Inception-V4 and Inception-ResNets
Last Updated :
07 Feb, 2022
Inception V4 was introduced in combination with Inception-ResNet by the researchers a Google in 2016. The main aim of the paper was to reduce the complexity of Inception V3 model which give the state-of-the-art accuracy on ILSVRC 2015 challenge. This paper also explores the possibility of using residual networks on Inception model. This model
Architectural Changes in Inception-V4:
In the paper there are two types of Inception architectures were discussed.
- Pure Inception architecture (Inception -V4):
- The initial set of layers which the paper refers “stem of the architecture” was modified to make it more uniform . These layers are used before Inception block in the architecture.
- This model can be trained without partition of replicas unlike the previous versions of inceptions which required different replica in order to fit in memory. This architecture use memory optimization on back propagation to reduce the memory requirement.
- Inception architecture with residuals:
- The authors of the paper was inspired by the success of Residual Network. Therefore they explored the possibility of combining the Inception with ResNets. They proposed two Residual Network based Inception models: Inception ResNet V1 and Inception ResNet V2. Let’s look at the key highlights of these architectures.
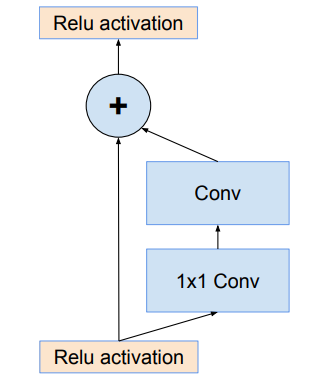
- The Inception block used in these architecture are computationally less expensive than original Inception blocks that we used in Inception V4.
- Each Inception block is followed by a 1×1 convolution without activation called filter expansion. This is done to scale up the dimensionality of filter bank to match the depth of input to next layer.
- The pooling operation inside the Inception blocks were replaced by residual connections. However, pooling operations can be found in reduction blocks.
- In Inception ResNets models, the batch normalization does not used after summations. This is done to reduce the model size to make it trainable on a single GPU.
- Both the Inception architectures have same architectures for Reduction Blocks, but have different stem of the architectures. They also have difference in their hyper parameters for training.
- It is found that Inception-ResNet V1 have similar computational cost as of Inception V3 and Inception-ResNet V2 have similar computational cost as of Inception V4.
Architectures:
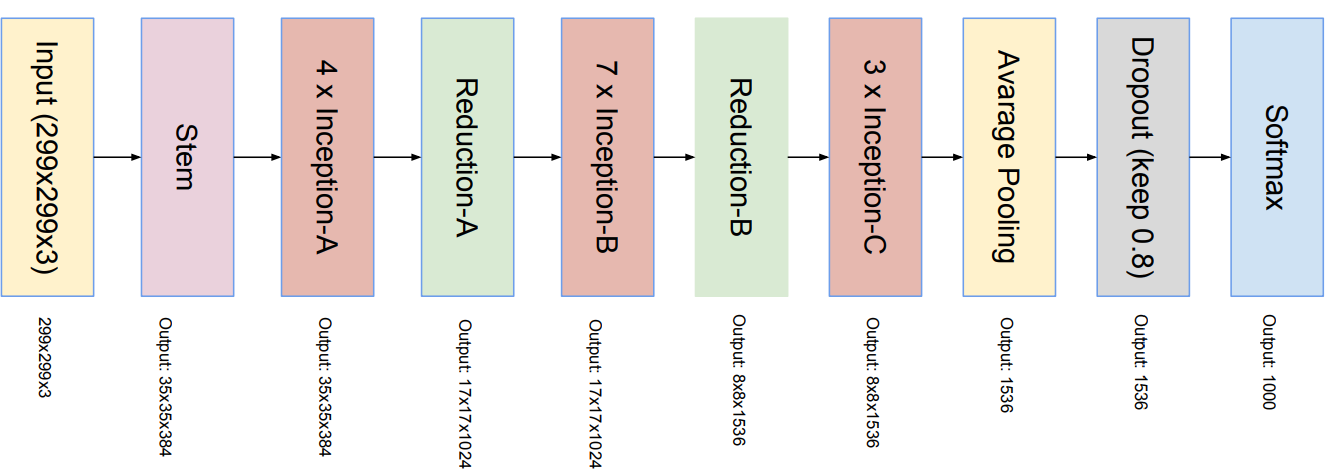
- Below is the architectural details of Inception V4:
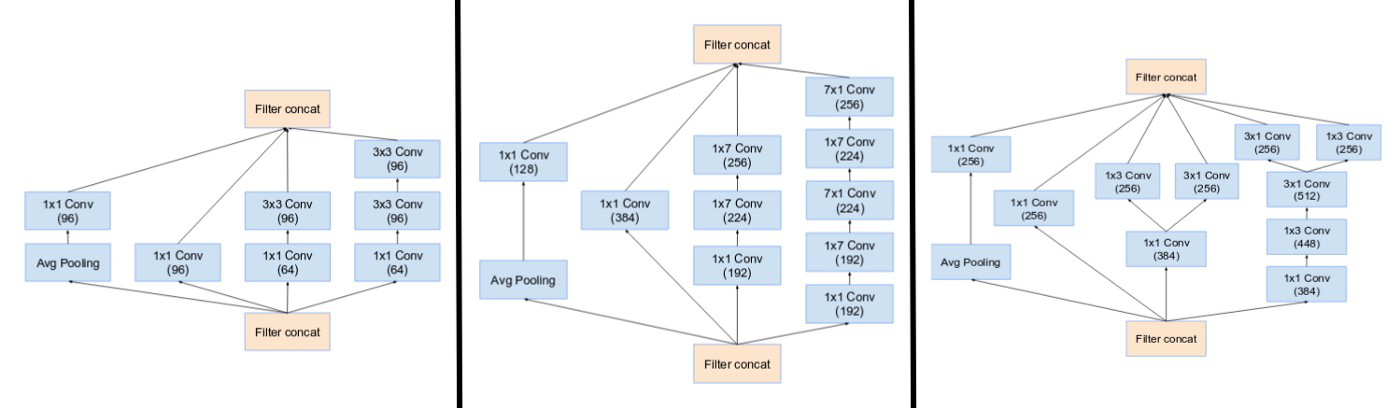
Inception Modules A, B, C of Inception-v4
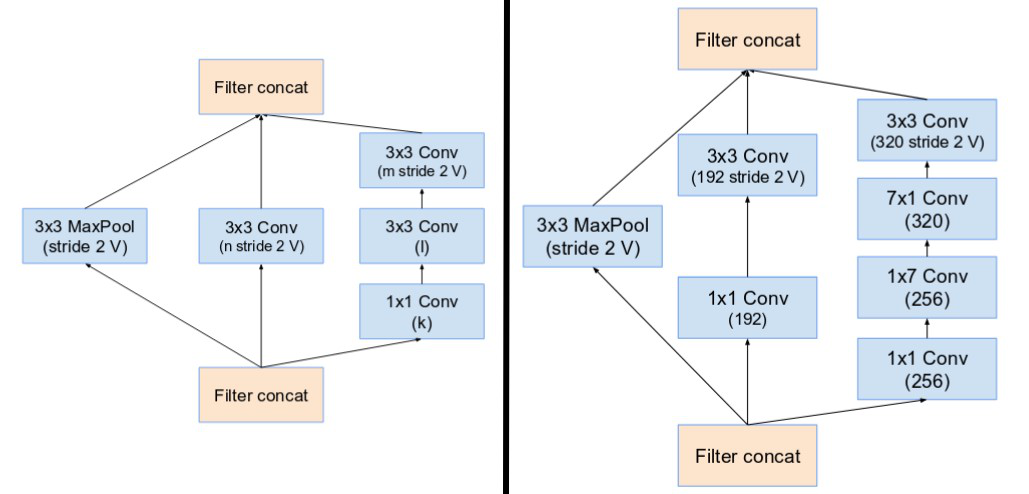
Reduction Blocks A, B of Inception-v4
- Below is the architectural details of Inception ResNet V1 and Inception ResNet V2 :
- Overall Architectures: Inception ResNet V2 has similar architecture schema as of V1 but the difference lies in their stems, Inception and Reduction blocks.
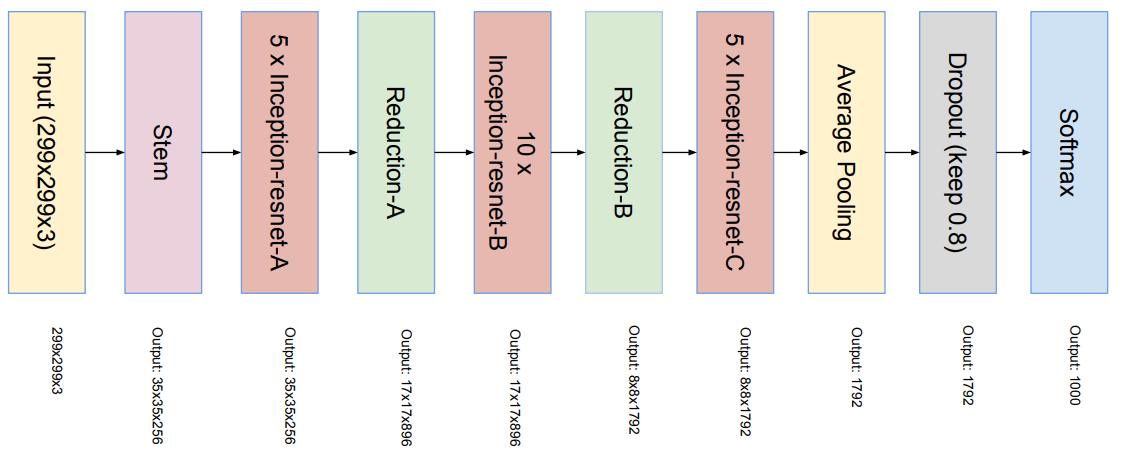
Inception ResNet V1 and Inception ResNet V2
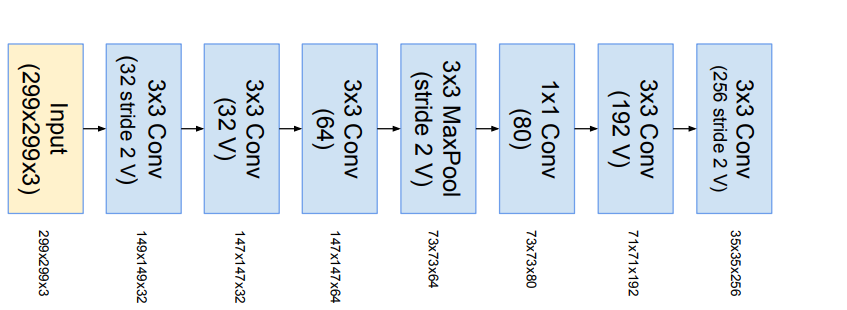
Inception ResNet v1 stem
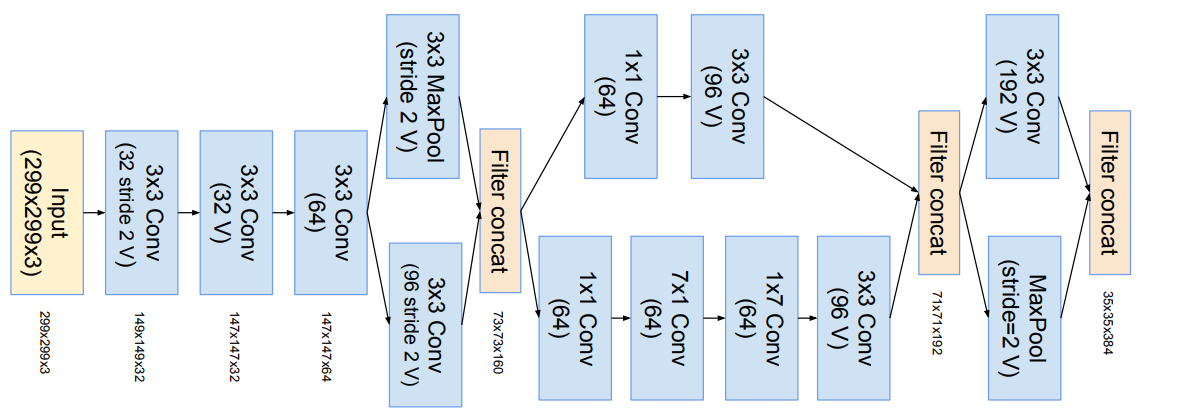
Inception ResNet V2 stem
- Inception Blocks: Inception blocks in Inception ResNets are very similar except for few changes in number of parameters. In Inception ResNet V2 the number of parameters increase in some layers in comparison to Inception ResNet V1.
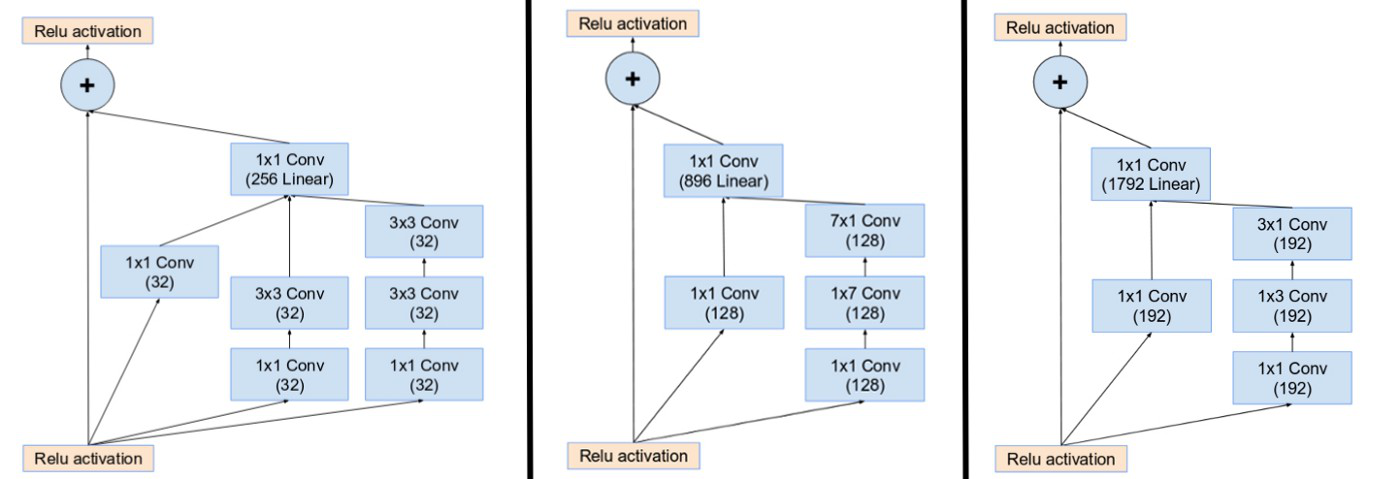
Inception modules A, B, C of Inception ResNet V1
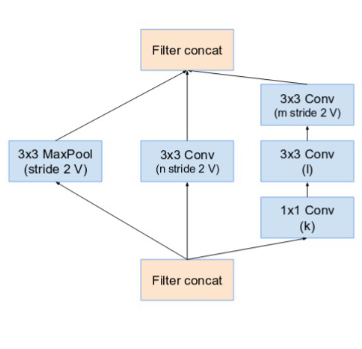
Reduction A schema
- The reduction module A in different Inception architecture is similar. The only difference in number of parameters that are defined by table below:
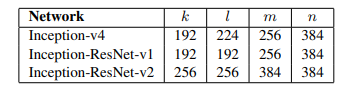
Hyper parameters of Inception-v4
- The Reduction Block B for Inception ResNets are given below:
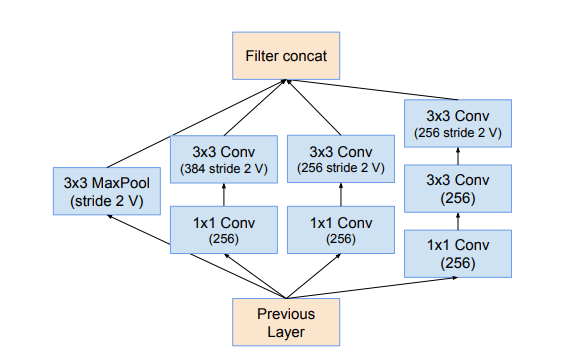
Inception ResNet-v1 Reduction Block B
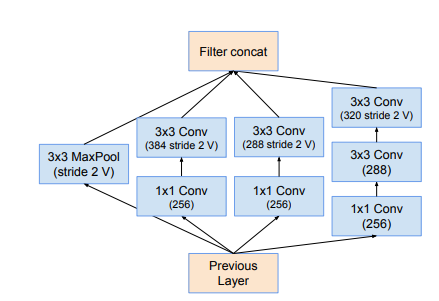
Inception ResNet-v2 Reduction Block B
Results and Conclusion:
The top-5 and top-1 error rate of single-crop single-model evaluation of different architectures on the ILSVRC 2012 validation sets are below:
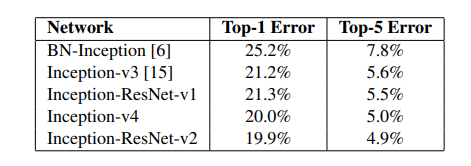
The top-5 and top-1 error rate of 144-crop (single-model) evaluation of different architectures on the ILSVRC 2012 validation sets are below:
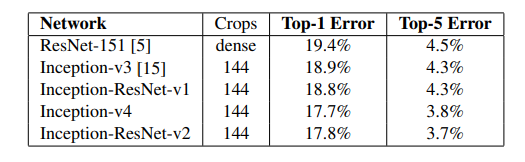
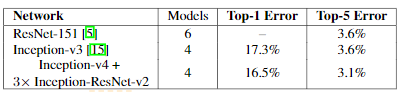
The result on ensemble of different architectures on the ILSVRC 2012 validation sets are below:
Reference:
Share your thoughts in the comments
Please Login to comment...