tasks such as natural language processing and speech synthesis.
Disadvantages:
- Higher computational and training costs due to the need for more complex or diverse GAN architectures and training strategies.
- Increased risk of overfitting or instability if regularization or diversity-promoting techniques are not applied appropriately.
- More difficult to train and optimize compared to simpler generative models such as autoencoders.
- Difficulty in training and tuning hyperparameters, requiring expertise in machine learning and deep learning.
- Risk of generating biased or discriminatory samples if the training data is biased or if the GAN is not designed to promote fairness and diversity.
- Challenges in evaluating the performance of GANs, as there are no standard metrics for evaluating the quality or diversity of generated samples.
- Vulnerability to adversarial attacks, where malicious actors can manipulate the GAN’s input to generate misleading or malicious outputs.
Share your thoughts in the comments
Please Login to comment...