Working with database using Pandas
Last Updated :
06 Apr, 2023
Performing various operations on data saved in SQL might lead to performing very complex queries that are not easy to write. So to make this task easier it is often useful to do the job using pandas which are specially built for data preprocessing and is more simple and user-friendly than SQL.
There might be cases when sometimes the data is stored in SQL and we want to fetch that data from SQL in python and then perform operations using pandas. So let’s see how we can interact with SQL databases using pandas.
This is the database we are going to work with
diabetes_data
Note: Assuming that the data is stored in sqlite3
Reading the data
import sqlite3
import pandas as pd
con = sqlite3.connect('Diabetes.db')
data = pd.read_sql_query('Select * from Diabetes;', con)
data.head()
|
Output
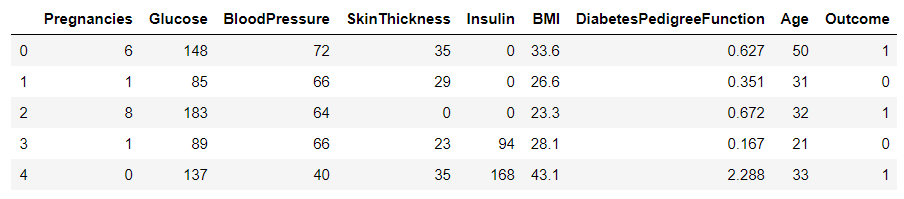
Basic operation
- Slicing of rows
We can perform slicing operations to get the desired number of rows from within a given range.
With the help of slicing, we can perform various operations only on the specific subset of the data
data = pd.read_sql_query('Select * from Diabetes;', con)
df1 = data[10:15]
df1
|
Output
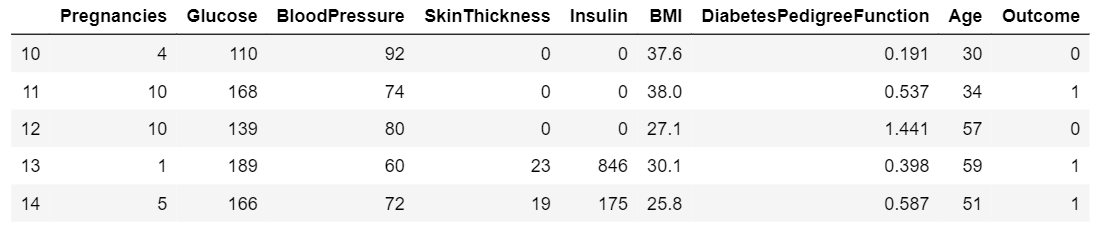
- Selecting specific columns
To select a particular column or to select number of columns from the dataframe for further processing of data.
data = pd.read_sql_query('Select * from Diabetes;', con)
df2 = data.loc[:, ['Glucose', 'BloodPressure']].head()
df2
|
Output:
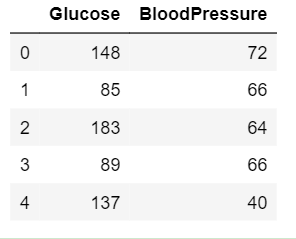
- Summarize the data
In order to get insights from data, we must have a statistical summary of data. To display a statistical summary of the data such as mean, median, mode, std etc. We perform the following operation
data = pd.read_sql_query('Select * from Diabetes;', con)
data.describe()
|
Output:
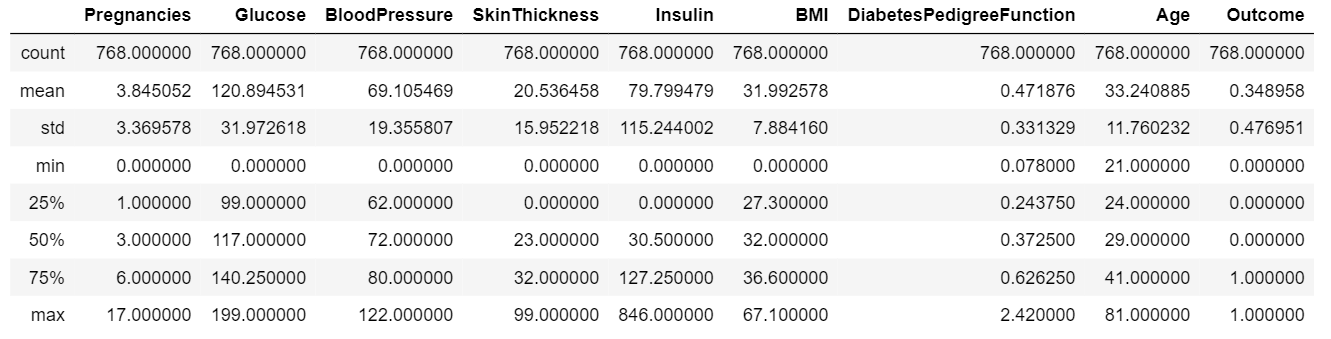
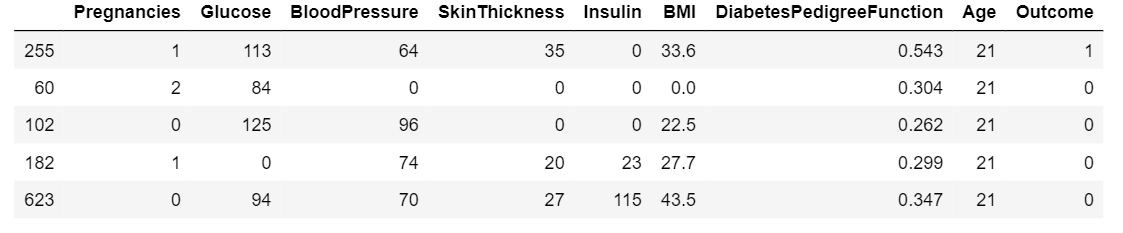
- Sort data with respect to a column
For sorting the dataframe with respect to a given column values
data = pd.read_sql_query('Select * from Diabetes;', con)
data.sort_values(by ='Age').head()
|
Output:
- Display mean of each column
To Display the mean of every column of the dataframe.
data = pd.read_sql_query('Select * from Diabetes;', con)
data.mean()
|
Output:

Share your thoughts in the comments
Please Login to comment...