Map Reduce and its Phases with numerical example.
Last Updated :
18 May, 2023
Map Reduce :-
It is a framework in which we can write applications to run huge amount of data in parallel and in large cluster of commodity hardware in a reliable manner.
Different Phases of MapReduce:-
MapReduce model has three major and one optional phase.
- Mapping
- Shuffling and Sorting
- Reducing
- Combining
Mapping :- It is the first phase of MapReduce programming. Mapping Phase accepts key-value pairs as input as (k, v), where the key represents the Key address of each record and the value represents the entire record content.The output of the Mapping phase will also be in the key-value format (k’, v’).
Shuffling and Sorting :- The output of various mapping parts (k’, v’), then goes into Shuffling and Sorting phase. All the same values are deleted, and different values are grouped together based on same keys. The output of the Shuffling and Sorting phase will be key-value pairs again as key and array of values (k, v[ ]).
Reducer :- The output of the Shuffling and Sorting phase (k, v[]) will be the input of the Reducer phase. In this phase reducer function’s logic is executed and all the values are Collected against their corresponding keys. Reducer stabilize outputs of various mappers and computes the final output.
Combining :- It is an optional phase in the MapReduce phases . The combiner phase is used to optimize the performance of MapReduce phases. This phase makes the Shuffling and Sorting phase work even quicker by enabling additional performance features in MapReduce phases.

flow chart
Numerical:-
MovieLens Data
USER_ID MOVIE_ID RATING TIMESTAMP
196 242 3 881250949
186 302 3 891717742
196 377 1 878887116
244 51 2 880606923
166 346 1 886397596
186 474 4 884182806
186 265 2 881171488
Solution : –
Step 1 – First we have to map the values , it is happen in 1st phase of Map Reduce model.
196:242 ; 186:302 ; 196:377 ; 244:51 ; 166:346 ; 186:274 ; 186:265
Step 2 – After Mapping we have to shuffle and sort the values.
166:346 ; 186:302,274,265 ; 196:242,377 ; 244:51
Step 3 – After completion of step1 and step2 we have to reduce each key’s values.
Now, put all values together
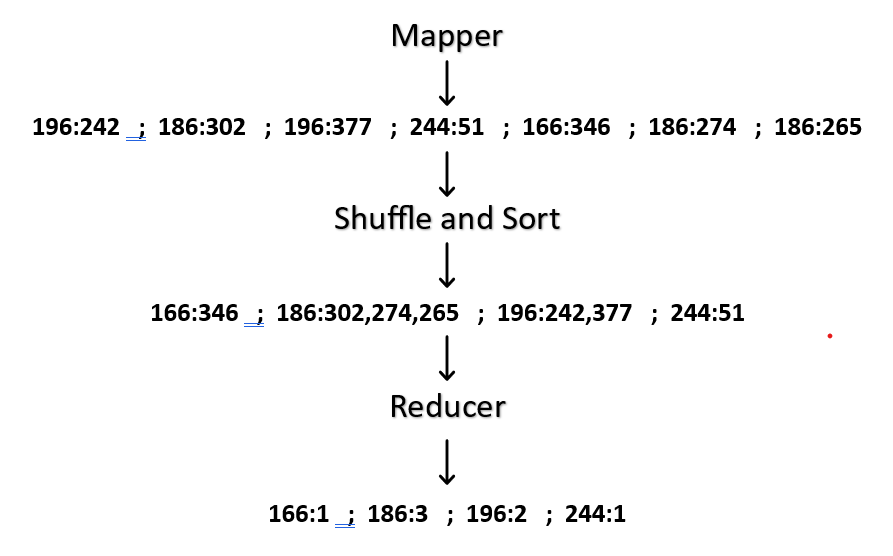
Solution
CODE FOR MAPPER AND REDUCER TOGETHER:
Python3
from mrjob.job import MRJob
from mrjob.step import MRStep
class RatingsBreak(MRJob):
def steps(self):
return [
MRstep(mapper=self.mapper_get_ratings,
reducer=self.reducer_count_ratings)
]
def mapper_get_ratings(self, _, line):
(User_id, Movie_id, Rating, Timestamp) = line.split('/t')
yield rating,
def reducer_count_ratings(self, key, values):
yield key, sum(values)
|
Share your thoughts in the comments
Please Login to comment...