Hadoop – mrjob Python Library For MapReduce With Example
Last Updated :
17 Mar, 2021
mrjob is the famous python library for MapReduce developed by YELP. The library helps developers to write MapReduce code using a Python Programming language. Developers can test the MapReduce Python code written with mrjob locally on their system or on the cloud using Amazon EMR(Elastic MapReduce). Amazon EMR is a cloud-based web service provided by Amazon Web Services for Big Data purposes. mrjob is currently an active Framework for MapReduce programming or Hadoop Streaming jobs and has good document support for Hadoop with python than any other library or framework currently available. With mrjob, we can write code for Mapper and Reducer in a single class. In case we don’t have Hadoop installed then also we can test the mrjob program in our local system environment. mrjob supports Python 2.7/3.4+.
Install mrjob in your system
pip install mrjob # for python3 use pip3

So let’s solve one demo problem to understand how to use this library with Hadoop.
Aim: Count the number of occurrence of words from a text file using python mrjob
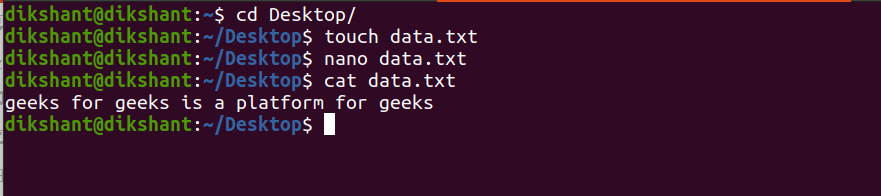
Step 1: Create a text file with the name data.txt and add some content to it.
touch data.txt //used to create file in linux
nano data.txt // nano is a command line editor in linux
cat data.txt // used to see the inner content of file
Step 2: Create a file with the name CountWord.py at the location where your data.txt file is available.
touch CountWord.py // create the python file with name CountWord
Step 3: Add the below code to this python file.
Python3
from mrjob.job import MRJob
class Count(MRJob):
def mapper(self, _, line):
for word in line.split():
yield(word, 1)
def reducer(self, word, counts):
yield(word, sum(counts))
if __name__ == '__main__':
Count.run()
|
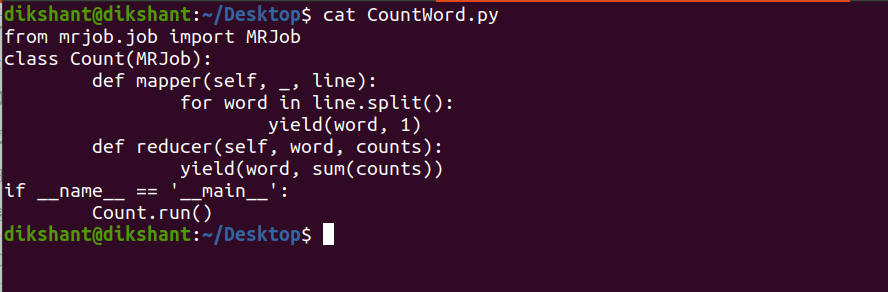
Below is the image Of My CountWord.py file.
Step 4: Run the python File in your local machine as shown below to test it is working fine or not(Note: I am using python3).
python CountWord.py data.txt
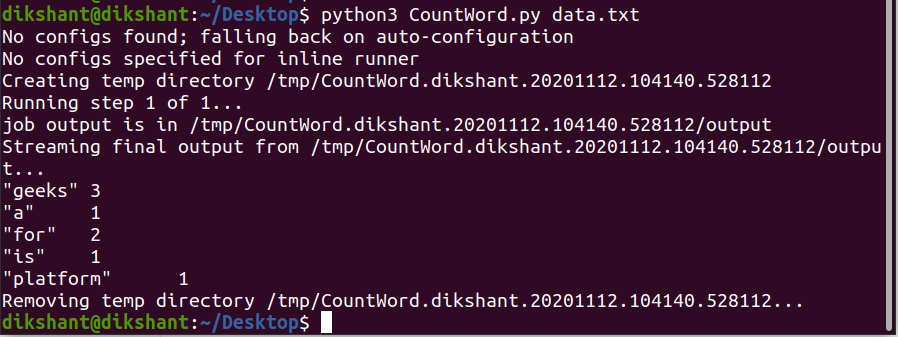
We can observe that it is working fine. By default, mrjob produces the output to the STDOUT i.e. on the terminal.
Now once we have verified that the Mapper and Reducer are working fine. Then we can deploy this code to the Hadoop cluster or Amazon EMR and can use it. When we want to run the mrjob code on Hadoop or Amazon EMR we have to specify the -r/–runner option with the command. The different choices available to run mrjob are explained below.
| Choice |
Description |
| -r inline |
mrjob runs in a single python program(Default Option) |
| -r local |
mrjob runs locally in some subprocess along with some Hadoop features |
| -r hadoop |
mrjob runs on Hadoop |
| -r emr |
mrjob runs on Amazon Elastic MapReduce |
Running mrjob on Hadoop HDFS
Syntax:
python <mrjob-pythonfile> -r hadoop <hdfs-path>
Command:
Send your data.txt to HDFS with the help of the below command (NOTE: I have already sent data.txt to the Countcontent folder on HDFS).
hdfs dfs -put /home/dikshant/Desktop/data.txt /

Run the below command to run mrjob on Hadoop.
python CountWord.py -r hadoop hdfs:///content/data.txt
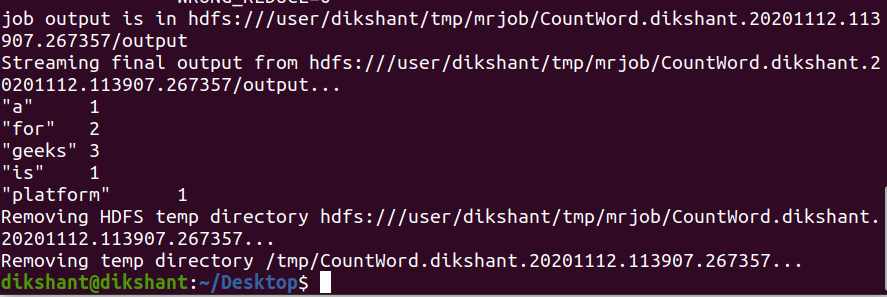
From the above image, we can clearly see that we have successfully executed mrjob on the text file available on our HDFS.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...