Docker has revolutionized the way software program packages are developed, deployed, and managed. Its lightweight and transportable nature makes it a tremendous choice for various use instances and huge file processing. In this blog, we can discover how Docker may be leveraged to streamline huge record-processing workflows, beautify scalability, and simplify deployment. So, let’s dive in!
What is Docker and Big Data Processing?
Big data processing consists of managing and reading large datasets to extract precious insights. Docker, a containerization platform, offers a flexible and scalable environment to perform large data processing duties correctly. By encapsulating applications and their dependencies into boxes, Docker allows clean distribution, replication, and isolation of massive record processing workloads.
Benefits of Using Docker for Big Data Processing
Docker brings several benefits to large statistical processing environments.
- Isolation: Docker packing containers provide technique-stage isolation, making sure that every huge data processing software program runs independently without interfering with others.
- Portability: Docker containers may be deployed throughout top-notch environments, together with community machines, cloud structures, and on-premises servers, making it less complicated to transport huge data processing workloads amongst specific infrastructure setups.
- Scalability: Docker lets in horizontal scaling of big data processing applications by spinning up multiple bins as wished, dishing out the workload, and increasing processing power.
- Resource Efficiency: Docker’s lightweight nature ensures inexperienced useful resource utilization, permitting green processing of massive record workloads without excessive hardware requirements.
- Version Control: Docker allows versioning of containers, ensuring reproducibility and simplifying rollbacks if needed.
Getting Started with Docker for Big Data Processing
To begin using Docker for massive data processing, comply with these steps:
- Install Docker: Download and install Docker on your device or server. Docker presents set-up programs for numerous running structures, making it accessible for precise environments. Refer to the following to install Docker
- Install Docker on Windows.
- Install Docker on Linux (Ubuntu).
- Install Docker on macOS.
- Learn Docker Basics: Familiarize yourself with Docker standards, together with packing containers, photographs, and the Dockerfile. Understanding those important standards will help you understand the underlying ideas behind using Docker for massive information processing.
- Choose a Big Data Processing Framework: Select an appropriate large information processing framework, such as Apache Hadoop or Apache Spark, that supports containerization and integration with Docker.
- Identify Data Sources: Determine the assets from which you’ll extract data for processing. These can embody established or unstructured records stored in databases, document systems, or streaming structures.
- Design the Data Processing Workflow: Define the workflow for processing a huge amount of information. Identify the steps concerned, such as fact ingestion, transformation, analysis, and visualization.
- Containerize Data Processing Applications: Package the essential additives of your large record-processing applications into Docker bins. This includes the fact-processing framework, libraries, and dependencies.
- Configure Networking and Data Storage: Set up networking and information storage alternatives based totally on your necessities. Docker offers features like field networking and data volumes to facilitate conversation among packing containers and persistent point docker storage.
Setting Up a Docker Environment for Big Data Processing
To install a Docker environment for large record processing, don’t forget the subsequent steps:
- Choose an Infrastructure: Determine whether or not you can deploy Docker on a community system, cloud provider, or on-premises server cluster. Each opportunity has its concerns and trade-offs.
- Provision Resources: Allocate the essential assets, which include CPU, memory, and garage, to ensure the most efficient usual performance of your huge information processing workloads.
- Configure Networking: Set up networking configurations, which include exposing ports for gaining access to containerized big data processing applications or organizing conversations among packing containers.
- Manage Security: Implement protection features to shield your Docker environment and the huge records being processed. This consists of securing network connections, making use of having access to controls, and frequently updating Docker components.
Containerizing Big Data Processing Applications
Containerizing large data processing packages consists of growing Docker images that encapsulate the crucial components. Follow the stairs:
- Write Dockerfiles: Create Dockerfiles that specify the commands for building the field photo. Define the bottom photo, and installation dependencies, reproduce the software program code, and configure the box’s surroundings.
- Build Docker Images: Use the Docker documents to build Docker photographs by using the right Docker commands. This will generate box images with all the required components for massive information processing.
- Push to Container Registry: Upload the constructed Docker pictures to a container registry for clean distribution and entry into particular environments.
Orchestrating Big Data Processing with Docker Compose
Docker Compose lets you outline and control multi-field packages. Use it to orchestrate huge statistical processing workflows with more than one interconnected box. Follow these steps:
- Define Compose YAML: Create a Docker Compose a YAML report that describes the offerings, networks, and volumes required for your big data processing workflow.
- Specify Dependencies: Specify dependencies among bins to ensure the proper execution order.
- Launch the Workflow: Use the `docker-compose` command to launch the large data processing workflow so you can start and manage the defined containers.
Managing Data Volumes in Docker for Big Data Processing
Data volumes are vital for persisting information generated or eaten up for the duration of big information processing. Docker presents mechanisms to manipulate information volumes efficiently. Consider the subsequent techniques:
- Named Volumes: Create named volumes to preserve and share facts among bins.
- Bind Mounts: Mount host directories into boxes to offer direct admission to community garage sources.
- External Storage Solutions: Integrate Docker with outdoor storage solutions, which include community-connected storage (NAS) or cloud object garages, for storing massive datasets.
Scaling Big Data Processing with Docker Swarm
Docker Swarm allows disciplined orchestration at scale. Follow those steps to scale your large information processing workloads:
- Initialize a Swarm: Initialize a Docker Swarm to create a cluster of Docker nodes that can distribute and control bins across multiple hosts.
- Create Services: Define services that encapsulate massive statistics processing applications and specify the desired variety of replicas.
- Scale Services: Scale the services up or down based totally on the workload requirements and using the proper Docker Swarm commands.
Monitoring and Troubleshooting Big Data Workloads in Docker
Monitoring and troubleshooting are vital elements in dealing with large data processing workloads in Docker. Consider the subsequent practices:
- Container Monitoring: Utilize Docker tracking tools or zero.33-birthday celebration solutions to display the overall performance and aid utilization of boxes going for massive data processing applications.
- Logging and Error Handling: Implement robust logging mechanisms to capture applicable logs and error messages. Use logging frameworks or systems to centralize and analyze log facts.
- Container Health Checks: Configure fitness assessments for packing containers to make sure they are on foot nicely. Detect and take care of disasters right away to maintain the stability of the large data processing workflow.
- Performance Optimization: Optimize the overall performance of Docker containers via tuning beneficial and useful resource allocations, adjusting container configurations, and imposing first-class practices unique to your massive statistics processing workload.
Best Practices for Using Docker in Big Data Processing
To make the most of Docker in big data processing, remember the following first-rate practices:
- Keep Containers Lightweight: Strive to create minimalistic and efficient box snapshots to lessen resource usage and enhance overall performance.
- Leverage Orchestration Tools: Use orchestration gear like Docker Swarm or Kubernetes to manipulate and scale big record processing workloads efficaciously.
- Automate Deployment and Configuration: Automate the deployment and configuration of Docker packing containers with the use of equipment like Docker Compose or infrastructure-as-code frameworks.
- Implement Security Measures: Apply excellent protection practices, including relying on base photos, often updating Docker components, and restricting box privileges, to reduce protection dangers.
- Backup and Disaster Recovery: Establish backup and catastrophe restoration strategies for facts generated and processed within Docker bins. Regularly back up crucial records to save your statistics.
Security Considerations for Docker in Big Data Processing
When using Docker for big record processing, it is important to address safety concerns. Consider these safety concerns:
- Image Security: Only use dependent-on-base pictures and regularly update them to patch any vulnerabilities.
- Container Isolation: Ensure proper container isolation to prevent unauthorized access to sensitive statistics and restrict the impact of capability protection breaches.
- Network Security: Implement secure networking practices, which consist of using encrypted connections and separating box networks from outdoor networks.
- Access Controls: Apply get-right-of-access to controls and restrict privileges to prevent unauthorized get-right-of-entry to or amendment of packing containers and statistics.
- Vulnerability Scanning: Regularly experiment with field pictures for vulnerabilities using security scanning gear and cope with any recognized problems right away.
Use Cases for Docker in Big Data Processing
Docker reveals utility in numerous big facts about processing use times, which incorporate:
- Data Ingestion and ETL: Docker can facilitate the ingestion of facts from several properties and the execution of extract, transform, and cargo (ETL) approaches.
- Data Analysis and Machine Learning: Docker boxes can host analytical gear, libraries, and gadget learning frameworks for factual assessment and developing predictive models.
- Real-time Data Streaming: Docker offers an environment for processing actual-time streaming information, permitting the implementation of movement processing frameworks like Apache Kafka or Apache Flink.
- Distributed Data Processing: Docker allows the deployment and orchestration of dispersed information processing frameworks like Apache Spark, allowing scalable and parallel processing of huge datasets.
Future Trends and Innovations in Docker for Big Data Processing
The destiny of Docker in huge data processing holds several promising tendencies and improvements, including:
- Improved Integration: Enhanced integration among Docker and large record processing frameworks will simplify the deployment and management of complicated big data workflows.
- Container Orchestration Advancements: Ongoing improvements in area orchestration generation like Kubernetes and Docker Swarm will allow even more green and scalable huge statistics processing environments.
- Advanced Networking Features: Docker will continue to evolve its networking skills, making an allowance for extra flexible and consistent networking configurations for large record processing workloads.
- Containerized AI and ML: Docker will play a vital role in containerizing and deploying AI and machine learning technologies, making it easier to combine these technologies with huge record processing pipelines.
Steps To Guide Dockerizing Big Data Applications with Kafka
In this step, we can delve into the charming instance of Dockerizing Big Data Applications with Kafka. Docker has revolutionized the manner in which we increase, set up, and manage packages, offering a steady and green environment for running software programs. With the rising reputation of Apache Kafka, an allotted streaming platform, combining the electricity of Docker with Kafka can notably improve the scalability, flexibility, and performance of your big data applications. We’ll guide you through every step of the process to ensure a seamless experience while deploying your Kafka-primarily based programs with Docker.
- Before we dive into the Dockerization process, make certain you have the following conditions in place:
- Basic expertise in Docker and its core ideas.
- Familiarity with Apache Kafka and its architecture and Docker architecture.
- A computer with Docker established and well-configured.
- Access to a terminal or command activation.
Step 1: Setting Up Your Kafka Environment

The first step in the example of Dockerizing your Big Data applications with Kafka is to install the Kafka environment. Ensure you have the state-of-the-art model of Kafka downloaded and installed on your neighborhood machine. You can choose to run Kafka in standalone or allotted mode, depending on your requirements.
Step 2: Create a Dockerfile

Now we installed our Kafka environment setup, Then create a Dockerfile that defines the Docker picture for our Kafka-based application. The Dockerfile specifies the base photograph, environment variables, and vital configurations required to run your software inside a container.
#Dockerfile, Use a base image that supports your application
FROM openjdk:11
# Set environment variables
ENV APP_HOME=/app
ENV KAFKA_BROKERS=localhost:9092
# Create the application directory
RUN mkdir -p $APP_HOME
# Set the working directory
WORKDIR $APP_HOME
# Copy the JAR file and other dependencies
COPY your_app.jar $APP_HOME/
COPY config.properties $APP_HOME/
# Expose necessary ports
EXPOSE 8080
# Run your application
CMD ["java", "-jar", "your_app.jar", "--kafka.brokers=$KAFKA_BROKERS"]
Replace your_app. Jar with the call of your Kafka-primarily based utility JAR file and configuration. Residences with any configuration files required.
Step 3: Building the Docker Image

Now we created the Dockerfile, Then you want to create the Docker image. For creating a docker image open your terminal or command prompt and go to the docker folder path and enter the below command:
##bash
$ docker build -t your_image_name:latest .
This command instructs Docker to construct the photograph using the Dockerfile inside the cutting-edge listing and tag it with the name your_image_name and the brand-new model.
Step 4: Running the Kafka Docker Container
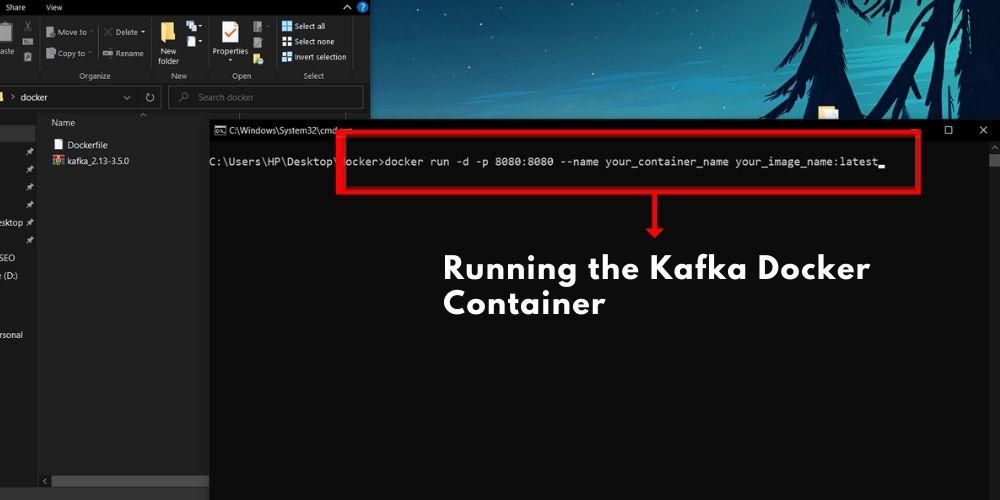
Once the Docker photo is constructed, we will run the Kafka Docker field. Before you proceed, ensure that your Kafka cluster is operational and running smoothly. Now, execute the subsequent command:
##bash
$ docker run -d -p 8080:8080 --name your_container_name your_image_name:latest
This command runs the Docker container in detached mode (-d) and maps port 8080 of the field to port 8080 of the host gadget. This is how Docker port mapping works.
Step 5: Verifying the Docker Container
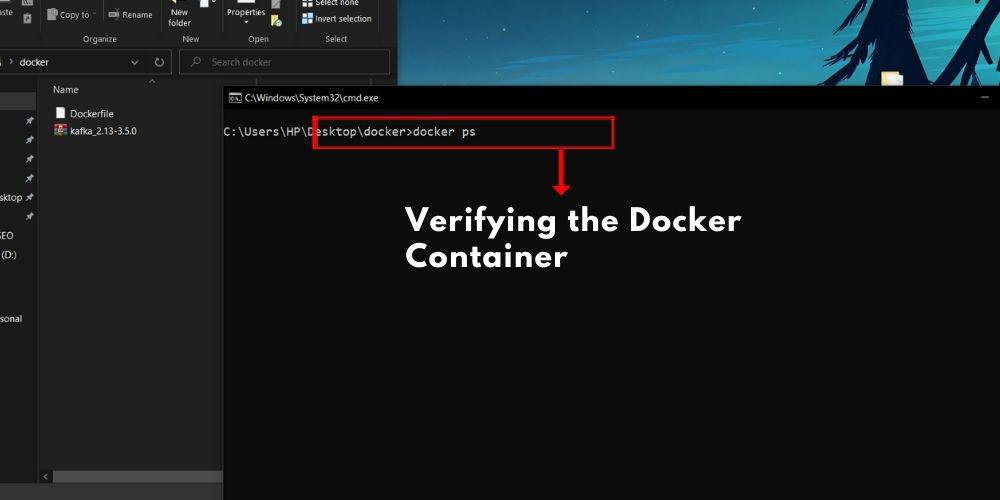
To verify that your Kafka-based software is strolling successfully within the Docker field, use the following command:
##bash
$ docker ps
You need to see your field listed along with its reputation.
Step 6: Scaling Your Kafka Docker Container

One significant benefit of utilizing Docker alongside Kafka is the simplicity it offers for scaling. Docker permits you to scale your Kafka bins effortlessly. To scale your Kafka box, use the subsequent command:
##Bash
$ docker-compose up --scale your_service_name=2
Replace your service name with the name of the carrier described in your docker-compose.yml file.
Now, you have efficaciously Dockerized your Big Data Applications with Kafka, leveraging the power and flexibility of Docker-packed containers. This step-by-step affords you a complete manual for deploying and scaling Kafka-based applications with no trouble.
Conclusion
Docker provides a great platform for streamlining large record-processing workflows. Its flexibility, portability, and scalability make it a precious tool for dealing with complicated big-record workloads. By following best practices, leveraging orchestration equipment, and addressing security problems, corporations can unencumber the entire ability of Docker for their huge statistical processing endeavors. In conclusion, Docker gives a powerful answer for large-scale data processing, imparting a scalable and flexible platform that streamlines workflows and complements overall performance. By harnessing the benefits of Docker and following first-rate practices, corporations can unencumber the real functionality of huge statistics and gain meaningful insights from their facts.
FAQs on Docker for Big Data Processing
Q.1: Is Docker appropriate for processing big data?
Yes, Docker is nicely suited for massive data processing. Its containerization abilities, portability, and scalability make it a valuable tool for coping with and processing large datasets successfully.
Q.2: Can Docker be used with famous massively parallel statistics processing frameworks like Apache Hadoop and Apache Spark?
Absolutely! Docker can be seamlessly integrated with well-known massively parallel statistical processing frameworks like Apache Hadoop and Apache Spark. It permits the containerization of those frameworks and simplifies their deployment and control.
Q.3: How does Docker assist with scalability in big data processing?
Docker permits horizontal scaling of big information processing packages by allowing multiple boxes to be spun up and allotted across exquisite hosts. His permit permits distributing the workload and growing processing strength as needed.
Q.4: What are a few protection concerns with the use of Docker for big record processing?
When using Docker for massive record processing, it’s essential to not forget security features, such as relied-on base pictures, putting boxes apart, enforcing network safety practices, and frequently updating Docker additives to cope with any vulnerabilities.
Share your thoughts in the comments
Please Login to comment...