How does KNN handle multi-class classification problems?
Last Updated :
08 Apr, 2024
K-Nearest Neighbors (KNN) stands as a fundamental algorithm, wielding versatility in handling both classification and regression tasks. In this article, we will understand what are KNNs and how they handle multi-classification problems.
What are k-nearest neighbors (KNNs)?
K-Nearest Neighbors (KNN) can used for both classification and regression tasks. It belongs to the category of supervised learning, meaning it learns from labeled data to make predictions on new, unseen data. It comes under lazy learning algorithms as there is no training time involved instead it memorizes the entire dataset and makes predictions based on the similarity of new points and existing points in the dataset.
Distance Metrics in KNN
We measure the similarity between data points using distance metrics. There are several distance metrics are used in KNN. The most frequently used are Euclidean distance, Manhattan distance, and Minkowski distance.
- Euclidean Distance: This is the straight-line distance between two points in n-dimensional space. Imagine points on a grid – Euclidean distance calculates the shortest path between them. It’s widely used due to its geometric intuitiveness.
- Manhattan Distance: This metric represents the total distance traveled along each axis (horizontal and vertical movements) to get from one point to another. Imagine traveling only by blocks in a city grid – Manhattan distance captures this restricted movement.
- Minkowski Distance: This is a more general formula that encompasses both Euclidean and Manhattan distances as special cases. It introduces a parameter ‘p’ that allows for different ways of computing the distance. When ‘p’ equals 2, it becomes Euclidean distance. When ‘p’ equals 1, it transforms into Manhattan distance. Minkowski distance offers flexibility for exploring alternative distance measures.
KNN for Multi-Class classification
KNN offers a versatile approach to multi-classification tasks, various steps for performing knn for multi-classification are:
- Data Preprocessing – Split the dataset into train and test after performing data scaling.
- Choosing the ‘K’ value – Choose the optimal value of ‘K’.
- Training the model – Model stores the entire dataset into memory.
- Classifying test data points – For each data point, calculate the distance of it from its ‘K’ nearest neighbors and assign the test point to the class label with the highest number of neighbors.
- Evaluating Performance – Evaluate performance using different performance metrics like accuracy, precision, recall, and F1-score.
In this implementation, we are going to understand how KNNs handle multi-class classification. You can download the dataset from here.
Step 1: Importing libraries
We need to import the below libraries to implement KNN.
Python3
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.impute import SimpleImputer
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score, classification_report
Step 2: Data Description
Getting data descriptions by df.info().
Python3
data = pd.read_csv('tech-students-profile-prediction/dataset-tortuga.csv')
data.info()
Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 20000 entries, 0 to 19999
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 20000 non-null int64
1 NAME 20000 non-null object
2 USER_ID 20000 non-null int64
3 HOURS_DATASCIENCE 19986 non-null float64
4 HOURS_BACKEND 19947 non-null float64
5 HOURS_FRONTEND 19984 non-null float64
6 NUM_COURSES_BEGINNER_DATASCIENCE 19974 non-null float64
7 NUM_COURSES_BEGINNER_BACKEND 19982 non-null float64
8 NUM_COURSES_BEGINNER_FRONTEND 19961 non-null float64
9 NUM_COURSES_ADVANCED_DATASCIENCE 19998 non-null float64
10 NUM_COURSES_ADVANCED_BACKEND 19992 non-null float64
11 NUM_COURSES_ADVANCED_FRONTEND 19963 non-null float64
12 AVG_SCORE_DATASCIENCE 19780 non-null float64
13 AVG_SCORE_BACKEND 19916 non-null float64
14 AVG_SCORE_FRONTEND 19832 non-null float64
15 PROFILE 20000 non-null object
dtypes: float64(12), int64(2), object(2)
memory usage: 2.4+ MB
Step 3: Data Preprocessing
Using the ‘SimpleImputer‘ class to impute missing values with the mean of the column.
Python3
imputer = SimpleImputer(strategy='mean')
data[features] = pd.DataFrame(imputer.fit_transform(data[features]), columns=features)
data.isna().sum()
Output:
HOURS_DATASCIENCE 0
HOURS_BACKEND 0
HOURS_FRONTEND 0
NUM_COURSES_BEGINNER_DATASCIENCE 0
NUM_COURSES_BEGINNER_BACKEND 0
NUM_COURSES_BEGINNER_FRONTEND 0
NUM_COURSES_ADVANCED_DATASCIENCE 0
NUM_COURSES_ADVANCED_BACKEND 0
NUM_COURSES_ADVANCED_FRONTEND 0
AVG_SCORE_DATASCIENCE 0
AVG_SCORE_BACKEND 0
AVG_SCORE_FRONTEND 0
PROFILE 0
dtype: int64
Step 4: Splitting the data
Splitting the dataset into train and test sets.
Python3
X = data.drop(['PROFILE'], axis = 1)
y = data['PROFILE']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
Step 5: Scaling the data
Python3
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
Step 6: Finding the optimal value of ‘K’
We find the optimal value of ‘K’ simply by trying out multiple values of ‘K’ and checking which performs the best.
‘K’ refers to the number of nearest neighbors to consider while making predictions. It is the most important hyperparameter in KNN. For example, if K = 3, the algorithm will look at the three closest data points to the point we are trying to classify and assign the majority class label among the neighbors to the new data point.
The value of K depends on our data. We avoid even values of K since it will lead to conflict while making predictions. We usually find this value by trying out different values for ‘K’ and see which value is giving us better performance.
Python3
acc = {}
for k in range(3, 30, 2):
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
acc[k] = accuracy_score(y_test, y_pred)
# PLotting K v/s accuracy graph
plt.plot(range(3,30,2), acc.values())
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
Output:
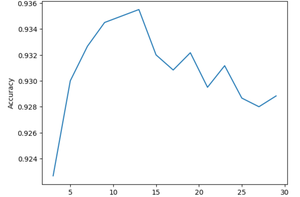
We can see the performance drastically increases with increasing for ‘K’ but as soon it reaches a point (where K = 13) performance starts degrading. So, we can say our optimal value of ‘K’ is 13.
Step 7: Training the model
Python3
knn = KNeighborsClassifier(n_neighbors=13)
knn.fit(X_train_scaled, y_train)
y_pred = knn.predict(X_test_scaled)
print(accuracy_score(y_test, y_pred))
print(classification_report(y_test, y_pred))
Output:
Accuracy: 0.9355
precision recall f1-score support
advanced_backend 0.95 0.92 0.93 986
advanced_data_science 0.91 0.93 0.92 1048
advanced_front_end 0.94 0.95 0.94 996
beginner_backend 0.93 0.91 0.92 994
beginner_data_science 0.94 0.94 0.94 969
beginner_front_end 0.95 0.96 0.95 1007
accuracy 0.94 6000
macro avg 0.94 0.94 0.94 6000
weighted avg 0.94 0.94 0.94 6000
Conclusion
KNN serves as a most intuitive approach for tackling multi-class classification tasks. By leveraging the similarity of data points in the feature space, KNN effectively discerns between multiple classes with minimal assumptions. Following the outlined steps, we can implement and build robust and efficient KNN models for multi-class classification.
Share your thoughts in the comments
Please Login to comment...