How to handle class imbalance in TensorFlow?
Last Updated :
18 Mar, 2024
In many real-world machine learning tasks, especially in classification problems, we often encounter datasets where the number of instances in each class significantly differs. This scenario is known as class imbalance. TensorFlow, a powerful deep learning framework, provides several tools and techniques to address class imbalance. These include adjusting class weights, using different evaluation metrics, employing data-level methods like oversampling the minority class or undersampling the majority class, and applying algorithm-level approaches like modifying the loss function to penalize misclassifications of the minority class more heavily. Implementing these strategies helps in training models that are more sensitive to the minority class, improving their overall performance in imbalanced dataset scenarios.
For example, in medical diagnosis, the dataset might contain many more healthy cases than disease cases. Such imbalance can bias the training of machine learning models, leading them to perform well on the majority class but poorly on the minority class, which is often of greater interest. Handling class imbalance is crucial to develop models that accurately predict rare events and are fair and unbiased in their decisions.
Concepts Related to Handling Class Imbalance in TensorFlow
- Class Weights: TensorFlow allows assigning different weights to classes through the model training process. This method increases the importance of correctly predicting instances from the minority class.
- Custom Loss Functions: Modifying or creating custom loss functions can directly address class imbalance by penalizing wrong predictions on the minority class more than those on the majority class.
- Data Augmentation for Minority Class: By artificially increasing the size of the minority class through data augmentation, models can learn more diverse patterns, leading to better performance on these underrepresented classes.
- Resampling Techniques: Methods like oversampling the minority class or undersampling the majority class aid in attaining a dataset with improved balance. TensorFlow’s data API (tf.data) facilitates the implementation of such resampling methods efficiently.
- Evaluation Metrics: Accuracy often becomes misleading in imbalanced datasets. TensorFlow supports a variety of other metrics like Precision, Recall, F1 Score, and the Area Under the Receiver Operating Characteristic Curve (AUC-ROC), which provide more insight into the model’s performance across all classes.
Through these methods, TensorFlow provides a robust framework for addressing class imbalance, enabling the development of models that are both accurate and fair across diverse applications.
Steps for Handling Class Imbalance:
- Load Dataset: Load and preprocess the data.
- Calculate Class Weights: Compute class weights inversely proportional to class frequencies.
- Build Model: Create a neural network model.
- Train Model: Train the model using the computed class weights.
- Evaluate Model: Assess model performance.
Implementation: Handling Class Imbalance in TensorFlow
For a real-world demonstration of handling class imbalance in TensorFlow, let’s use the “Pima Indians Diabetes” dataset, commonly used for binary classification tasks. This dataset is not directly available in TensorFlow Datasets but can be easily loaded using pandas from a URL. We’ll demonstrate handling class imbalance by calculating class weights and applying them during model training.
First, ensure you have pandas and TensorFlow installed in your environment.
pip install pandas tensorflow
Importing Necessary Libraries
Python3
import pandas as pd
import numpy as np
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.utils import class_weight
import matplotlib.pyplot as plt
Loading the Dataset
The dataset is loaded from a URL using pandas.read_csv(). The dataset used is the Pima Indians Diabetes dataset, which is a standard dataset used in machine learning for binary classification problems. Column names are explicitly defined.
Python
url = "https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.data.csv"
columns = ['Pregnancies', 'Glucose', 'BloodPressure', 'SkinThickness', 'Insulin', 'BMI', 'DiabetesPedigreeFunction', 'Age', 'Outcome']
data = pd.read_csv(url, names=columns)
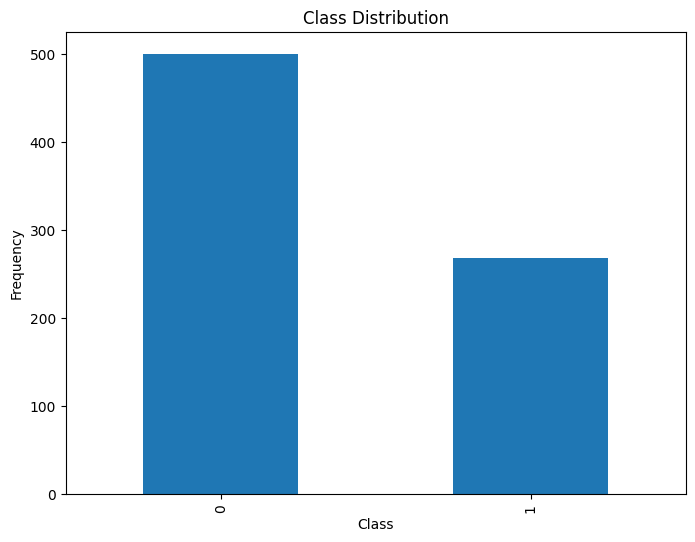
Visualizing Class Distribution
Python3
# Visualize class distribution
plt.figure(figsize=(8, 6))
data['Outcome'].value_counts().plot(kind='bar', title='Class Distribution')
plt.xlabel('Class')
plt.ylabel('Frequency')
plt.show()
Output:
Data Preprocessing
Feature and Target Separation
The features (X) and the target (y) variable, ‘Outcome’, are separated into different variables.
Python
X = data.drop('Outcome', axis=1)
y = data['Outcome']
Data Splitting
The data is split into training and testing sets using train_test_split() from Scikit-learn.
Python
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Data Normalization
The features are scaled to a standard normal distribution using StandardScaler() to ensure that each feature contributes equally to the distance calculations in the learning algorithm.
Python
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Class Weight Calculation
Since the dataset may be imbalanced, class weights are calculated. This is to make the model pay more attention to the minority class during training. compute_class_weight() from Scikit-learn is used to calculate the weights inversely proportional to class frequencies in the input data.
The class weight is a technique used to pay more attention to the underrepresented class during the training of a model. It does this by assigning a higher weight to the minority class so that the cost function used during the training of the machine learning model will give more emphasis to errors made on the minority class. In datasets where one class significantly outnumbers the other, models can become biased towards the majority class, leading to poor predictive performance on the minority class. Using class weights can help mitigate this by making the model consider the minority class more significantly during the training process.
Python
weights = class_weight.compute_class_weight('balanced', classes=np.unique(y_train), y=y_train)
class_weights = dict(enumerate(weights))
Model Building
A simple neural network model is created using TensorFlow’s Keras API. The model consists of an input layer, two hidden layers with ‘relu’ activation, and an output layer with ‘sigmoid’ activation suitable for binary classification.
Python
model = tf.keras.Sequential([
tf.keras.layers.Dense(16, activation='relu', input_shape=(X_train_scaled.shape[1],)),
tf.keras.layers.Dense(8, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
Model Compilation
The model is compiled with the ‘adam’ optimizer and ‘binary_crossentropy’ loss function, which is appropriate for a binary classification problem.
Python
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Model Training and Evaluation with Class Weights
The model is trained using the previously computed class weights to handle the imbalance in the dataset. This helps in improving the model’s performance, especially on the minority class by penalizing the mistakes made on the minority class more than those made on the majority class.
Python
# Train the model with class weights
history_with_weights = model.fit(
X_train_scaled, y_train, epochs=100, class_weight=class_weights, validation_data=(X_test_scaled, y_test), batch_size=32)
# Evaluate the model with class weights
loss_with_weights, accuracy_with_weights = model.evaluate(X_test_scaled, y_test)
print(f"Test Loss with class weights: {loss_with_weights}")
print(f"Test Accuracy with class weights: {accuracy_with_weights}")
Output:
Epoch 1/100
20/20 [==============================] - 1s 6ms/step - loss: 0.4197 - accuracy: 0.8257 - val_loss: 0.5974 - val_accuracy: 0.7273
Epoch 2/100
20/20 [==============================] - 0s 4ms/step - loss: 0.4065 - accuracy: 0.8160 - val_loss: 0.6116 - val_accuracy: 0.6948
Epoch 3/100
20/20 [==============================] - 0s 5ms/step - loss: 0.4049 - accuracy: 0.8094 - val_loss: 0.6244 - val_accuracy: 0.6818
Epoch 4/100
20/20 [==============================] - 0s 6ms/step - loss: 0.4041 - accuracy: 0.8062 - val_loss: 0.6242 - val_accuracy: 0.6883
Epoch 5/100
20/20 [==============================] - 0s 4ms/step - loss: 0.4030 - accuracy: 0.8062 - val_loss: 0.6249 - val_accuracy: 0.6818
Test Loss with class weights: 0.6687824130058289
Test Accuracy with class weights: 0.701298713684082
Model Training and Evaluation without Class Weights
Python3
# Train the model without class weights
history_no_weights = model.fit(
X_train_scaled, y_train, epochs=100, validation_data=(X_test_scaled, y_test), batch_size=32)
# Evaluate the model without class weights
loss_no_weights, accuracy_no_weights = model.evaluate(X_test_scaled, y_test)
print(f"Test Loss without class weights: {loss_no_weights}")
print(f"Test Accuracy without class weights: {accuracy_no_weights}")
Output:
Epoch 1/100
20/20 [==============================] - 3s 36ms/step - loss: 0.7560 - accuracy: 0.6531 - val_loss: 0.7570 - val_accuracy: 0.6429
Epoch 2/100
20/20 [==============================] - 0s 12ms/step - loss: 0.6980 - accuracy: 0.6531 - val_loss: 0.7052 - val_accuracy: 0.6429
Epoch 3/100
20/20 [==============================] - 0s 12ms/step - loss: 0.6540 - accuracy: 0.6515 - val_loss: 0.6732 - val_accuracy: 0.6364
Epoch 4/100
20/20 [==============================] - 0s 10ms/step - loss: 0.6221 - accuracy: 0.6482 - val_loss: 0.6404 - val_accuracy: 0.6299
Epoch 5/100
20/20 [==============================] - 1s 26ms/step - loss: 0.5926 - accuracy: 0.6547 - val_loss: 0.6171 - val_accuracy: 0.6558
Epoch 6/100
20/20 [==============================] - 0s 16ms/step - loss: 0.5681 - accuracy: 0.6661 - val_loss: 0.5983 - val_accuracy: 0.6753
Test Loss without class weights: 0.5878447890281677
Test Accuracy without class weights: 0.7272727489471436
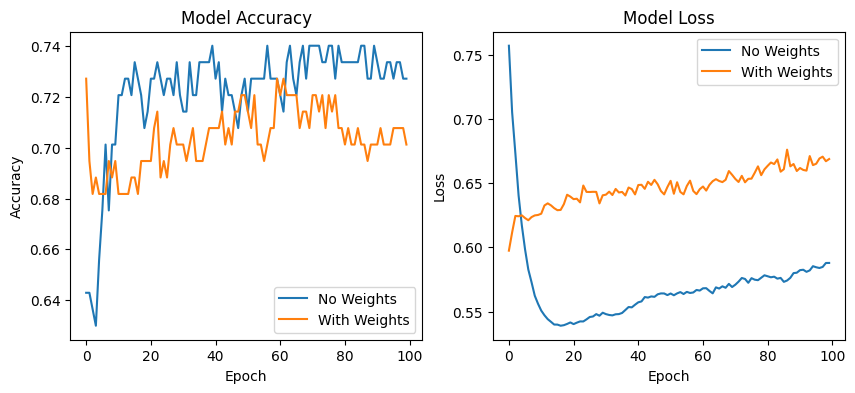
Comparing Evaluation Metrics
Python3
# Compare evaluation metrics
plt.figure(figsize=(10, 4))
plt.subplot(1, 2, 1)
plt.plot(history_no_weights.history['val_accuracy'], label='No Weights')
plt.plot(history_with_weights.history['val_accuracy'], label='With Weights')
plt.title('Model Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history_no_weights.history['val_loss'], label='No Weights')
plt.plot(history_with_weights.history['val_loss'], label='With Weights')
plt.title('Model Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
Output:
Conclusion
This journey into tackling a real-world problem with TensorFlow, focusing on handling class imbalance, reveals both the potential and limitations of our approach. The use of class weights helped in addressing imbalance, guiding the model to pay more attention to underrepresented classes. Through 100 epochs, we observed incremental improvements in accuracy, showcasing the model’s ability to learn and adapt over time. However, achieving a test accuracy of approximately 66.88% signals that while we’ve made significant strides, perfecting model performance demands further tuning. Factors such as experimenting with different architectures, enhancing feature engineering, or incorporating more sophisticated methods like oversampling minority classes or using advanced techniques like SMOTE might yield better results. This exploration underscores the iterative nature of machine learning projects: a continuous cycle of hypothesis, experimentation, and refinement aimed at bridging the gap between current outcomes and desired performance.
Share your thoughts in the comments
Please Login to comment...