MongoDB aggregation operations process the data records/documents and return computed results. It collects values from various documents, groups them, and then performs different types of operations on that grouped data like sum , average , minimum , maximum , etc to return a computed result. It is similar to the aggregate function of SQL .
Aggregation in MongoDB allows users to transform, filter, and analyze data. They are used on multiple documents and provide an efficient way to summarize the data.
MongoDB provides three ways to perform aggregation
Aggregation Pipelines
Aggregation pipelines in MongoDB consist of stages and each stage transforms the document. It is a multi-stage pipeline and in each state, the documents are taken as input to produce the resultant set of documents.
In the next stage (ID available) the resultant documents are taken as input to produce output, this process continues till the last stage.
The basic pipeline stages provide:
- filters that will operate like queries
- the document transformation that modifies the resultant document
- provide pipeline provides tools for grouping and sorting documents .
Aggregation pipeline can also be used in sharded collection .
Let us discuss the aggregation pipeline with the help of an example:
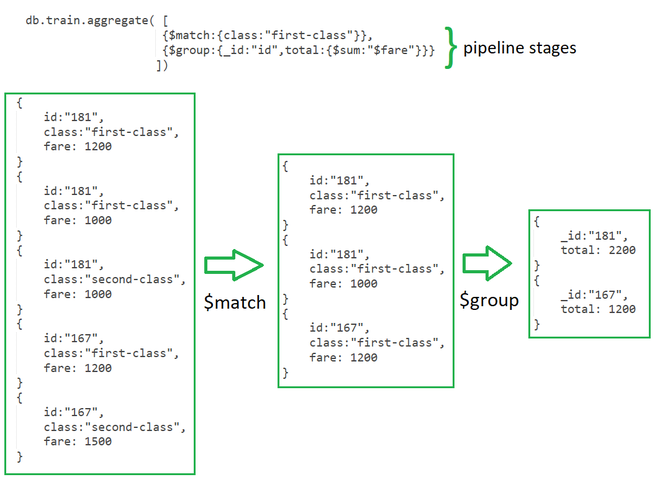
Explanation:
In the above example of a collection of “train fares”. $match stage filters the documents by the value in class field i.e. class: “first-class” in the first stage and passes the document to the second stage.
In the Second Stage, the $group stage groups the documents by the id field to calculate the sum of fare for each unique id.
Here, the aggregate() function is used to perform aggregation. It can have three operators stages , expression and accumulator. These operators work together to achieve final desired outcome.

Stages
Each stage starts from stage operators which are:
- $match: It is used for filtering the documents can reduce the amount of documents that are given as input to the next stage.
- $project: It is used to select some specific fields from a collection.
- $group: It is used to group documents based on some value.
- $sort: It is used to sort the document that is rearranging them
- $skip: It is used to skip n number of documents and passes the remaining documents
- $limit: It is used to pass first n number of documents thus limiting them.
- $unwind: It is used to unwind documents that are using arrays i.e. it deconstructs an array field in the documents to return documents for each element.
- $out: It is used to write resulting documents to a new collection
Expressions
It refers to the name of the field in input documents for e.g. { $group : { _id : ” $id “, total:{$sum:” $fare “}}} here $id and $fare are expressions.
Accumulators
These are basically used in the group stage
- sum: It sums numeric values for the documents in each group
- count: It counts total numbers of documents
- avg: It calculates the average of all given values from all documents
- min: It gets the minimum value from all the documents
- max: It gets the maximum value from all the documents
- first: It gets the first document from the grouping
- last: It gets the last document from the grouping
Note:
- in $group, _id is Mandatory field
- $out must be the last stage in the pipeline
- $sum:1 will count the number of documents and $sum:”$fare” will give the sum of total fare generated per id.
MongoDB Aggregation Pipeline Examples
In the following examples, we are working with:
Database: GeeksForGeeks
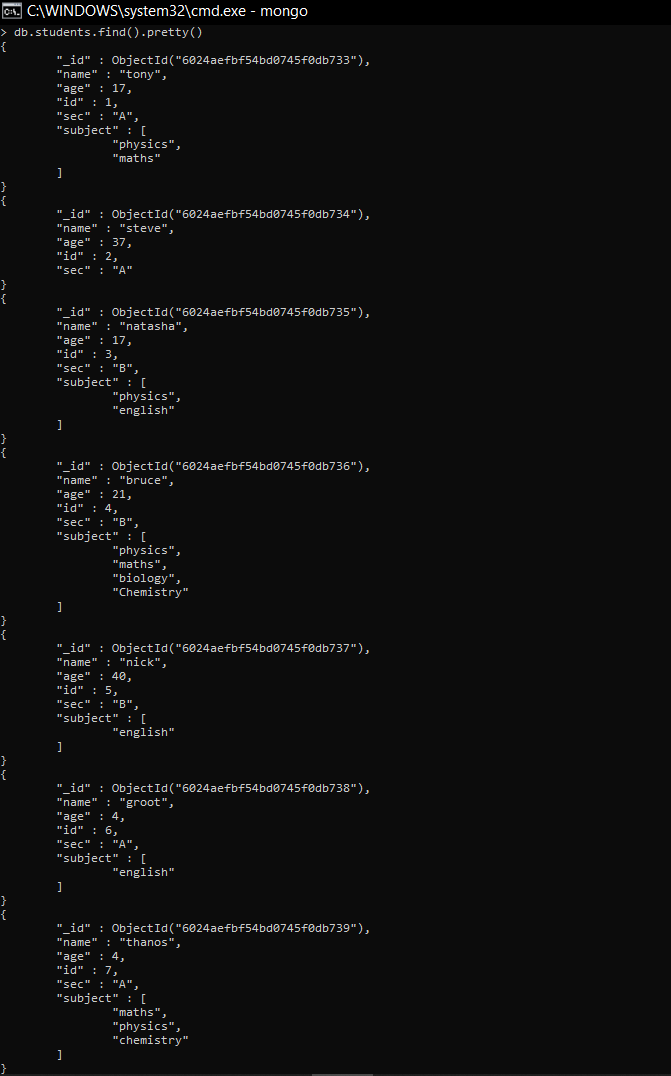
Collection: students
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
Example 1
Displaying the total number of students in section B.
db.students.aggregate([{$match:{sec:"B"}},{$count:"Total student in sec:B"}])
Output:
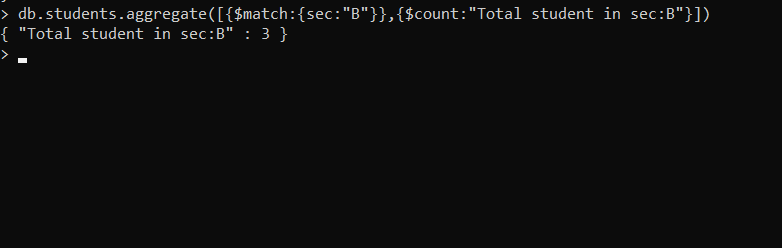
Explanation:
In this example, for taking a count of the number of students in section B we first filter the documents using the $match operator, and then we use the $count accumulator to count the total number of documents that are passed after filtering from the $match.
Example 2
Displaying the total number of students in both the sections and maximum age from both section
db.students.aggregate([{$group: {_id:"$sec", total_st: {$sum:1}, max_age:{$max:"$age"} } }])
Output
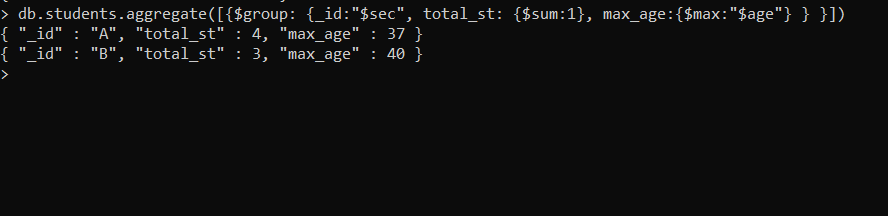
Explanation
In this example, we use $group to group, so that we can count for every other section in the documents, here $sum sums up the document in each group and $max accumulator is applied on age expression which will find the maximum age in each document.
Map Reduce
Map reduce is used for aggregating results for the large volume of data.
Map reduce has two main functions- map to group all the documents and reduce to perform operation on the grouped data.
Syntax
db.collectionName.mapReduce(mappingFunction, reduceFunction, {out:'Result'});
MongoDB Map Reduce Example
In the following example, we are working with:
Database: GeeksForGeeks
Collection: studentsMark
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
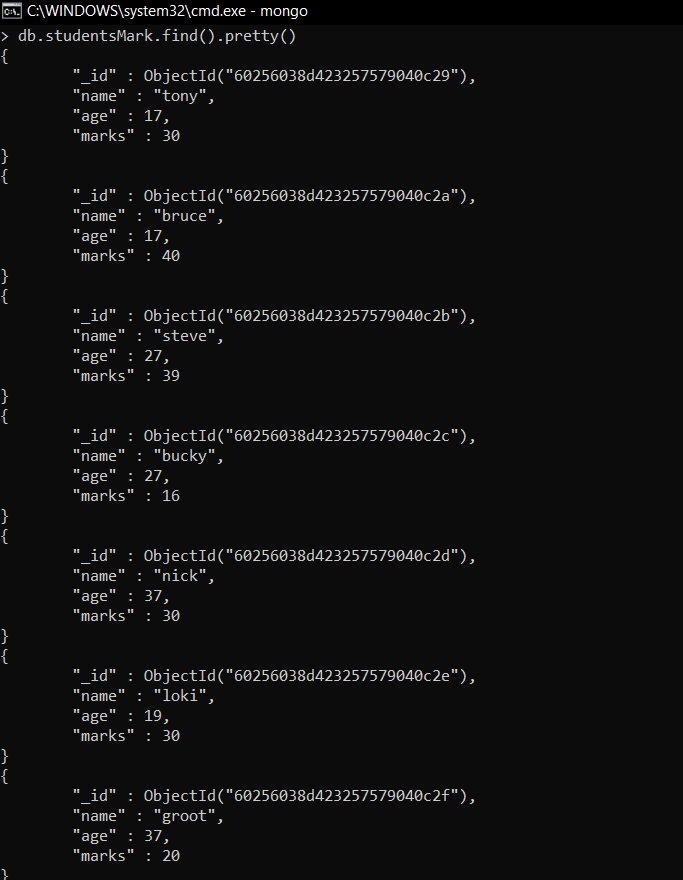
Example
Calculating sum of marks for each age group
var mapfunction = function(){emit(this.age, this.marks)}
var reducefunction = function(key, values){return Array.sum(values)}
db.studentsMarks.mapReduce(mapfunction, reducefunction, {'out':'Result'})
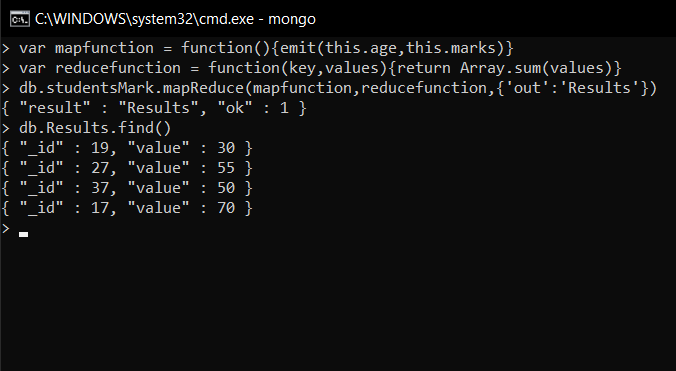
Explanation
The first function ( mapfunction ) assigns age (as “_id” later) and marks as a key-value pair for each student. This data is then fed to the second function ( reducefunction ), which groups students by age and likely calculates the sum of their marks using a separate function. The final results are stored in a new collection named “Results.”
Single Purpose Aggregation
It is used when we need simple access to document like counting the number of documents or for finding all distinct values in a document.
It simply provides the access to the common aggregation process using the count() , distinct() , and estimatedDocumentCount() methods, so due to which it lacks the flexibility and capabilities of the pipeline.
MongoDB Single Purpose Aggregation Example
In the following example, we are working with:
Database: GeeksForGeeks
Collection: studentsMark
Documents: Seven documents that contain the details of the students in the form of field-value pairs.
Example 1
Displaying distinct names and ages (non-repeating)
db.studentsMarks.distinct("name")
Output:
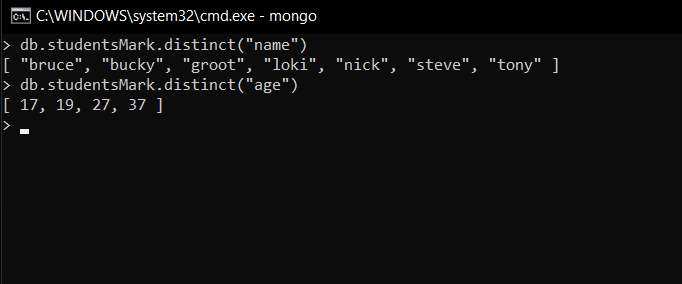
Explanation:
Here, we use a distinct() method that finds distinct values of the specified field(i.e., name).
Example 2
Counting the total numbers of documents
db.studentsMarks.count()
Output
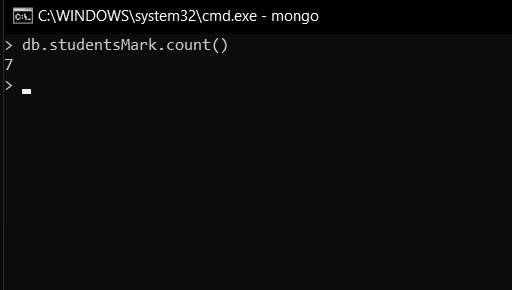
Explanation:
Here, we use count() to find the total number of the document, unlike find() method it does not find all the document rather it counts them and return a number.
Conclusion
This article covers the entire concept of aggregation in MongoDB. Learning all three ways to perform aggregation i.e, Aggregation pipeline, Map-reduce function and Single-purpose aggregation.
We have explained these three MongoDB aggregation techniques in detail, with multiple examples to provide better understanding.
After learning aggregation in MongoDB, users can easily perform analysis on group of data to find meaningful insights.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...