Difference between Hadoop 1 and Hadoop 2
Last Updated :
23 Jun, 2022
Hadoop is an open source software programming framework for storing a large amount of data and performing the computation. Its framework is based on Java programming with some native code in C and shell scripts.
Hadoop 1 vs Hadoop 2
1. Components: In Hadoop 1 we have MapReduce but Hadoop 2 has YARN(Yet Another Resource Negotiator) and MapReduce version 2.
| Hadoop 1 |
Hadoop 2 |
| HDFS |
HDFS |
| Map Reduce |
YARN / MRv2 |
2. Daemons:
| Hadoop 1 |
Hadoop 2 |
| Namenode |
Namenode |
| Datanode |
Datanode |
| Secondary Namenode |
Secondary Namenode |
| Job Tracker |
Resource Manager |
| Task Tracker |
Node Manager |
3. Working:
- In Hadoop 1, there is HDFS which is used for storage and top of it, Map Reduce which works as Resource Management as well as Data Processing. Due to this workload on Map Reduce, it will affect the performance.
- In Hadoop 2, there is again HDFS which is again used for storage and on the top of HDFS, there is YARN which works as Resource Management. It basically allocates the resources and keeps all the things going on.
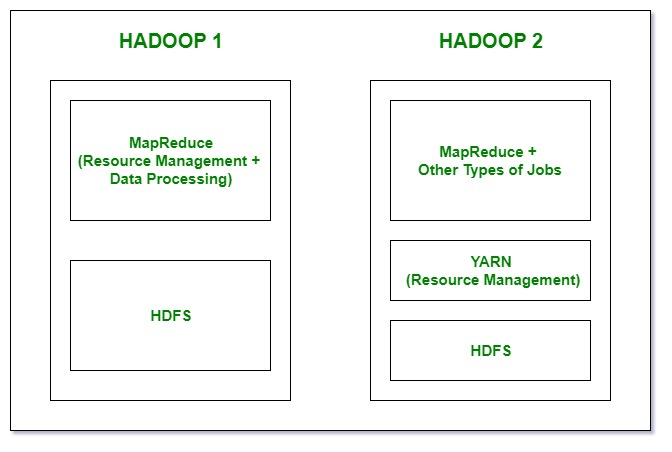
4. Limitations: Hadoop 1 is a Master-Slave architecture. It consists of a single master and multiple slaves. Suppose if master node got crashed then irrespective of your best slave nodes, your cluster will be destroyed. Again for creating that cluster means copying system files, image files, etc. on another system is too much time consuming which will not be tolerated by organizations in today’s time. Hadoop 2 is also a Master-Slave architecture. But this consists of multiple masters (i.e active namenodes and standby namenodes) and multiple slaves. If here master node got crashed then standby master node will take over it. You can make multiple combinations of active-standby nodes. Thus Hadoop 2 will eliminate the problem of a single point of failure.
5. Ecosystem:
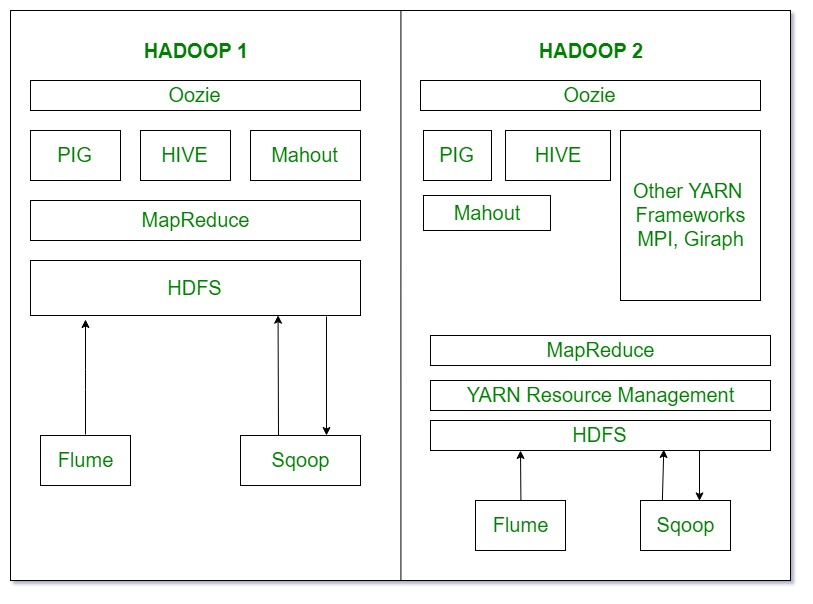
- Oozie is basically Work Flow Scheduler. It decides the particular time of jobs to execute according to their dependency.
- Pig, Hive and Mahout are data processing tools that are working on the top of Hadoop.
- Sqoop is used to import and export structured data. You can directly import and export the data into HDFS using SQL database.
- Flume is used to import and export the unstructured data and streaming data.
6. Windows Support:
in Hadoop 1 there is no support for Microsoft Windows provided by Apache whereas in Hadoop 2 there is support for Microsoft windows.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...