Apache HBase
Last Updated :
11 May, 2023
Prerequisite – Introduction to Hadoop
HBase is a data model that is similar to Google’s big table. It is an open source, distributed database developed by Apache software foundation written in Java. HBase is an essential part of our Hadoop ecosystem. HBase runs on top of HDFS (Hadoop Distributed File System). It can store massive amounts of data from terabytes to petabytes. It is column oriented and horizontally scalable.
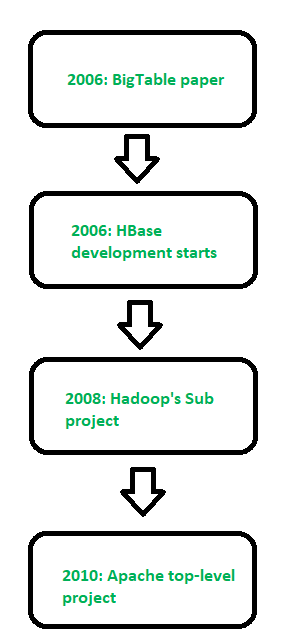
Figure – History of HBase
Applications of Apache HBase:
Real-time analytics: HBase is an excellent choice for real-time analytics applications that require low-latency data access. It provides fast read and write performance and can handle large amounts of data, making it suitable for real-time data analysis.
Social media applications: HBase is an ideal database for social media applications that require high scalability and performance. It can handle the large volume of data generated by social media platforms and provide real-time analytics capabilities.
IoT applications: HBase can be used for Internet of Things (IoT) applications that require storing and processing large volumes of sensor data. HBase’s scalable architecture and fast write performance make it a suitable choice for IoT applications that require low-latency data processing.
Online transaction processing: HBase can be used as an online transaction processing (OLTP) database, providing high availability, consistency, and low-latency data access. HBase’s distributed architecture and automatic failover capabilities make it a good fit for OLTP applications that require high availability.
Ad serving and clickstream analysis: HBase can be used to store and process large volumes of clickstream data for ad serving and clickstream analysis. HBase’s column-oriented data storage and indexing capabilities make it a good fit for these types of applications.
Features of HBase –
- It is linearly scalable across various nodes as well as modularly scalable, as it divided across various nodes.
- HBase provides consistent read and writes.
- It provides atomic read and write means during one read or write process, all other processes are prevented from performing any read or write operations.
- It provides easy to use Java API for client access.
- It supports Thrift and REST API for non-Java front ends which supports XML, Protobuf and binary data encoding options.
- It supports a Block Cache and Bloom Filters for real-time queries and for high volume query optimization.
- HBase provides automatic failure support between Region Servers.
- It support for exporting metrics with the Hadoop metrics subsystem to files.
- It doesn’t enforce relationship within your data.
- It is a platform for storing and retrieving data with random access.
Facebook Messenger Platform was using Apache Cassandra but it shifted from Apache Cassandra to HBase in November 2010. Facebook was trying to build a scalable and robust infrastructure to handle set of services like messages, email, chat and SMS into a real time conversation so that’s why HBase is best suited for that.
RDBMS Vs HBase –
- RDBMS is mostly Row Oriented whereas HBase is Column Oriented.
- RDBMS has fixed schema but in HBase we can scale or add columns in run time also.
- RDBMS is good for structured data whereas HBase is good for semi-structured data.
- RDBMS is optimized for joins but HBase is not optimized for joins.
Apache HBase is a NoSQL, column-oriented database that is built on top of the Hadoop ecosystem. It is designed to provide low-latency, high-throughput access to large-scale, distributed datasets. Here are some of the advantages and disadvantages of using HBase:
Advantages Of Apache HBase:
- Scalability: HBase can handle extremely large datasets that can be distributed across a cluster of machines. It is designed to scale horizontally by adding more nodes to the cluster, which allows it to handle increasingly larger amounts of data.
- High-performance: HBase is optimized for low-latency, high-throughput access to data. It uses a distributed architecture that allows it to process large amounts of data in parallel, which can result in faster query response times.
- Flexible data model: HBase’s column-oriented data model allows for flexible schema design and supports sparse datasets. This can make it easier to work with data that has a variable or evolving schema.
- Fault tolerance: HBase is designed to be fault-tolerant by replicating data across multiple nodes in the cluster. This helps ensure that data is not lost in the event of a hardware or network failure.
Disadvantages Of Apache HBase:
- Complexity: HBase can be complex to set up and manage. It requires knowledge of the Hadoop ecosystem and distributed systems concepts, which can be a steep learning curve for some users.
- Limited query language: HBase’s query language, HBase Shell, is not as feature-rich as SQL. This can make it difficult to perform complex queries and analyses.
- No support for transactions: HBase does not support transactions, which can make it difficult to maintain data consistency in some use cases.
- Not suitable for all use cases: HBase is best suited for use cases where high throughput and low-latency access to large datasets is required. It may not be the best choice for applications that require real-time processing or strong consistency guarantees
Share your thoughts in the comments
Please Login to comment...