The effectiveness of a machine learning model is measured by its ability to make accurate predictions and minimize prediction errors. An ideal or good machine learning model should be able to perform well with new input data, allowing us to make accurate predictions about future data that the model has not seen before. This ability to work well with future data (unseen data) is known as generalization. To consider how well a machine learning model learns and generalizes to new data, we are going to examine the concept of overfitting which is the key factor that can significantly impact the performance of machine learning algorithms on future data, and also going to discuss the Regularization concept which will try to avoid overfitting in machine learning.
In this article, we will cover the Overfitting and Regularization concepts to avoid overfitting in the model with detailed explanations.
Overfitting in Machine Learning
In Machine learning, there is a term called train data and test data which machine learning model will learn from train data and try to predict the test data based on its learning. Overfitting is a concept in machine learning which states a common problem that occurs when a model learns the train data too well including the noisy data, resulting in poor generalization performance on test data. Overfit models don’t generalize, which is the ability to apply knowledge to different situations.
Let’s walk through an example of overfitting using the linear regression algorithm,
Suppose we are training a linear regression model to predict the price of a house based on its square feet and with few specifications. We collect a dataset of houses with their square feet and sale price. We then train our linear regression model on this dataset. Generally in linear regression algorithms, it draws a straight that best fits the data points by minimizing the difference between predicted and actual values. The goal is to make a straight line that captures the main pattern in the dataset . This way, it can predict new points more accurately. But sometimes we come across overfitting in linear regression as bending that straight line to fit exactly with a few points on the pattern which is shown below fig.1. This might look perfect for those points while training but doesn’t work well for other parts of the pattern when come to model testing.
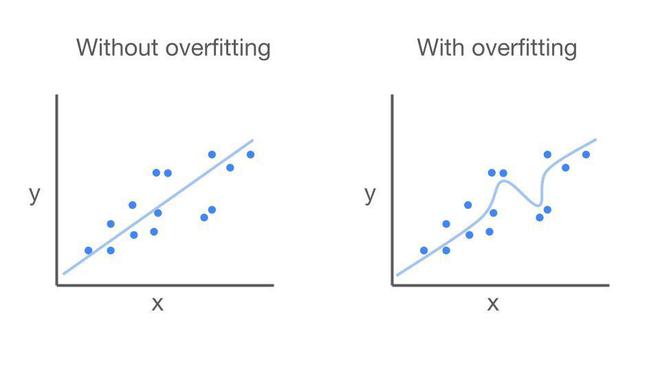
Implementation of linear regression with overfitting
Import the necessary libraries
Python3
import pandas as pd
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
from sklearn.linear_model import Lasso, Ridge
|
This code performs linear regression using scikit-learn and handles data using pandas. The required modules, such as Lasso, Ridge, and LinearRegression, are imported. The code probably belongs to a machine learning pipeline that splits data, trains a model, and uses mean squared error to evaluate the results.
Loading Dataset and Building Model
Load the house dataset from the given link
Python3
data = pd.read_csv('house_dataset.csv')
X = data[['square_feet']].values
y = data['indian_price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
model = LinearRegression()
model.fit(X, y)
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
train_data_mse = mean_squared_error(y_train, y_train_pred)
test_data_mse = mean_squared_error(y_test, y_test_pred)
print(f'Mean Squared Error (MSE) on train data: {round(train_data_mse,2)}')
print(f'Mean Squared Error (MSE) on test data: {round(test_data_mse,2)}')
|
Output:
Mean Squared Error (MSE) on train data: 681582.53
Mean Squared Error (MSE) on test data: 732229.5
This code uses housing data to do linear regression. It divides the data into training and testing sets after reading the dataset from a CSV file, extracting the input (square feet) and output (indian price) attributes. After that, a linear regression model is built, fitted to the training set of data, and predictions are generated for the testing and training sets. Model performance is gauged by calculating Mean Squared Error (MSE) for both training and testing data. The MSE values are printed at the end. Evaluating the linear regression model’s ability to generalize to new data is the aim.
Reason for Overfitting
Let’s discuss what are the reasons that cause overfitting to the machine learning model which are listed below,
- Assigning a complex model that has too many parameters is more likely to overfit the training data.
- when the training dataset is too small the model may not be able to learn the underlying patterns in the data and may start to learn the noise in the data as well.
- when the training data is highly imbalanced with one output class so model may learn to bias its predictions toward the majority class.
- In feature engineering, the features are not properly scaled or engineered thus the model leads to overfitting.
- In feature selection, selected features for training the model are not relevant to the target variable, it is more likely to overfit the training data.
- If the model trains the data too long, it may start to learn the noise in the data and it tends to overfitting.
Techniques to avoid overfitting
Let’s discuss some of the techniques to avoid overfitting to a machine learning model that is listed below,
- Do not make the model too complex, make it simple by removing unnecessary features or reducing the number of parameters.
- Increasing the size of training data by adding more information can able to avoid overfitting.
- Make train data clean by removing the noise and outliers this can able to avoid overfitting.
- Try to make separate validation datasets to evaluate the model performance if the model performs poorly on the validation set, it is likely overfitting the training data.
- Use Ensemble methods, that combine multiple models to provide accurate prediction which can help to reduce the risk of overfitting.
- Use cross-validation, a technique which splits train data repeatedly into many folds and the remaining fold as validation data this can help to reduce overfitting by ensuring that the model is evaluated on a variety of different data splits.
- By applying regularization techniques, which add a penalty to the model’s complexity, this can help to prevent overfitting.
Regularization Technique
Regularization is a technique in machine learning that helps prevent from overfitting. It works by introducing penalties term or constraints on the model’s parameters during training. These penalties term encourage the model to avoid extreme or overly complex parameter values. By doing so, regularization prevents the model from fitting the training data too closely, which is a common cause of overfitting. Instead, it promotes a balance between model complexity and performance, leading to better generalization on new, unseen data.
How Regularization used to prevent overfitting
- By introducing the regularization term in loss function that act like a constrain function of the model’s parameter. This function penalize certain parameter values in model, discouraging them from becoming too large or complex.
- Regularization introduces a trade-off between fitting the training data and keeping the model’s parameters small. The strength of regularization is controlled by a hyperparameter, often denoted as lambda (λ). A higher λ value leads to stronger regularization and a simpler model.
- Regularization techniques help control the complexity of the model. They make the model more robust by constraining the parameter space. This results in smoother decision boundaries in the case of classification and smoother functions in regression, reducing the potential for overfitting.
- Regularization oppose overfitting by discouraging the model from fitting the training data too closely. It prevents parameters from taking extreme values, which might be necessary to fit the training data.
Let’s discuss about two common techniques that involve in regularization which can prevent model from overfitting
- L1 Regularization
- L2 Regularization
L1 Regularization
L1 regularization, also known as Lasso (Least Absolute Shrinkage and Selection Operator) regularization, is a statistical technique used in machine learning to avoid overfitting. It is used to add a penalty term to the model’s loss function. This penalty term encourages the model to keep some of its coefficients exactly equal to zero, effectively performing feature selection. L1 regularization is employed to prevent overfitting, simplify the model, and enhance its generalization to new, unseen data. It is particularly useful when dealing with datasets containing many features, as it helps identify and focus on the most essential ones, disregarding less influential variables.
Let’s derive the mathematical formulation for L1 regularization (Lasso) in simple terms.
In linear regression, the standard model’s goal is to minimize the mean squared error (MSE), represented as:

In the above equation, ‘y’ is the actual target, and ‘ŷ’ is the predicted target. Now, to add L1 regularization, we introduce a new term to the model’s loss function:

Here, ‘w’ represents the model’s coefficients, and ‘α’ is the regularization strength, a hyperparameter that controls how much regularization is applied. The term Σ|w| sums up the absolute values of all the coefficients.What this additional term does is encourage the model to have some of its coefficients exactly equal to zero. It’s like a feature selector it helps the model pick only the most important features, effectively ignoring the less relevant ones.
The larger the ‘α’ value, the stronger the regularization, and the more coefficients will become zero. This balance between the MSE (model fitting the data) and the Σ|w| term (coefficient sparsity) ensures that the model remains relatively simple and less prone to overfitting while still fitting the data effectively.
Implementation of L1 Regularization
Python3
lasso_model = Lasso(alpha=1.0)
lasso_model.fit(X_train, y_train)
y_train_pred_lasso = lasso_model.predict(X_train)
y_test_pred_lasso = lasso_model.predict(X_test)
train_mse_lasso = mean_squared_error(y_train, y_train_pred_lasso)
test_mse_lasso = mean_squared_error(y_test, y_test_pred_lasso)
print(f'Lasso Regression:')
print(f'MSE on training data: {round(train_mse_lasso, 2)}')
print(f'MSE on testing data: {round(test_mse_lasso, 2)}')
|
Output:
Lasso Regression:
MSE on training data: 680964.93
MSE on testing data: 737817.4
L2 Regularization
L2 regularization, often referred to as Ridge regularization, is a is a statistical technique used in machine learning to avoid overfitting. It involves adding a penalty term to the model’s loss function, encouraging the model’s coefficients to be small but not exactly zero. Unlike L1 regularization, which can lead to some coefficients becoming precisely zero, L2 regularization aims to keep all coefficients relatively small. This technique helps prevent overfitting, improves model generalization, and maintains a balance between bias and variance. L2 regularization is especially beneficial when dealing with datasets with numerous features, as it helps control the influence of each feature, contributing to more robust and stable model performance.
Let’s derive the mathematical formulation for L2 regularization (Ridge) in simple terms.
In linear regression, the standard model’s goal is to minimize the mean squared error (MSE), which is represented as:

Here, ‘y’ is the actual target, and ‘ŷ’ is the predicted target.Now, to add L2 regularization, we introduce a new term to the model’s loss function:

In this equation, ‘w’ represents the model’s coefficients, and ‘α’ is the regularization strength, a hyperparameter that controls how much regularization is applied. The term Σ(w^2) adds up the squares of all the coefficients. What this extra term does is encourage the model to keep its coefficient values small. It helps to prevent any one feature from having an overly dominant effect on the predictions. In other words, it adds a cost to having large coefficients.
The larger the ‘α’ value, the stronger the regularization, and the smaller the coefficients will become. This balance between the MSE (model fitting the data) and the Σ(w^2) term (model’s coefficients) ensures that the model doesn’t become too complex, preventing overfitting while still fitting the data effectively.
Implementation of L2 Regularization
Python3
ridge_model = Ridge(alpha=1.0)
ridge_model.fit(X_train, y_train)
y_train_pred_ridge = ridge_model.predict(X_train)
y_test_pred_ridge = ridge_model.predict(X_test)
train_mse_ridge = mean_squared_error(y_train, y_train_pred_ridge)
test_mse_ridge = mean_squared_error(y_test, y_test_pred_ridge)
print(f'Ridge Regression:')
print(f'MSE on training data: {round(train_mse_ridge, 2)}')
print(f'MSE on testing data: {round(test_mse_ridge, 2)}')
|
Output:
Ridge Regression:
MSE on training data: 680964.93
MSE on testing data: 737833.98
How L1 and L2 Regularization used to prevent overfitting
- L1 regularization helps in automatically selecting the most important features by setting the corresponding coefficients to zero this help to reduce the model complexity and thus prevent from overfitting.
- L1 regularization corresponds to a diamond-shaped constraint in parameter space. This constraint leads to parameter values being pushed towards the coordinate axes, resulting in a simpler model which avoid from overfitting.
- L2 regularization corresponds to a circular constraint in parameter space. This constraint leads to parameter values being pushed towards the origin, which results in a more stable and well-conditioned model that avoid from overrfitting.
- L2 regularization, is often used to handle multicollinearity and helps to distribute the importance of correlated features more evenly this avoid complexity of model which prevent from overfitting.
Conclusion
In conclusion, overfitting is a common challenge in machine learning, where a model becomes excessively tailored to the training data, leading to poor generalization on new data. In simple words it’s like memorizing a book but failing to understand the story. To prevent from overfitting, we discussed various techniques, including simplifying the model, gathering more data, and validating model performance. Regularization is a main technique that prevent overfitting by adding a penalty term to the model’s loss function. L1 regularization (Lasso) encourages sparsity in coefficients, effectively selecting essential features, while L2 regularization (Ridge) maintains all coefficients small but not zero. These regularization techniques make a balance between model complexity and performance, enhancing generalization to new, unseen data.
FAQ on Overfitting and Regularization in ML
Q1. Why is overfitting bad?
Overfitting is common problem which leads to poor generalization, causing the model to perform well on the training data but poorly on new, unseen data. This happens when the model becomes too complex and captures noise in the training data.
Q2. How does regularization affect overfitting?
Regularization helps to prevent overfitting by adding constrain to keep the model from not getting too complicated and too closely fitting the training data. It makes the model better at making predictions on new data.
Q3. How can you avoid overfitting in regression?
There are a number of techniques that can be used to avoid overfitting in regression. These techniques include creating validation dataset, regularization, cross-validation, early stopping, and data augmentation.
Q4. Which regularization is used to reduce the overfit problem?
L2 regularization, also known as Ridge regularization, is commonly used to reduce overfitting. It adds a penalty term that constrains extreme parameter values, helping to balance the model’s complexity and improve generalization.
Q5. How regularization works?
Regularization works by adding a penalty term to the model’s loss function, which constrains large parameter values. This constraint on parameter values helps prevent overfitting by reducing the model’s complexity and promoting better generalization to new data.
Q 6. Is slight overfitting will be fine?
A small amount of overfitting can be acceptable, but it’s important to maintan with balance. Too much overfitting can cause the model’s performance on new data, while a slight degree may be fine, it doesn’t significantly affect generalization.
Share your thoughts in the comments
Please Login to comment...