How to Find Duplicates in MongoDB
Last Updated :
04 Apr, 2024
Duplicates in a MongoDB collection can lead to data inconsistency and slow query performance. Therefore, it’s essential to identify and handle duplicates effectively to maintain data integrity.
In this article, we’ll explore various methods of how to find duplicates in MongoDB collections and discuss how to use them with practical examples and so on.
How to Find Duplicates in MongoDB?
Duplicates in a MongoDB collection refer to multiple documents sharing the same values in one or more fields. These duplicates can occur due to various reasons such as data import errors, application bugs, or inconsistent data entry. Below are some methods which help us how to find duplicate values or data in MongoDB as follows.
- Using Aggregation Framework
- Using Map-Reduce
Let’s set up an Environment:
To understand How to Find Duplicates in MongoDB we need a collection and some documents on which we will perform various operations and queries. Here we will consider a collection called products which contains information like name, category, price, and description of the products in various documents.
db.a .insertMany([
{
"_id": ObjectId("609742c88308d7582e5c8680"),
"name": "Laptop",
"category": "Electronics",
"price": 999,
"description": "High-performance laptop with SSD storage."
},
{
"_id": ObjectId("609742c88308d7582e5c8681"),
"name": "Smartphone",
"category": "Electronics",
"price": 699,
"description": "Latest smartphone with advanced features."
},
{
"_id": ObjectId("609742c88308d7582e5c8682"),
"name": "Tablet",
"category": "Electronics",
"price": 399,
"description": "Portable tablet for on-the-go productivity."
},
{
"_id": ObjectId("609742c88308d7582e5c8683"),
"name": "Laptop",
"category": "Electronics",
"price": 1099,
"description": "High-performance laptop with dedicated graphics."
}
]);
Output:

Documents inserted
1. Using Aggregation Framework
MongoDB’s aggregation framework provides powerful tools for data analysis. To find duplicates based on specific fields, we will use the $group pipeline stage along with $match and $project stages.
db.products.aggregate([
{
$group: {
_id: "$name",
count: { $sum: 1 },
duplicates: { $addToSet: "$_id" }
}
},
{
$match: {
count: { $gt: 1 }
}
},
{
$project: {
_id: 0,
name: "$_id",
duplicates: 1
}
}
]);
Output:
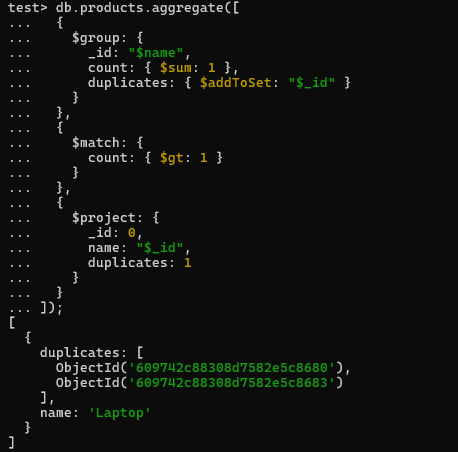
Output
Explanation:
- The aggregation
$group stage groups the documents by the name field and creates a count for each group.
- The
$match stage filters the groups to only include those with a count greater than 1, indicating duplicates.
- The
$project stage reshapes the output to include only the name and duplicates fields, excluding the _id field.
- In this case, the output indicates that the product name “Laptop” has duplicates, with the
_id values of the duplicate documents included in the duplicates array.
2. Using Map-Reduce
Map-Reduce is another method for identifying duplicates in MongoDB. Although it’s less efficient than aggregation, it can be useful for complex duplicate detection scenarios.
var mapFunction = function() {
emit(this.name, 1);
};
var reduceFunction = function(key, values) {
return Array.sum(values);
};
db.products.mapReduce(
mapFunction,
reduceFunction,
{ out: { inline: 1 }, query: { name: { $ne: null } } }
)
Output:

Using Map Reduce
Explanation: The output of the map-reduce operation shows the total count of each unique product name in the products collection. Here’s a breakdown of the output:
- Laptop (2): There are two documents in the collection with the name “Laptop“, so the total count for “Laptop” is 2.
- Smartphone (1): There is one document in the collection with the name “Smartphone“, so the total count for “Smartphone” is 1.
- Tablet (1): There is one document in the collection with the name “Tablet“, so the total count for “Tablet” is 1.
- The name “Laptop” appears twice in the
products collection, indicating that there are duplicate entries for “Laptop“.
Conclusion
Overall, Finding duplicates in MongoDB collections is essential for maintaining data integrity and improving query performance. By utilizing methods such as the aggregation framework, map-reduce you can effectively identify and handle duplicates within your collections. Regularly Reviewing your data and implementing appropriate strategies to detect and address duplicates will ensure a clean and reliable database environment, which enhancing the overall quality of your MongoDB application.
Share your thoughts in the comments
Please Login to comment...