How to Find Duplicate Rows in PL/SQL
Last Updated :
12 Apr, 2024
Finding duplicate rows is a widespread requirement when dealing with database analysis tasks. Duplicate rows often create problems in analyzing tasks. Detecting them is very important. PL/SQL is a procedural extension for SQL. We can write custom scripts with the help of PL/SQL and thus identifying duplicate data eventually becomes very easy.
PL/ SQL also provides us with various other methods through which we can easily solve our duplicate data problem. In this article, we will deep dive into various methods to identify duplicate data in our table. We will explore examples related to each method with clear and concise explanations.
How to Find Duplicate Rows in PL/SQL
We need to implement the COUNT() function, to find the duplicate rows in the table. We have to count several rows that appear more than once in a table. We have to keep the count of each row of the table. If any row appears to have a count of more than 1, then it will be considered a duplicate row. Some common approaches are as follows:
- Using Basic Approach
- Using GROUP BY Clause
Demo SQL Database
In this a on “finding duplicate rows in PL/SQL“, we will use the following table for examples.
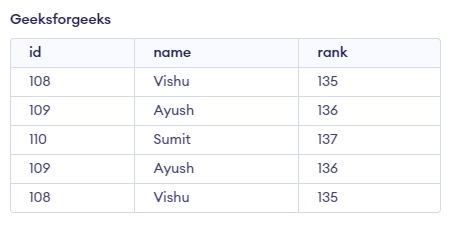
Table – geeksforgeeks
Create Table:
CREATE TABLE geeksforgeeks
(
id NUMBER ,
name VARCHAR2(50),
rank NUMBER
);
Insert Values:
INSERT INTO geeksforgeeks (id, name, rank)
VALUES (108, 'Vishu', 135);
INSERT INTO geeksforgeeks (id, name, rank)
VALUES (109, 'Ayush', 136);
INSERT INTO geeksforgeeks (id, name, rank)
VALUES (110, 'Sumit', 137);
INSERT INTO geeksforgeeks (id, name, rank)
VALUES (109, 'Ayush', 136);
INSERT INTO geeksforgeeks (id, name, rank)
VALUES (108, 'Vishu', 135);
After executing the above query, we can notice our table has been created in the database.
1. Using Naive/Basic
In this method, we will use most common method to find the duplicate values from the table. In short, we will use the most basic approach. We will create some unique combinations and iterate through each combination. If we find that any combination has more than 1 as count, then we will consider this a duplicate.
Query:
DECLARE
--varibale declaration
dupli_count INTEGER;
BEGIN
--we are iterating over distinct rows only.
FOR i IN (SELECT distinct id, name, rank FROM geeksforgeeks) LOOP
--if the count has value more than 1, then we will consider it as duplicate
SELECT COUNT(*) INTO dupli_count
FROM geeksforgeeks
WHERE id = i.id AND name = i.name AND rank = i.rank;
IF dupli_count > 1 THEN
DBMS_OUTPUT.PUT_LINE('duplicate rows ID: ' || i.id || ' and name: ' || i.name || ' and rank: ' || i.rank || ' having count: ' || dupli_count);
END IF;
END LOOP;
END;
Output:

Basic Approach
Explanation: In the above query, we loop through each distinct row in the table ‘geeksforgeeks’. For each unique row, we maintain a row count. If the row count is more than 1, then we will display an appropriate message. In the above image, we can see the smooth working of our query. As rows with id columns 108 and 109 are repeated two times, it is displayed in the output block.
2. Using GROUP BY Clause
In this method, we will use the GROUP BY Clause to find the duplicate rows from our table. The GROUP BY Clause groups the rows based on some specified criteria.
Query:
DECLARE
--you can define any varibale (if required), in this approach we do not need any so its empty
BEGIN
FOR i IN (
SELECT id, name, rank, COUNT(*) as c
FROM geeksforgeeks
GROUP BY id, name, rank
HAVING COUNT(*) > 1
) LOOP
DBMS_OUTPUT.PUT_LINE('duplicate rows ID: ' || i.id || ' and name: ' || i.name || ' and rank: ' || i.rank || ' having count: ' || i.c);
END LOOP;
END;
Output:

Using GROUP BY Clause
Explanation: In the above query, we have group the rows with all the columns present in the table. We have used group by clause to count the occurrences of each combination. If the combination has a count greater than 1, then we consider it as a duplicate row and display an appropriate message for it. In the above image, we can see the working of our query and how it displays the message. Both rows with Id columns 108 and 109 appear two times in the table. Therefore, our query displayed the details of these rows.
Conclusion
Overall, duplicate data detection is very common in data analysis tasks. We can identify duplicate data very easily in PL/SQL. We can use the GROUP BY Clause to create unique combinations of rows and perform operations over it very easily. We have seen a basic approach as well as an approach that includes the GROUP BY Clause. The GROUP BY Clause makes it very easy to detect duplicate data in a PL/SQL environment. Now you have a good understanding of detecting duplicate data in a PL/SQL environment. Now you can write queries related to it and get the desired result.
Share your thoughts in the comments
Please Login to comment...