Architecture of HBase
Last Updated :
25 Apr, 2023
Prerequisites –
Introduction to Hadoop, Apache HBase
HBase architecture has 3 main components: HMaster, Region Server, Zookeeper.
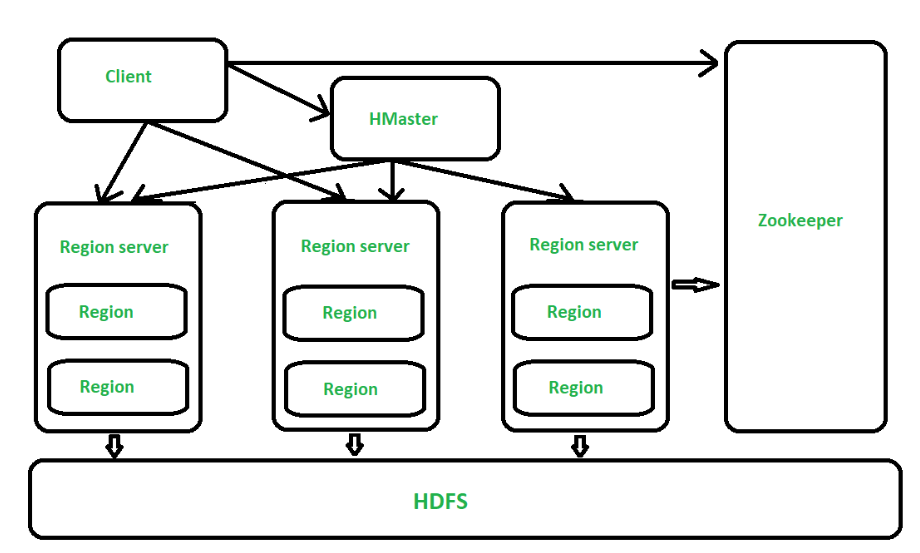
Figure – Architecture of HBase
All the 3 components are described below:
- HMaster –
The implementation of Master Server in HBase is HMaster. It is a process in which regions are assigned to region server as well as DDL (create, delete table) operations. It monitor all Region Server instances present in the cluster. In a distributed environment, Master runs several background threads. HMaster has many features like controlling load balancing, failover etc.
- Region Server –
HBase Tables are divided horizontally by row key range into Regions. Regions are the basic building elements of HBase cluster that consists of the distribution of tables and are comprised of Column families. Region Server runs on HDFS DataNode which is present in Hadoop cluster. Regions of Region Server are responsible for several things, like handling, managing, executing as well as reads and writes HBase operations on that set of regions. The default size of a region is 256 MB.
- Zookeeper –
It is like a coordinator in HBase. It provides services like maintaining configuration information, naming, providing distributed synchronization, server failure notification etc. Clients communicate with region servers via zookeeper.
Advantages of HBase –
- Can store large data sets
- Database can be shared
- Cost-effective from gigabytes to petabytes
- High availability through failover and replication
Disadvantages of HBase –
- No support SQL structure
- No transaction support
- Sorted only on key
- Memory issues on the cluster
Comparison between HBase and HDFS:
- HBase provides low latency access while HDFS provides high latency operations.
- HBase supports random read and writes while HDFS supports Write once Read Many times.
- HBase is accessed through shell commands, Java API, REST, Avro or Thrift API while HDFS is accessed through MapReduce jobs.
Features of HBase architecture :
Distributed and Scalable: HBase is designed to be distributed and scalable, which means it can handle large datasets and can scale out horizontally by adding more nodes to the cluster.
Column-oriented Storage: HBase stores data in a column-oriented manner, which means data is organized by columns rather than rows. This allows for efficient data retrieval and aggregation.
Hadoop Integration: HBase is built on top of Hadoop, which means it can leverage Hadoop’s distributed file system (HDFS) for storage and MapReduce for data processing.
Consistency and Replication: HBase provides strong consistency guarantees for read and write operations, and supports replication of data across multiple nodes for fault tolerance.
Built-in Caching: HBase has a built-in caching mechanism that can cache frequently accessed data in memory, which can improve query performance.
Compression: HBase supports compression of data, which can reduce storage requirements and improve query performance.
Flexible Schema: HBase supports flexible schemas, which means the schema can be updated on the fly without requiring a database schema migration.
Note – HBase is extensively used for online analytical operations, like in banking applications such as real-time data updates in ATM machines, HBase can be used.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...