How to set up and Run CUDA Operations in Pytorch ?
Last Updated :
02 Jun, 2023
CUDA(or Compute Unified Device Architecture) is a proprietary parallel computing platform and programming model from NVIDIA. Using the CUDA SDK, developers can utilize their NVIDIA GPUs(Graphics Processing Units), thus enabling them to bring in the power of GPU-based parallel processing instead of the usual CPU-based sequential processing in their usual programming workflow.
With deep learning on the rise in recent years, it’s seen that various operations involved in model training, like matrix multiplication, inversion, etc., can be parallelized to a great extent for better learning performance and faster training cycles. Thus, many deep learning libraries like Pytorch enable their users to take advantage of their GPUs using a set of interfaces and utility functions. This article will cover setting up a CUDA environment in any system containing CUDA-enabled GPU(s) and a brief introduction to the various CUDA operations available in the Pytorch library using Python.
Installation
First, you should ensure that their GPU is CUDA enabled or not by checking their system’s GPU through the official Nvidia CUDA compatibility list. Pytorch makes the CUDA installation process very simple by providing a nice user-friendly interface that lets you choose your operating system and other requirements, as given in the figure below. According to our computing machine, we’ll be installing according to the specifications given in the figure below.
Refer to Pytorch’s official link and choose the specifications according to their computer specifications. We also suggest a complete restart of the system after installation to ensure the proper working of the toolkit.
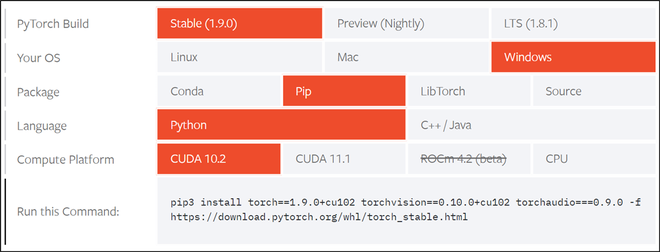
Screenshot from Pytorch’s installation page
pip3 install torch==1.9.0+cu102 torchvision==0.10.0+cu102 torchaudio===0.9.0 -f https://download.pytorch.org/whl/torch_stable.html
Getting started with CUDA in Pytorch
Once installed, we can use the torch.cuda interface to interact with CUDA using Pytorch. We’ll use the following functions:
Syntax:
- torch.version.cuda(): Returns CUDA version of the currently installed packages
- torch.cuda.is_available(): Returns True if CUDA is supported by your system, else False
- torch.cuda.current_device(): Returns ID of current device
- torch.cuda.get_device_name(device_ID): Returns name of the CUDA device with ID = ‘device_ID’
Code:
Python3
import torch
print(f"Is CUDA supported by this system?
{torch.cuda.is_available()}")
print(f"CUDA version: {torch.version.cuda}")
cuda_id = torch.cuda.current_device()
print(f"ID of current CUDA device:
{torch.cuda.current_device()}")
print(f"Name of current CUDA device:
{torch.cuda.get_device_name(cuda_id)}")
|
Output:

CUDA version
Handling Tensors with CUDA
For interacting Pytorch tensors through CUDA, we can use the following utility functions:
Syntax:
- Tensor.device: Returns the device name of ‘Tensor’
- Tensor.to(device_name): Returns new instance of ‘Tensor’ on the device specified by ‘device_name’: ‘cpu’ for CPU and ‘cuda’ for CUDA enabled GPU
- Tensor.cpu(): Transfers ‘Tensor’ to CPU from it’s current device
To demonstrate the above functions, we’ll be creating a test tensor and do the following operations:
Checking the current device of the tensor and applying a tensor operation(squaring), transferring the tensor to GPU and applying the same tensor operation(squaring) and comparing the results of the 2 devices.
Code:
Python3
import torch
x = torch.randint(1, 100, (100, 100))
print(x.device)
res_cpu = x ** 2
x = x.to(torch.device('cuda'))
print(x.device)
res_gpu = x ** 2
assert torch.equal(res_cpu, res_gpu.cpu())
|
Output:
cpu
cuda : 0
Handling Machine Learning models with CUDA
A good Pytorch practice is to produce device-agnostic code because some systems might not have access to a GPU and have to rely on the CPU only or vice versa. Once that’s done the following function can be used to transfer any machine learning model onto the selected device
Syntax: Model.to(device_name):
Returns: New instance of Machine Learning ‘Model’ on the device specified by ‘device_name’: ‘cpu’ for CPU and ‘cuda’ for CUDA enabled GPU
In this example, we are importing the pre-trained Resnet-18 model from the torchvision.models utility, the reader can use the same steps for transferring models to their selected device.
Code:
Python3
import torch
import torchvision.models as models
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = models.resnet18(pretrained=True)
model = model.to(device)
|
Output:

ML with CUDA
Share your thoughts in the comments
Please Login to comment...