DALLE 2 Architecture
Last Updated :
09 Apr, 2024
Recent advancements in text-based image generation models have captured the collective imagination, seamlessly blending linguistic expression with visual creativity. Models such as Midjourney, Stable Diffusion, and DALL-E have gained popularity, with DALL-E 2 emerging as a notable successor to its predecessor. This open-source model, developed by OpenAI, leverages the diffusion model for image generation, departing from the limitations of DALL-E 1. In this tutorial, we will deep dive into the DALL-E 2’s architecture, and how does it works?
What is Dall-E 2?
DALL-E 2, the successor to its predecessor DALL-E, represents an open-source breakthrough by OpenAI. While DALL-E 1 employed discrete variational autoencoders (dVAE) for image generation, its revolutionary approach had constraints in terms of image resolution, realism, and image refinement. In contrast, DALL-E 2’s architecture pivots towards the diffusion model, departing from dVAE, allowing it to directly generate images from CLIP embeddings.
The inception of DALL-E 2 is documented in the paper “Hierarchical Text-Conditional Image Generation with CLIP Latents,” initially introduced as UnCLIP. The nomenclature UnCLIP was chosen due to its unique approach of image generation by inversely utilizing the CLIP image encoder. Over time, this innovative model earned its more recognized title as DALL-E 2.
Dall-E 2 Architecture
There are three main components of DALLE-2:
- CLIP: Clip is an open-source model and it tells whether a text embedding matches the image embedding or not.
- Diffusion Prior (based on transformer): For generating clip image embeddings based on clip text embeddings.
- Decoder (based on diffusion model): For generating image.
Below is the overall architecture as presented in the original paper. Let us discuss each of the components in detail.

DALLE 2 Architecture
1. Contrastive Language-Image Pre-training (CLIP)
The component shown above the dotted line is the clip component. CLIP is trained first. The objective of CLIP is to align text embeddings and image embeddings. CLIP tells how much a given text relates to an image.Note – It does not tell the caption for an image. It only whether a given description is a good fit or not for a given image
CLIP is trained as per the below process.
- All image and their true captions or descriptions are encoded. There is a separate encoder for images and a separate encoder for text.
- The cosine similarity between the encoded vectors of the image and text description is calculated.
- The training objective is to maximize the similarity between the correct pair of image and text embeddings and minimize the similarity between incorrect image and text embeddings.
- During inference time the embedding of image and text description is obtained through the trained image and text encoder and a similarity score is calculated which indicates the relevance of text descriptionconcerningo the image
Below is the architecture of CLIP as per the original paper

2 . Diffusion Prior
After the training of CLI, P the diffusion prior and image decoder are trained. The objective of diffusion prior is to take text embedding and find its associated CLIP image embeddings. Too so it takes help for the CLIP model trained in step 1.
The diffusion prior is a decoer only transformed with a causal attention mask. The input consists of 4 vectors.
- Noise clip image embedding
- Diffusiontimestepp
- Encoded text
- CLIP text embedding
- For a given correct text image pair we find its CLIP image embedding and CLIP text embedding
- Noise is added to the CLIP image embedding. The amount of noise added depends on the diffusion timestep. As we proceed further and further more noise is added
- The purpose of the diffusion prior is to predict the CLIP image embeddings.
- The MSE loss between the original CLIP embedding and predicted CLIP image embedding is used as the loss function
3. Image Decoder
The purpose of the image decoder is to use the CLIP image embedding predicted by the diffusion prior and generate an image based on this. The diffusion model of the image decoder is based on the paper GLIDE: Towards Photorealistic Image Generation and Editing with text-Guided Diffusion Models. The GLIDE paper combined the diffusion process with UNET architecture.
UNET Architecture
- The left part of the U-NET architecture consists of a series of convolutional and pooling layers, which function as an encoder. This part captures the contextual information in the input image.
- The right part of the U-Nent consists of a series of upsampling and convolutional layers, forming the decoder
- The U-Net architecture consists of skip connections. These connections directly link the corresponding encoder and decoder layers to enable the network to use both high-level spatial information and low-level spatial information.
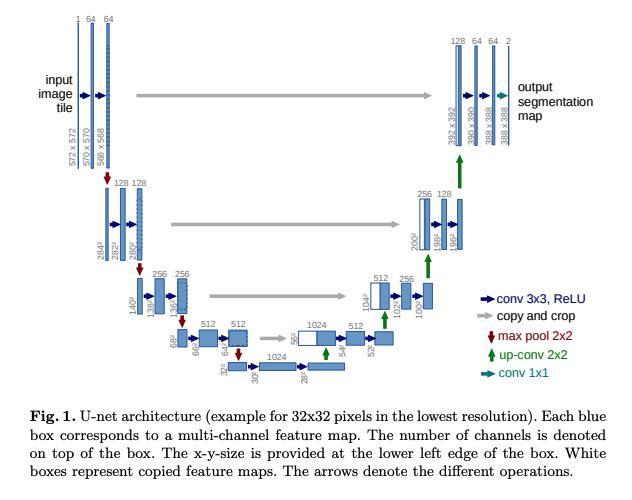
Unet architecture
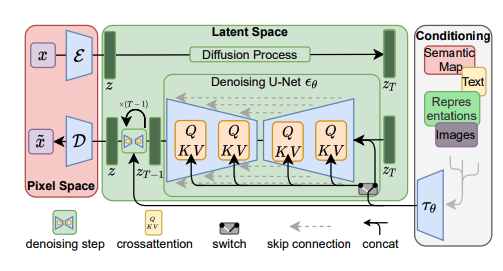
Diffusion process
- The above unet architecture is utilized to build and train a diffusion model as shown below. The training process for a diffusion model involves two main steps:
- Forward diffusion: The model takes a clear image as input and adds noise to it.
- Reverse diffusion: The model aims to reconstruct the original clear image from the noisy version
- Between each block of the encoder and decoder we have a cross-attention layer. This cross-attention layer takes the clip embeddings of text embeddings and output of the previous layer to generate a context vector which is used in the next layer. This helps in guided text generation.
- The output of the decoder is further upsampled to increase the resolution of the image.
How does Dall-e-2 make variations?
Not let us put together all the components to understand how dalle-2 works
- The CLIP text encoder encodes the text embedding by analyzing the text description the user provides
- The Diffusion prior uses the text embedding of the CLIP encoder and converts it to CLIP image encoding. This image encoding captures the key ideas from the user prompt.
- The image decoder generates the image based on CLIP image embedding. It utilizes CLIP text embedding for conditional generation. The decoder introduces some randomness during the creation process. This randomness is what allows DALL-E 2 to generate multiple variations that all relate to your original prompt but have slight differences
Another feature that highlights DALL·E 2’s awareness of image content and style is its capacity to create variations of a given image. With the use of this feature, users can request variations for an original image
The model can create changes in response to instructions from the user by preserving the original’s basic features and at the same time making precise changes. This is how DALL·E 2 does it:
- Decoding the original Image’s Contents: Identify key elements of the image using the image encoder
- Understanding image context: It then aims to find the best textual description of the image. It utilizes CLIP and the chat got the model to do so.
- Combining textual Prompts: Since it now has the textual as well as visual understanding of the image it aims to incorporate the changes proposed by the user in the prompt. It first understands the difference between the current textual description and the changes provided by the user. It then uses this difference vector to modify specific elements of the image embeddings. It does so by aiming to keep the essence and context of the original image intact. This means that while certain aspects may change, the overall theme is preserved.
- Re-synthesis of the Image: The model then synthesizes new images that reflect the original’s context and any new directions provided by the user’s prompts.
Applications of DALL-E 2
Image generation models like DALL-E-2 have a wide range of applications
- Generating New Content: They can be used for new content generation that aids in visual learning
- Art: They can be used for exploring creative designs by artists and designers.
- Marketing: They can be used by marketing agencies to create creative content and generate variation of it in minutes based on target audience description
- Research: They can help in aiding research by generating new datasets.
- New frontiers: Models like dalle-2 have further led to the development of models like the text to video(SORA)
Share your thoughts in the comments
Please Login to comment...