What Is Amazon Neptune? Setting Amazon Neptune
Last Updated :
26 Mar, 2024
Amazon Neptune is a powerful service that simplifies the management and analysis of highly connected data. With its scalability, user-friendliness, security, and integration with other AWS services, Neptune enables organizations to unlock insights from complex data relationships with ease and efficiency. This cloud service provided by Amazon Web Services helps business entities to manage and massive query, ever growing data related to networks such as social networks and recommendation systems.
What Is Amazon Neptune?
It was originated in 2017 with the purpose of solving the issues of processing complex data relationships on massive amounts of data. At its core, Neptune supports two popular ways of representing connected data: they can build topologies with property graphs and RDF. By combining these two approaches, the system gives flexibility to user to use various kind of graph data which is specific to their use cases. Neptune is presented as a platform-friendly tool which involves query languages and access and interfaces based on industry standards such as Apache TinkerPop Gremlin and SPARQL. This help the developers to use their experience and tool inventory, allowing Neptune to be adopted with much ease without having to start learning completely new technologies.
It is of utmost importance for Neptune that it should be safe with data being encrypted and different levels of access control implemented to render it more reliable and also it incorporates the support for virtual private networks (VPNs). This is the assurance that graph data that is considered to be of moderate to high sensitivity is not exposed to the risk of trapping the data breaches of unauthorized access. Moreover, Neptune also works in tandem with other AWS services which enables organizations to construct and orchestrate the entire data analysis and processing pipeline lifecycle. Whether it’s wasting data, transforming, then loading it with AWS Glue or by employing Amazon SageMaker graph analytics for machine learning-powered graph analytics, Neptune gives a complete solution for all graph-based solutions.
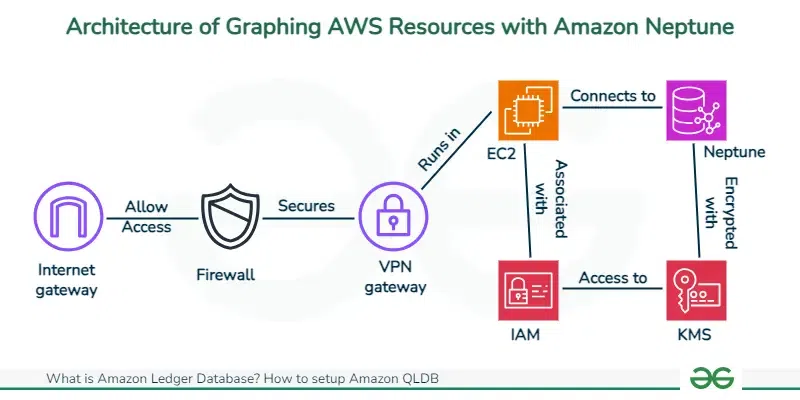
Features Of Amazon Neptune
The following are the features of Amazon Neptune:
- This is a full-fledged graph database service in the hands of Amazon Web Service (AWS). It is intended to be an application to facilitate the application of applications with highly interlasting dataset without having to bother about the underlying infrastructure.
- It has a low-value dynamics and far-from-intrusion management style. AWS automates all these intentional activities as well, such as deployment of the hardware, making software updates, and keeping backups. It helps you lessen the load of other measures to focus only on developing your mobile app.
- Neptune helps to achieve high availability and durability by replicating user data across several Availability Zones within a single AWS region. Hence, your Database systems will continue to be online as much as there is a power off, and other technical issues might arise.
- Denizibility was optimized in Neptune, which is a purpose-built graph database, for storing and querying data which has a lot of interconnections. It supports two types of graph models: plug into a variety of graph databases like property graphs and RDF graphs, therefore, covering a broad array of use case scenarios such as social networks, recommender systems, fraud detection, and knowledge graphs.
- The scalable architecture makes provision of more than enough space for your databases because the workload grows unevenly. It is possible to assume read replicas for offloading read traffic and you will improve response accordingly, Neptune will handle load balancing and failover on your behalf.
- The Neptune’s reliability is supported by ACID transaction backing, and so, your data will always remain accurate and consistent, no matter whether there are multiple users or applications accessing it in a parallel manner. Preserving data integrity is technical for applications that demand very strong data consistency only.
- It’s System integration and navigation are made simpler which is able to accommodate both common traversal languages Gremlin and SPARQL. This implies that user can ask queries over your graph data and get back results using a language you already understand.
How To Setup Amazon Neptune: A Step-By-Step Guide
Step 1: Log in to the AWS Management Console with your AWS account details. Navigate to the Amazon Neptune service by searching for “Neptune” in the services list.
.jpg)
Step 2: Select the AWS region where you want to create your Neptune instance. Choose a region close to your users for better performance. Click on “launch Amazon Neptune” to create a new Neptune database cluster.
.jpg)
Step 3: Select the appropriate Engine options and name your DB Cluster identifier in the settings row. Select a template and scroll down.
.jpg)
Step 4: Select the template for your Neptune instance and specify the DB instance size according to your need.
.jpg)
=
Step 5: Define the availability, durability and connectivity of your DB Cluster Neptune and enable additional connectivity configuration accordingly.
.jpg)
Step 6: Now user must configure the notebook and create the IAM role. Do the same and review your configuration settings.
.jpg)
Step 7: Select the additional configuration you want in your database, review the database from start and click on the create database.
.jpg)
Step 8: Wait for Neptune to provision the resources and create your database cluster, which may take several minutes.
- Once the cluster is available, retrieve the endpoint and port information from the AWS Management Console to connect to your Neptune instance.
- Now, Start using your Neptune database by connecting to it using compatible database clients or applications. Load data into your Neptune database and begin querying and analyzing your graph data.
.jpg)
Step 9: Monitor the performance and health of your Neptune instance using Amazon CloudWatch metrics and performance insights. Adjust resources as needed to optimize performance and cost.
.jpg)
Step 10: Optionally, set up automated backups and snapshots for your Neptune instance to protect against data loss. Configure backup retention periods and snapshot schedules according to your data protection requirements.
.jpg)
Advantages Of Amazon Neptune
The following are the advantages of Amazon Neptune:
- This offers a blazing Fast virtual machine that performs RDF and graph type of queries incredibly fast, hence you don’t have to wait for a lag before you get the answers you are looking for.
- It provides scalability due to which size increases, data grows and user is able to handle with it easily without a decrease in speed. It saves the efforts and time of the user.
- This is a fully managed and preconfigured service and is worry-free, as user can handle the actual setup, configuration, and maintenance. Amazon provides users all back-end helps where you need not be worried about.
- It is very secure as the user information is safely encrypted, archived, off-site, or in an IP-hardened on-site location with controls access, and network isolation.
- This provides flexible data models which enables user to operate in both modes: property graphs and RDF graphs, hence you can pick the model which would be convenient to you.
- It is developer-friendly as it supports all the major graph query languages including Gremlin and SPARQL, which then makes the developing process easy for the developers.
- This provides AWS Integration since it is a scalable and flexible database so it can be interfaced with other AWS solutions like Lambda Glue and Amazon S3 eventually and user can build massive data solutions.
- It provides backups and Recovery of the data that can be periodically synchronized and stored, retrieval of which becomes possible within the backup retention period, as long as user are not wiping or upgrading it before that.
Disadvantages Of Amazon Neptune
The following are the disadvantages of Amazon Neptune:
- The cost of the operating a Amazon Neptune may become an expensive affair for smaller projects and startups with limited budget hardly available. The pricing of the service is based on things like instance type, storage, data transfer, extra features, And then, these can get pretty expensive, especially, as the database grows.
- It have learning curve when we compare graph databases, such as Amazon Neptune, to other databases, there is a need for these data models to deploy graph data models which are only familiar to users who are unfamiliar with SPARQL and Gremlin. Creating skill-sets in structuring query and visualizing data from graph databases might take longer and need more hard work.
- It have limited query language support as Amazon Neptune supports both Gremlin and SPARQL query languages as well as it seem not to have good enough compatibility with other query languages that are commonly being implemented in relational or document-oriented databases. It is no surprise that such a restriction can cause problems for businesses with built-in tools and procedures that are connected to other languages’ querying systems.
- There is trouble in Vendor Lock-in as it can be associated with user database management with Amazon Neptune which limits your flexibility across cloud providers. Translation of changing the migration from Neptune to another graph database or to a different cloud provider may get complex and costly, especially, if you app leans on AWS features and integrations very strong.
- It has performance scalability because although Amazon Neptune is designed to auto-scale horizontally to ensure handling large-scale graph databases, performance limitations may still be faced by some users who are engaged in dealing with difficult queries and the excessive traffic. Efficient operation can be achieved with smart schema design, query tuning and leading to higher utilization of additional resources, but this can have even higher capital cost.
Conclusion
The use of Amazon Neptune is fast, reliable and fully managed graph database service that work nicely with other AWS services. But there are some things to think about. They can get costly according to our application size, especially for big setups or high availability. There is a need for data models to deploy graph data models which are only familiar to users who are unfamiliar with SPARQL and Gremlin and we need to have knowledge about the technical setup, scaling, monitoring, and troubleshooting.
At last, they may trouble in Vendor Lock-in as it can be associated with user database management with Amazon Neptune which limits your flexibility across cloud providers. However, we also can’t ignore that Amazon Neptune has awesome speed and convenience are worth these potential drawbacks. We can integrates with it seamlessly with other AWS services and we don’t have to worry about maintenance tasks. Amazon Neptune provides point-in-time recovery for up to 35 days, allowing you to restore your cluster to any second within that period. Backups are incremental, continuous, and stored durably in Amazon S3. So we can conclude that it saves, both the time and effort of the user.
Amazon Neptune – FAQ’s
What Do You Mean By Amazon Neptune?
It is a powerful graph database service that simplifies the management and analysis of highly connected data.
Why Is There A Need Of The Amazon Neptune?
It is needed because Neptune enables organizations to unlock insights from complex data relationships with ease and efficiency. This cloud service provided by Amazon Web Services helps business entities to manage and massive query, ever growing data related to networks such as social networks and recommendation systems.
How Does The Amazon Neptune Work?
Amazon Neptune allows its users to use the popular graph query languages Apache TinkerPop Gremlin and W3C’s SPARQL and open Cypher to run powerful queries that are easy to write and perform well on connected data. This significantly reduces code complexity, and allows you to more quickly create applications that process relationships.
Explain Any Two Features Of Amazon Neptune.
- It’s System integration and navigation are made simpler which is able to accommodate both common traversal languages Gremlin and SPARQL. This implies that user can ask queries over your graph data and get back results using a language you already understand.
- This is a full-fledged graph database service in the hands of Amazon Web Service (AWS). It is intended to be an application to facilitate the application of applications with highly interlasting dataset without having to bother about the underlying infrastructure.
What Are The Limitations Of Amazon Neptune?
It have limited query language support as Amazon Neptune supports both Gremlin and SPARQL query languages as well as it seem not to have good enough compatibility with other query languages that are commonly being implemented in relational or document-oriented databases.
Share your thoughts in the comments
Please Login to comment...