Handling Failure in Distributed System
Last Updated :
19 Mar, 2022
A distributed system is a group of independent computers that seem to clients as a single cohesive system. There are several components in any distributed system that work together to execute a task. As the system becomes more complicated and contains more components, the likelihood of failure rises, resulting in decreased reliability. In other words, we can say in a distributed system, there will always be systems that are broken while others function normally. It is known as a partial failure. Partial failures are unpredictable as the time takes for a message to travel across a network is non-deterministic, we have no way of knowing whether anything has succeeded or failed. As a result, we have no idea which systems have failed in the interim, nor do we know whether a system has failed or not. Working with distributed systems is tough because of this. There is a possibility for partial failures such as node crashes or communication connection failures in distributed systems. As a result, such errors during inter-process communication may result in the following issues:
- Request Message Loss
- Response Message Loss
- Unsuccessful Execution of the Request
- It is possible that your request was put on hold.
- The remote node has taken a break (for garbage collection).
- The request was processed by the remote node, but the response was lost in the network.
- Because our network is congested, responses are delayed.
1. Request Message Loss: This loss can occur when the sender-receiver communication link gets failed or the other reason might be when the node on the receiver side is not enabled at the time the request message reaches it.

2. Loss of Response Message: This loss can occur when the sender-receiver communication link gets failed or the other reason might be when the node on the sender side is not enabled at the time the response message reaches it.

3. Unsuccessful request execution: This occurs when the receiver’s node crashes during the request processing.

For handling these issues, reliable IPC protocol is employed by a message-passing system that deals with the concepts of retransmissions of messages internally after a fixed time interval, and the kernel on receiving side returns an acknowledgment message to the kernel on sending machine.
The following reliable IPC protocol is used in client-server communication between two processes:
- Four-Message Reliable IPC Protocol
- Three-Message Reliable IPC Protocol
- Two-Message Reliable IPC Protocol
1. Four-Message Reliable IPC Protocol: In this client-server communication between two processes takes place in the following manner:
- The request message is sent from a client to the server.
- After receiving the request message, the acknowledgment message is sent from the server’s kernel to the kernel on the client machine. The retransmission of the request message is also carried out by the kernel of the client machine in case the acknowledgment is not received within the set time limits.
- A reply message is sent to the client when the server has serviced the client’s request. The message also holds the processing result.
- Now, an acknowledgment message is sent from the client-side kernel to the server machine’s kernel to acknowledge the receiving of the response. The retransmission of the reply message is also carried out by the kernel of the server machine in case the acknowledgment is not received within the set time limits.

2. Three-Message Reliable IPC Protocol: When the successful response has been received by the client process, it ensures that the request message was received by the server in client-server communication. So, it is based on this concept:
- The request message is sent from a client to server
- After receiving the request message, the reply message which contains processing results is sent from the server to the client. The retransmission of the request message is also carried out by the kernel of the client machine in case the reply is not received within the set time limits.
- A reply message is sent to the client when the server has serviced the client’s request. The message also holds the processing result. Now, the kernel on the client-side sends an acknowledgment to the kernel on the server-side. The retransmission of the response message is also carried out by the kernel of the server machine in case the acknowledgment is not received within the set time limits.

There can be an issue if the request takes a long time to process. Because the retransmission of a message can only be carried out after a fixed set of intervals that generally sets to a large amount to avoid wasteful retransmission. On the other side, if a considerable amount of time is not set for request processing then it might result in the sending of request messages multiple times. To deal with this issue, use the following protocol:
- The client sends the server a request message.
- The kernel starts the timer as soon as the request is received at the server. When the client receives a reply message from the server-side after the processing of the request then it serves as the acknowledgment of the request message. Otherwise, the server sent a separate acknowledgment to acknowledge the request message. The retransmission also needs to be done if an acknowledgment is not received within the timeout period.
- When the reply message is received by the client then the client’s kernel sends an acknowledgment message to the server’s kernel. The retransmission of the reply message will only be carried out by the server’s kernel if the acknowledgment message is not received within the timeout period.
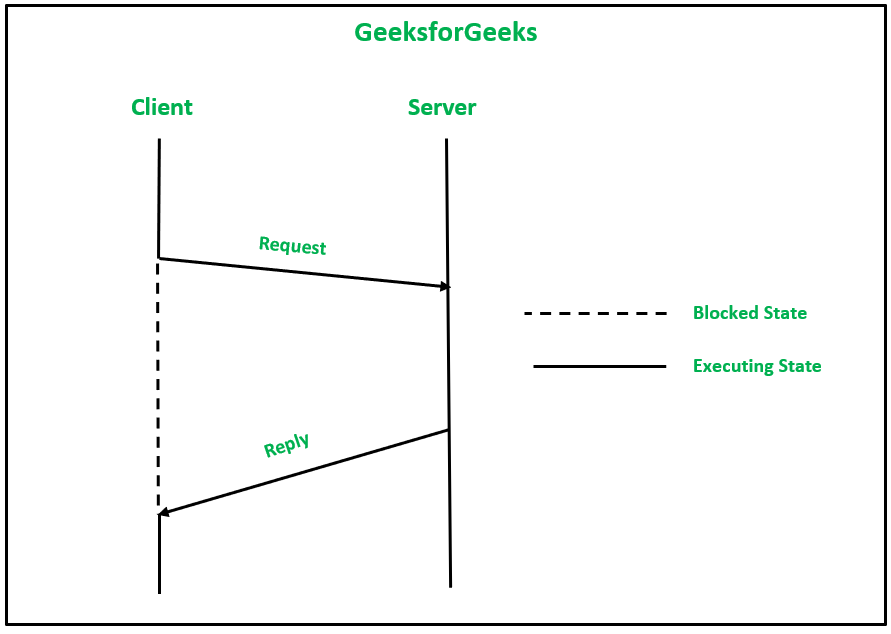
3. Two-Message Reliable IPC Protocol: The Two-Message Reliable IPC Protocol is used for client-server communication between two processes. For its implementation, a message-passing system might be developed:
- The client sends a request message to the server. When the request has been sent then t, is blocked until the server responds.
- When the server has completed processing the client’s request, it sends the client a reply message (including the processing result). The kernel of the client machine retransmits the request message if the response is not received within the timeout interval.
Idempotency:
Idempotency essentially refers to “repeatability.” That implies executing idempotent operation several times with the same parameters, generates the same outcomes with no side effects.
The tracking of Lost and Out-of-Sequence Packets is required in Multidatagram Messages:
The complete transmission implies when all of the message’s packets have been received by the process to which it was sent as every packet is crucial for the effective completion of a multidatagram message transmission. So, the simple approach is to recognize each package independently (called stop-and-wait protocol). The second approach in a multidatagram message (called blast protocol) is to use a single acknowledgment packet for all packets. With the usage of this method, however, a node crash or a communication link failure may result in the following issues:
- During communication, one or more packets of the multidatagram message are lost.
- The out-of-order receiving of packets.
To handle these problems, the bitmap approach is used for identifying the message packets.
There are other various sorts of failures that can occur in a distributed system:
- Application servers can crash for a variety of reasons, including data center outages, excessive CPU/memory utilization, application code flaws, power outages, natural disasters, and so on.
- Services in distributed systems can communicate directly across the network utilizing HTTP/TCP. The unsuccessful communication between two services can occur for a variety of reasons including service unavailability, network issues, dependency failure, and so on. As a result of the cascading effect, one of the services may fail to complete its obligations, potentially causing the entire system to fail.
- This can also happen that an application cannot read or write to a database then it is termed as unsuccessful and this can occur for a variety of reasons, including network issues that make the database unavailable, database choke due to heavy CPU/Memory usage, and database servers going down. Because data is the most crucial component of any system, dealing with database failures is critical.
- Messages and events are delivered using queues and streams, which are crucial components. Infrastructure issues, multiple nodes being unreachable, the minimum in-sync replica count not being met, and so on might cause these failures
The above-mentioned other failure Issues in distributed systems can be handled in the following manner:
- If a node in the application server fails, then it must be replaced with a new node in rotation which is carried out using automated scripts or manual interaction. The backup clusters can be used if the entire cluster or application server goes down. It is done by routing the traffic to a backup cluster located in a separate data center within the same region or a different region.
- If something goes wrong, try again depending on a retry policy. Retries shorten the recovery time for intermittent failures, but they may exacerbate the problem because the reduced system may take some time to recover.
- Caches can also be used as fallbacks to store data for numerous repeated requests, ensuring that in the event of a downstream failure, consistent data from the cache is eventually served. However, because caches may not be useful in all use scenarios, failures should be handled gently, i.e. instead of sending an error, the right degraded answer should be returned.
- Dealing with database failures vary based on the criticality of the data being handled: Having a backup database with all of the data replicated from the main database reduces the risk of a single point of failure, and this redundant database can be utilized to service data demands until the primary database is restored. Until the database is ready to take on the load again, the application might employ fallback techniques for forthcoming requests. Reads can be supplied from either cache or a redundant database.
- Push the message to the duplicate stream or queue to increase redundancy. Even transactional communications will not be lost as a result of this. Creating resources in separate data centers and availability zones is the best way to achieve redundancy. If the message is tier 3, it can be briefly stored in a transactional log. The application can periodically retry to put messages into transactional logs until the stream recovers.
Share your thoughts in the comments
Please Login to comment...