In recent years, front-end development has taken a massive leap. The rise of frameworks and libraries has transformed the way developers approach problems and create exquisite user experiences. All this makes it essential to write good code in order to make the application more modular, scalable, and testable. This can be achieved by implementing the concepts of clean frontend architecture.
In this article, we will discuss what a clean frontend architecture is, why it is needed, and its advantages and disadvantages.
What is a Clean Frontend Architecture?
A clean frontend architecture is concerned with the separation of concerns. Your frontend application should be designed in such a way that it is highly understandable, maintainable, scalable, flexible, and easily testable. This is a widely known approach for building robust applications.
A clean architecture in frontend development can consist of several patterns and principles, such as the term “Clean Architecture,” coined by Robert C. Martin, and SOLID principles that can be applied to any frontend library or framework such as React, Angular, and Vue. We will look at the above principles in this article.
Why Do We Need a Clean Frontend Architecture?
We need a clean frontend architecture for the following reasons:
- Separation of responsibilities and functionalities
- Increase maintainability
- Increase testability
Clean Frontend Architecture
Now, we will discuss the concepts around a clean front-end architecture. Since “Clean Architecture” is derived from SOLID principles, we will discuss SOLID principles first.
What are “SOLID Principles”?
SOLID is a popular acronym in software engineering that consists of five principles that make an application more maintainable, flexible, and understandable. SOLID principles were introduced for Object Oriented Programming, but they can be applied to other programming paradigms. Therefore, we will try to apply them in React.
1. S —Single Responsibility Principle
The Single Responsibility Principle says that “each class/component/function should do only one thing.” Each function should be able to perform a specific task, rather than a bunch of tasks. This helps in writing clean and modular code that is readable and less prone to errors.
For instance, refer to the code below.
Javascript
export default function App() {
const [courses, setCourses] = useState([]);
useEffect(() => {
}, [])
return (
<div>
<h1>Courses</h1>
{
!!courses ? (
) : (
<p>Oops! There are no courses.</p>
)
}
</div>
);
}
|
In the above code, a couple of things are happening.
- A list of courses is being fetched from the server.
- Courses are being displayed on the page based on conditional rendering.
If you notice, our component does more than one thing, which is not desirable as this approach would not make our code modular.
Instead, we can divide the component into two components.
- A custom hook that only fetches the list of courses from the server and returns the response.
- A presentational component that doesn’t care about the logical part and displays the courses on the page.
This way, we can use the custom hook and fetch the courses wherever we want to.
2. O — Open-Closed Principle
The Open-Closed Principle states that “entities such as classes, modules, or functions should be closed for modification but should be open for extension.” This means that developers should be able to extend the functionality or features of a component without altering the source code.
In React, this is achievable by using props and composition. Composition simply means passing components to other components as props.
In the code below, we use the concept of composition in React to extend the functionality of the code by creating three separate components to display a user name.
Javascript
const DisplayUserName = ({ text }) => {
return <div>{text}</div>;
};
const DisplayText = ({ userName }) => {
return <h2>Welcome back, {userName}!</h2>;
};
export default function App() {
const userName = "John Doe";
return (
<div className="App">
<DisplayUserName text={<DisplayText userName={userName} />} />
</div>
);
}
|
Here, if we need to change the message on the “DisplayText” component, we can extend “DisplayText” without altering the “DisplayUserName” component.
3. L — Liskov Substitution Principle
The Liskov Substitution Principle says that a subclass should be able to be substituted for its parent class without changing the behaviour of the program. What does this mean in React?
This means that the parent components should be able to be replaced with their child components without having an effect on the behaviour of the application.
The below code shows the parent component “Link” and the child component “AlternateLink”.
Javascript
const Link = (props) => {
return <a href={props.link}>{props.text}</a>;
};
const AlternateLink = (props) => {
return <Link link={props.link} text={props.text} />;
};
export default function App() {
return (
<div style={{ display: "flex", flexDirection: "column" }}>
</div>
);
}
|
We can use the “AlternateLink” component in place of “Link” without affecting the behaviour of the code.
4. I — Interface Segregation Principle
The Interface Segregation Principle states that modules or classes should not be forced to rely upon interfaces that they don’t use. In React, this can be closely related to the components, in the sense that we should pass only the required props to the components and nothing unnecessary.
For example, here we have a component that displays the name of a product.
Javascript
const DisplayProductName = (props) => {
return (
<div>
<p>Name of the product: {props.product.name} </p>
</div>
)
};
|
Suppose we pass the below “product” object inside the “DisplayProductName” component.
Javascript
const product = {
name: "Apple iPhone 15",
type: "phone",
price: 79990,
specs: {
rom: 128,
romUnit: "GB",
processor: "A16 Bionic Chip"
}
}
|
This code works fine, but this is a bad practice, as the “DisplayProductName” component should not know what “product” is. It should only deal with the name of the product and just display it!
Because if we want to modify our “product” object to something like this:
Javascript
const product = {
details: {
name: "Apple iPhone 15",
},
type: "phone",
price: 79990,
specs: {
rom: 128,
romUnit: "GB",
processor: "A16 Bionic Chip"
}
}
|
Then the “DisplayProductName” component would not be able to display anything as “props.product.name” is undefined. Instead, we should only pass what the component actually needs.
Javascript
const DisplayProductName = ({ name }) => {
return (
<div>
<p>Name of the product: {name} </p>
</div>
)
};
|
Now, we can simply pass the name of the product as props.
Javascript
<DisplayProductName name={product.details.name} />
|
By hiding the implementation details from the “DisplayProductName” component, we ensure that the code doesn’t produce unexpected results.
5. D — Dependency Inversion Principle
The Dependency Inversion Principle states that high-level code modules should depend on abstractions rather than concrete implementation details. For React, this would mean that the components should not know how specific tasks are being performed. In other words, components should not be tightly coupled.
This will result in more modular and testable code.
For example, we have created a form that has a name input field, and our objective is to either save the name in our database or update the name if it already exists.
Javascript
const FormToCreate = () => {
const createName = () => {
};
return <Form submitFunction={createName} />;
};
const FormToUpdate = () => {
const updateName = () => {
};
return <Form submitFunction={updateName} />;
};
const Form = (submitFunction) => {
const [name, setName] = useState("");
const handleSubmit = (e) => {
e.preventDefault();
submitFunction();
};
return (
<form onSubmit={handleSubmit}>
<input
type="text"
placeholder="Enter name of the user"
value={name}
onChange={(e) => setName(e.target.value)}
/>
<button type="submit">Submit</button>
</form>
);
};
export default function App() {
return (
<div style={{ display: "flex", flexDirection: "column" }}>
<FormToCreate />
<FormToUpdate />
</div>
);
}
|
We have created a separate component for our HTML form as our logic for saving and updating/editing the form is different. Moreover, the form should not depend on the logic, so we have separated logic into its own components.
This resulted in the removal of tight coupling between the components.
What is Clean Architecture?
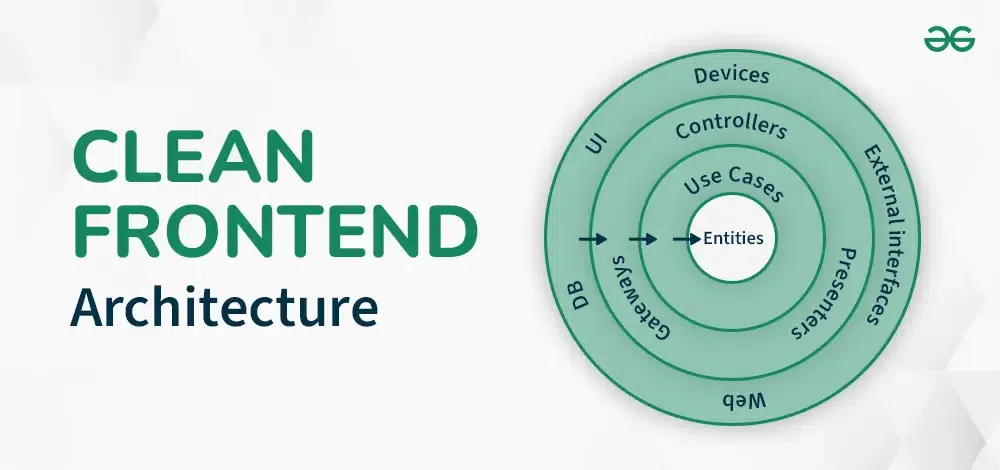
“Clean Architecture” is a type of software architecture that focuses on the separation of concerns, thereby increasing the maintainability and testability of an application. This architecture separates an application into multiple layers by depicting each of the layers as a concentric circle.
This architecture follows a rule called the Dependency Rule that states that the flow between the layers should move towards the inner circle. This, in turn, means that the inner circle should not be bothered by what happens in the outer circle. By using this rule, the outer circle won’t have any effect on the inner circles.
The original architecture lists about 4 layers.
1. Domain Layer
- This is the innermost layer, consisting of entities or any objects/functions/code which can transform the data. The entities should not change if we move from one framework to another.
- The entities should not be affected by some external change. For instance, a function that adds a user to a “users” table should not know how it is being added. It only deals with accepting the new user and returning the updated “users” table with the newly added user.
2. Application Layer
- This layer deals with the use cases or user scenarios of the application. It is responsible for containing the business logic or all the functionality present in the application. The use cases are application-specific and should not depend on UI, external systems, or any framework.
- For example, in a use case where we need to search for a book, it would deal with finding the book in the database, applying some filters, and returning the searched book as a result. This use case can interact with entities like books and categories.
3. Adapter Layer
- This layer is responsible for converting data from use cases into a desired format that can be stored in external sources, such as a database.
- This layer contains three things:
- Controllers: Handle input from external sources and hold references to use cases
- Presenters: Responsible for implementing the interface by taking data from the use cases
- Gateways: Interfaces that enable the application to interact with databases, services, or frameworks
4. Infrastructure Layer
- This layer contains frameworks and tools like the database, external interfaces (any library for authentication), UI components, the web (network requests), and any devices such as printers or scanners. The core business logic is kept isolated from this layer.
- For instance, code in this layer can connect to a SQL database, send HTTP requests to a web service, or manage routes.
Advantages of Clean Frontend Architecture
Below, we discuss some of the advantages a clean frontend architecture provides.
- Separation of concerns: Having separation of concerns makes it easier to comprehend the code structure as everything is divided into its own layers, making them lightly coupled with each other.
- Modularity: Dividing the code in such a way that each function/class/component does only one thing makes the code pretty easy to read and maintain. Moreover, if anything fails, it would be easier to find where the cause of the failure lies.
- Maintainability: Separating the concerns along with breaking down the code into smaller chunks increases the maintainability of the whole application, thereby making it easier to read.
- Testability: If the functionalities in the code are decoupled from each other, it makes it easier to test the application. When it comes to the layers, it is possible for us to test each layer independently.
- Improved collaboration: By implementing a set of guidelines and real-world programming principles, the code can be standardized, which can make collaborating on an application easier.
- Scalability: Separating different functionalities and isolating components gives a lot of opportunities to add more functionalities, thereby scaling the application to a whole new level. This can also improve collaboration between the team members, as they can work on the application independently.
Disadvantages of Clean Frontend Architecture
Although there are numerous benefits that we get from applying a clean frontend architecture, it can also have multiple disadvantages.
- Difficult to onboard: It is essential to have a good understanding of the various principles involved in creating a clean frontend architecture, but that requires a learning curve. That can be time consuming and hence, it can be detrimental to the project if the development time is slower than what is required.
- Increased codebase size: Making the application more modular can lead to dividing the modules into their own files and folders, resulting in a large codebase. This may introduce more complexity than is necessary.
- Maybe overkill for small applications: If a lot of principles or highly modular architecture is introduced in a relatively smaller or less complex codebase, it can cause complexity issues unnecessarily. This is a common result of over-engineering.
Conclusion
Implementing a clean frontend architecture in our application can do wonders if applied correctly. It can make our application more readable, testable, scalable, and maintainable. In this article, we discussed what a clean frontend architecture is, the different principles that we should know, and the pros and cons of having a clean frontend architecture.
Make sure that you understand the requirements of the application and do not over-engineer things or force your application to have a clean frontend architecture, as it can bring a lot of new issues if not applied correctly.
Share your thoughts in the comments
Please Login to comment...