Since the introduction of the Wav2Vec model, self-supervised learning research in speech has gained momentum. HuBERT is a self-supervised model that allows the BERT model to be applied to audio inputs. Applying a BERT model to a sound input is challenging as sound units have variable length and there can be multiple sound units in each input. In order to apply the BERT model, we need to discretize the audio input. This is achieved through hidden units (Hu), as explained in detail below. Hence the name Hubert. However, before understanding HuBERT, we must get a basic understanding of BERT, as HuBERT is based on it.
What is BERT?
BERT is a shorthand for Bidirectional Encoder Representations from Transformers. In order to understand BERT, one should be aware of the Transformer architecture and its self-attention mechanism. The BERT implementation is based on the encoder block of the Transformer architecture. It receives the entire sequence at once and is able to learn the context.
BERT is a state-of-the-art natural language processing (NLP) model introduced by Google AI in 2018. It revolutionized NLP tasks by pre-training a deep neural network on massive amounts of text data. BERT is a transformer-based model that learns contextualized word embeddings by training on large corpora of text from the internet. Unlike earlier models that used unidirectional context (either left-to-right or right-to-left), BERT employs a bidirectional approach. This means it looks at both the left and right context of a word simultaneously, enabling it to capture richer contextual information.
After pre-training on a vast amount of text, BERT can be fine-tuned for specific NLP tasks such as text classification, question-answering, and sentiment analysis. It has set the standard for many NLP benchmarks, and its ability to understand context and semantics has made it widely adopted in various NLP applications.
BERT is trained using two mechanisms –
- Masked Language Modeling– Here a certain percentage of input is masked and the model is trained to predict the masked value.
- Next Sentence Prediction – Here the model is given 2 sentences and the model is trained to learn if one follows the other or not.
Now to apply MLM to speech, the input must be discretized. This is where the idea of hidden units comes in. An offline clustering step is used to generate TARGET labels. The BERT model consumes the masked speech features to predict the target labels generated by the clustering step. This unique approach to training makes BERT different from Wav2Vec. This is explained in detail below.
Wav2Vec2
The architecture of HuBERT is very similar to Wav2Vec2. However, it is the training process which is very different. Lets have a brief understanding of Wav2Vec2 model.
Wav2Vec2 is a deep learning model designed for automatic speech recognition (ASR). It was developed by Facebook AI Research and introduced in 2020. Wav2Vec2 is a significant advancement in ASR technology. It builds on the original Wav2Vec model and leverages the power of transformers, with a training objective similar to BERT’s masked language modeling objective, but adapted for speech. These four important elements in Wav2Vec2 are: the feature encoder, context network, quantization module, and contrastive loss (pre-training objective).
Wav2Vec2 operates in a two-step process: pre-training and fine-tuning. During pre-training, it learns to predict the context of waveform samples from a large dataset of multilingual and multitask supervised data. The pre-training includes both learning to align the audio with text transcriptions and learning contextualized representations of audio. This allows it to capture phonetic and linguistic features from the audio.
After pre-training, Wav2Vec2 can be fine-tuned for specific ASR tasks. It has shown impressive results on various ASR benchmarks, reducing the need for extensive amounts of transcribed data, which was traditionally required for ASR systems. Wav2Vec2 has had a significant impact on the development of more accurate and efficient speech recognition models.
HuBERT ARCHITECTURE
The HuBERT model consists of :
- Convolution encoder – The encoder consists of 7 layer convolutional feature encoder which takes input raw audio X and outputs latent speech representations z1, . . . , zT for T time-steps with 512 channels at each step. The job of encoder is to reduce the dimensionality of the input data. A typical feature encoder which was introduced in Wav2Vec2 model and is also used in HuBERT contains seven blocks and temporal convolutions in each block have 512 channels with strides (5,2,2,2,2,2,2) and kernel widths (10,3,3,3,3,2,2). This results in an encoder output frequency of 49 hz with a stride of about 20ms between each sample, and a receptive field of 400 input samples or 25ms of audio. The down-sampling factor is 320x. The audio encoded features are ten randomly maksed.
- BERT encoder -The core of HuBERT architecture is the BERT encoder which takes the feature vectors from convolution encoder to produce hidden unit representations. Input sequence first needs to go through a feature projection layer to increase the dimension from 512 (output of the CNN) to 768 for BASE , 1024 for LARGE and 1280 for X-Large. It then moves through multilayer multi-head attention. For the base we have 12 layer 8 head , for the Large 24 layer 16 head , for X-large 48 layer 8 head attention blocks .The output of final attention layer is passed through a FFN layer to expand its dimension by a factor of 4. Thus the final output of encoder block becomes 3072 for base, 4096 for Large and 5120 for X large.
- A projection layer – It is a linear layer which is used to transform the output of BERT encoder to match the embedding dimension of the clustering step . The dimension are 256 ,768 and 1024 for Base, Large and X-Large respectively. Cosine similarity is calculated between the transformer outputs (after dimension reduction through the projection) and every hidden unit embedding (output of the clustering step), to derive prediction logits. Subsequently, a cross-entropy loss function is employed to penalize incorrect predictions.
- Code Embedding Layer – It is used to convert the output of clustering step (hidden unit) to its embedding vector (hidden unit embeddings). The dimension are 256 ,768 and 1024 for Base, Large and X-Large respectively.
- CTC layer – During the ASR fine tuning the projection layer is removed and replaced with a softmax layer. CTC (Connectionist temporal classification) loss is used for ASR fine tuning.
- Clustering Layer – A k means clustering layer is used to generate hidden units. In its first iteration it takes MFCC feature as its input and in subsequent step it takes input from the transformer layer. More details in the training section.
How all this component interact during pre-training and fine-tuning is explained in detail in the training section.
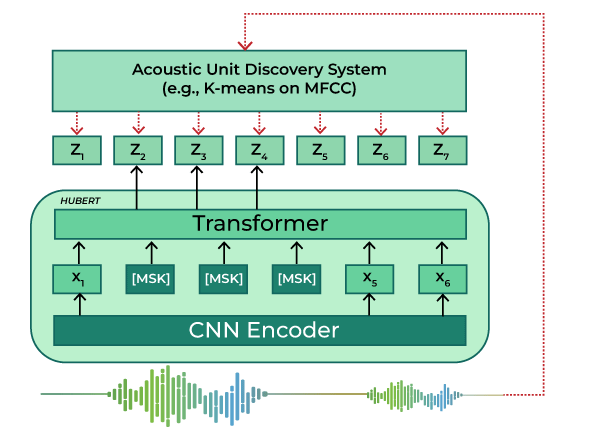
HuBERT Model Architecture
Training Phase
The training is divided into two parts – Pre Training and Fine Tuning.
- Pre-Training – The objective of pre-training step is to learn the hidden unit representation. It is done for 2 iterations for the ‘Base model’ and 1 iteration for the ‘Large’ and ‘X-Large’ models. Since the training of ‘Large’ and ‘X-Large’ takes input from the ‘Base model’ it is practically seen as 3 iterations.
- Fine Tuning– Here the model is fine-tuned for the ASR task.
- The input audio wave is converted to 39-dimensional MFCC (Mel-Frequency Cepstral Coefficients) features.
- K-means clustering with 100 clusters is run on these inputs. Each segment of the audio is assigned to one of the k clusters. These clusters becomes hidden unit. Each hidden unit is mapped to a embedding vector. These acts as TARGETS to be predicted by the BERT model in step 3.
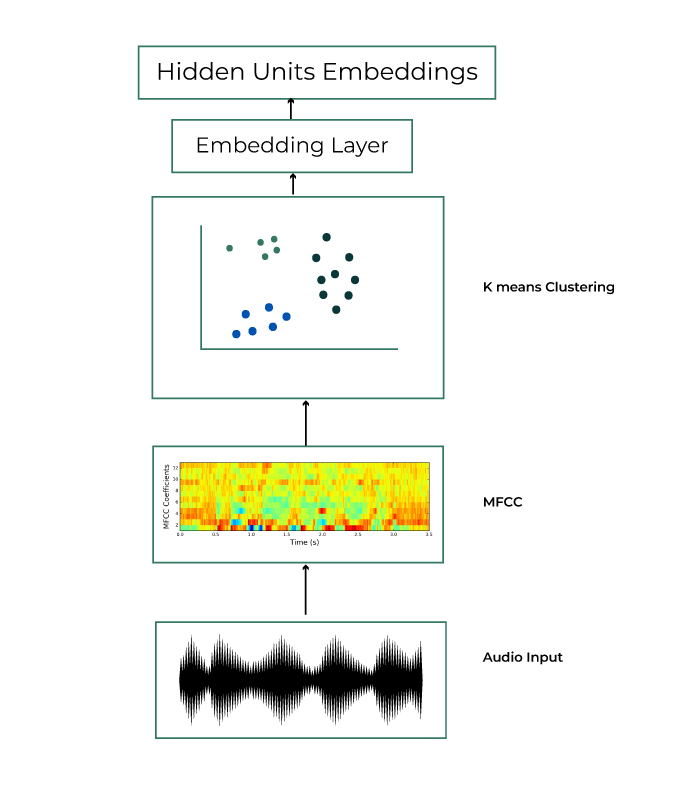
Pre -Training Iteration 1 Clustering
- The raw audio input is passed through the convolution layer ( composed of seven 512 channel layers ) . Certain outputs of the convolution layer are masked and then fed into the BERT encoder. The objective of BERT encoder is to predict the masked representations for each input that should match with the hidden unit obtained in step 2. Since the output of BERT encoder is of higher dimension as compared to the embedding dimension a projection layer is used to transform the output of BERT. Here cross-entropy loss is used for wrong prediction.

Pretraining Iteration Masked Language Modeling
- Above is first iteration of the model training. In second iteration for the clustering steps instead of taking the MFCC features, output form an intermediate layer (6th layer for the ‘BASE’) of the BERT encoder from the previous iteration step is used.
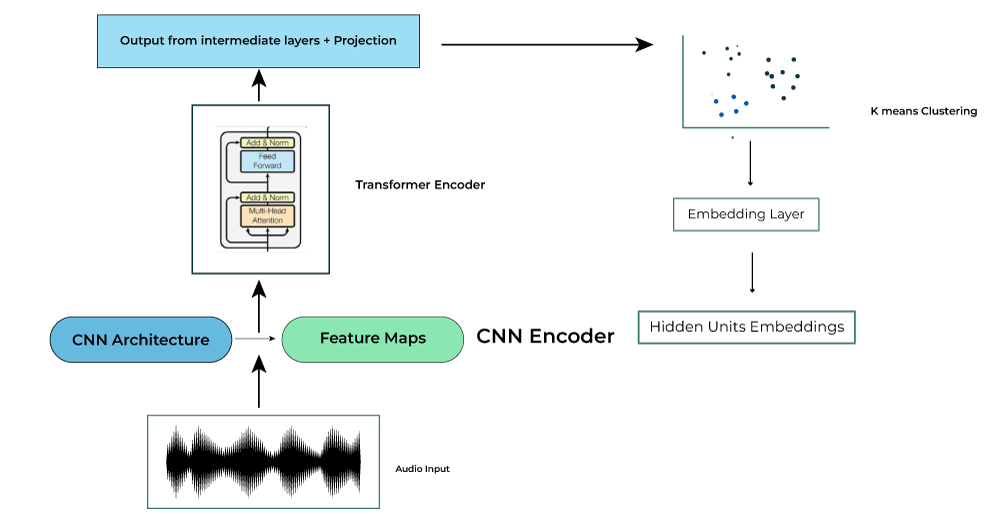
Pre -Training Iteration 2 Clustering
- Step 2-4 are referred as ‘pre-training’ where the model learns meaningful high level representations. This step is done for 2 iteration for the ‘Base’ model. The ‘Large’ and ‘X-Large model’ is trained for one iteration. Instead of restarting the iterative process of clustering MFCC features, features from the 9-th transformer layer of the second iteration BASE HuBERT is used for clustering and training of these two models.
- Fine Tuning – After the pre-training CTC loss is used for ASR fine tuning. The projection layer is replaced with a randomly initialized softmax layer. CTC target vocabulary includes 26 English characters, a space token, an apostrophe, and a special CTC blank symbol.
Implementing Automatic Speech Recognition
Below is the python code for ASR inference using the Hugging Face transformers library.
Before starting with the implementation, we need to install librosa , torch and transformers library.
!pip install librosa
!pip install torch
!pip install transformers
Let’s import the installed libraries.
- Librosa is a python package for analyzing and processing audio signal
- Torch is an open source ml framework that provides flexible an efficient platform for building and training deep neural networks
- HubertForCTC is specifically designed for training and using HuBERT model speech-related tasks
- AutoProcessor is tailored library for preprocessing audio.
Python3
import librosa
import torch
from transformers import HubertForCTC, AutoProcessor
|
Define the path to the audio file, that we want to transcribe. The audio file can be downloaded from here.
Python3
AUDIO_FILE = 'harvard.wav'
|
In the next step, we have initialized a AutoProcessor to process the audio data and align it with the model. We have also initialized HubertForCTC model for automatic speech recognition tasks and transcribe the audio.
Python3
processor = AutoProcessor.from_pretrained("facebook/hubert-large-ls960-ft")
model = HubertForCTC.from_pretrained("facebook/hubert-large-ls960-ft")
|
Now, using Librosa library , we loaded the specified audio file. It returns speech, which contains the audio waveform and sampling rate.
Then, using AutoProcessor, we preprocessed the audio. It convert the waveform into a format that can be fed into the model.
The torch.no_grad() section indicates the operations should not be included in gradient computation, which is useful when you don’t need to update model weights.
Then, we pass the processed audio data through the HuBERT model to obtain the logits. The logits are unnormalized predictions from the model. After this, we calculate predicted IDs by taking the argmax along the last dimension of the logits.
Python3
speech, rate = librosa.load(AUDIO_FILE, sr=16000)
inputs = processor(speech, return_tensors="pt", sampling_rate=rate).input_values
with torch.no_grad():
logits = model(inputs).logits
predicted_ids = torch.argmax(logits, dim=-1)
|
We have used batch_decode method to convert the predicted token IDs into a human readable transcript.
Python3
transcription = processor.batch_decode(predicted_ids)
print(transcription)
|
Output:
['THE STALE SMELL OF OLD BEER LINGERS IT TAKES HEAT TO BRING OUT THE ODOR A COLD DIP RESTORES HEALTH AND ZEST A SALT PICKLE TASTES FINE WITH HAM TACOS AL PASTOR ARE MY FAVORITE A ZESTFUL FOOD IS THE HOT CROSS BUN']
CONCLUSION
HuBERT has demonstrated state of the art performance on servers ASR benchmark. HuBERT model employs a pre training phase where it learns to predict context followed by fine tuning for specific ASR task. This two step process allows it to capture phonetic features and helps in transfer learning making it efficient. HuBERT model can be used for wide range of applications like ASR, Speech generation, language recognition, emotion recognition. The performance of HuBERT model is highly sensitive to the clustering quality. The researcher has to experiment with different clustering configuration to get improvement in performance. In future the researcher plan to improve the HuBERT training procedure to consist of a single phase. In this article, we have discussed briefly about the BERT model and Architecture of HuBERT model. Along with the hands on implementation of HuBERT model for Automatic Speech Recognition.
Share your thoughts in the comments
Please Login to comment...