Biggest Reuleaux Triangle within A Square
Last Updated :
02 Dec, 2022
Given an integer a which is the side of a square, the task is to find the biggest Reuleaux Triangle that can be inscribed within it.
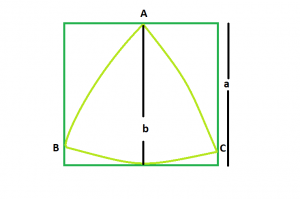
Examples:
Input: a = 6
Output: 25.3717
Input: a = 8
Output: 45.1053
Approach: We know that the Area of Reuleaux Triangle is 0.70477 * b2 where b is the distance between the parallel lines supporting the Reuleaux Triangle.
From the figure, it is clear that distance between parallel lines supporting the Reuleaux Triangle = Side of the square i.e. a
So, Area of the Reuleaux Triangle, A = 0.70477 * a2
Below is the implementation of the above approach:
C++
#include <bits/stdc++.h>
using namespace std;
float ReuleauxArea(float a)
{
if (a < 0)
return -1;
float A = 0.70477 * pow(a, 2);
return A;
}
int main()
{
float a = 6;
cout << ReuleauxArea(a) << endl;
return 0;
}
|
Java
import java.lang.Math;
class cfg
{
static double ReuleauxArea(double a)
{
if (a < 0)
return -1;
double A = 0.70477 * Math.pow(a, 2);
return A;
}
public static void main(String[] args)
{
double a= 6;
System.out.println(ReuleauxArea(a) );
}
}
|
Python3
def ReuleauxArea(a) :
if (a < 0) :
return -1
A = 0.70477 * pow(a, 2);
return A
if __name__ == "__main__" :
a = 6
print(ReuleauxArea(a))
|
C#
using System;
class GFG {
static double reuleauxArea(double a)
{
if (a<0)
return -1;
double A=0.70477*Math.Pow(a,2);
return A;
}
static public void Main()
{
double a= 6;
Console.WriteLine(reuleauxArea( a));
}
}
|
PHP
<?php
function ReuleauxArea($a)
{
if ($a < 0)
return -1;
$A = 0.70477 * pow($a, 2);
return $A;
}
$a = 6;
echo ReuleauxArea($a) . "\n";
?>
|
Javascript
<script>
function ReuleauxArea(a)
{
if (a < 0)
return -1;
var A = 0.70477 * Math.pow(a, 2);
return A;
}
var a= 6;
document.write(ReuleauxArea(a) );
</script>
|
Time Complexity: O(1)
Auxiliary Space: O(1)
Share your thoughts in the comments
Please Login to comment...