ML – Multi-Task Learning
Last Updated :
24 Feb, 2023
Multi-task learning combines examples (soft limitations imposed on the parameters) from different tasks to improve generalization. When a section of a model is shared across tasks, it is more constrained to excellent values (if the sharing is acceptable), which often leads to better generalization.
The diagram below shows a common type of multi-task learning in which several supervised tasks (predicting  given x) share the same input x, as well as an intermediate-level representation
given x) share the same input x, as well as an intermediate-level representation  that captures a common pool of components (shared). The model is divided into two sorts of parts, each with its own set of parameters:
that captures a common pool of components (shared). The model is divided into two sorts of parts, each with its own set of parameters:
- Task-specific parameters – which only benefit from the examples of their task to achieve good generalization. The higher layers of the neural network are depicted in the diagram below.
- Generic parameters – those that apply to all tasks (which benefit from the pooled data of all the tasks). The lower levels of the neural network are depicted in the diagram below.

Multi-task learning can take many different shapes in deep learning frameworks, and this diagram represents a common scenario in which the tasks share a common input but have many target random variables. The lower layers of a deep network (whether supervised and feedforward or with a generative component with downward arrows) can be shared across tasks, and task-specific parameters (associated with the weights into and out of  and
and  , respectively) can be learned on top of those, resulting in a shared representation . The core idea is that variances in input x are explained by a common pool of factors and that each job is linked to a subset of these factors. Top-level hidden units and are specialised for each task (predicting
, respectively) can be learned on top of those, resulting in a shared representation . The core idea is that variances in input x are explained by a common pool of factors and that each job is linked to a subset of these factors. Top-level hidden units and are specialised for each task (predicting  and
and  , respectively) in this example, while some intermediate-level representation(shared) is shared across all tasks. In the unsupervised learning environment, some of the top-level components should be related to none of the output tasks (
, respectively) in this example, while some intermediate-level representation(shared) is shared across all tasks. In the unsupervised learning environment, some of the top-level components should be related to none of the output tasks ( ): these are the pieces that explain some of the input changes but are not beneficial for predicting or .
): these are the pieces that explain some of the input changes but are not beneficial for predicting or .
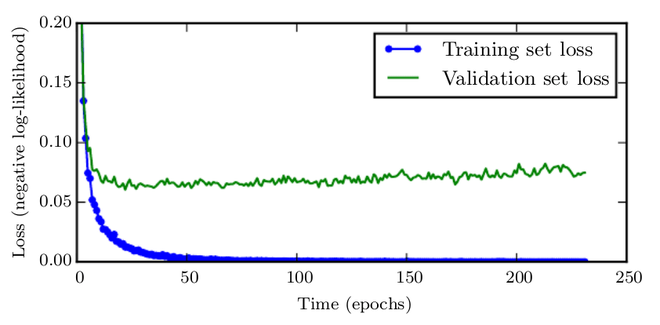
Learning curves show how the negative log-likelihood loss has changed over time (indicated as a number of training iterations over the dataset, or epochs). In this scenario, we use MNIST to train a maxout network. The training goal decreases over time, while the validation set average loss eventually rises, resulting in an asymmetric U-shaped curve.
Improved generalisation and generalisation error bounds can be achieved thanks to the shared parameters, which can significantly improve statistical strength. Of course, this will only occur if precise assumptions regarding the statistical link between distinct activities are valid, meaning that some tasks are related. Some of the factors that explain the differences observed in the data associated with different tasks are consistent across two or more tasks, which is the basic prior premise in deep learning.
Share your thoughts in the comments
Please Login to comment...