Fault Tolerance in Distributed System
Last Updated :
07 Sep, 2023
Distributed systems are defined as a collection of multiple independent systems connected together as a single system. Every independent system has its own memory and resources and some common resources and peripheral devices that are common to devices connected together. The design of Distributed systems is a complex process where all the nodes or devices need to be connected together even if they are located at long distances. Challenges faced by distributed systems are Fault Tolerance, transparency, and communication primitives. Fault Tolerance is one of the major challenges faced by distributed systems.

In distributed systems, there are three types of problems that occur. All these three types of problems are related.
- Fault: Fault is defined as a weakness or shortcoming in the system or any hardware and software component. The presence of fault can lead to error and failure.
- Errors: Errors are incorrect results due to the presence of faults.
- Failure: Failure is the final outcome where the assigned goal is not achieved.
Fault Tolerance
Fault Tolerance is defined as the ability of the system to function properly even in the presence of any failure. Distributed systems consist of multiple components due to which there is a high risk of faults occurring. Due to the presence of faults, the overall performance may degrade.
Types of Faults
- Transient Faults: Transient Faults are the type of faults that occur once and then disappear. These types of faults do not harm the system to a great extent but are very difficult to find or locate. Processor fault is an example of transient fault.
- Intermittent Faults: Intermittent Faults are the type of faults that comes again and again. Such as once the fault occurs it vanishes upon itself and then reappears again. An example of intermittent fault is when the working computer hangs up.
- Permanent Faults: Permanent Faults are the type of faults that remains in the system until the component is replaced by another. These types of faults can cause very severe damage to the system but are easy to identify. A burnt-out chip is an example of a permanent Fault.
Need for Fault Tolerance in Distributed Systems
Fault Tolerance is required in order to provide below four features.
- Availability: Availability is defined as the property where the system is readily available for its use at any time.
- Reliability: Reliability is defined as the property where the system can work continuously without any failure.
- Safety: Safety is defined as the property where the system can remain safe from unauthorized access even if any failure occurs.
- Maintainability: Maintainability is defined as the property states that how easily and fastly the failed node or system can be repaired.
Fault Tolerance in Distributed Systems
In order to implement the techniques for fault tolerance in distributed systems, the design, configuration and relevant applications need to be considered. Below are the phases carried out for fault tolerance in any distributed systems.
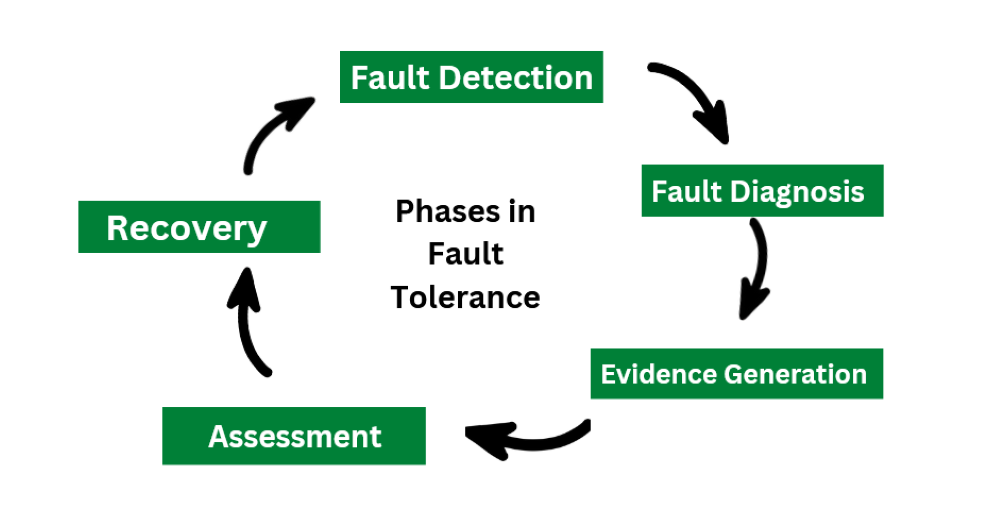
1. Fault Detection
Fault Detection is the first phase where the system is monitored continuously. The outcomes are being compared with the expected output. During monitoring if any faults are identified they are being notified. These faults can occur due to various reasons such as hardware failure, network failure, and software issues. The main aim of the first phase is to detect these faults as soon as they occur so that the work being assigned will not be delayed.
2. Fault Diagnosis
Fault diagnosis is the process where the fault that is identified in the first phase will be diagnosed properly in order to get the root cause and possible nature of the faults. Fault diagnosis can be done manually by the administrator or by using automated Techniques in order to solve the fault and perform the given task.
3. Evidence Generation
Evidence generation is defined as the process where the report of the fault is prepared based on the diagnosis done in an earlier phase. This report involves the details of the causes of the fault, the nature of faults, the solutions that can be used for fixing, and other alternatives and preventions that need to be considered.
4. Assessment
Assessment is the process where the damages caused by the faults are analyzed. It can be determined with the help of messages that are being passed from the component that has encountered the fault. Based on the assessment further decisions are made.
5. Recovery
Recovery is the process where the aim is to make the system fault free. It is the step to make the system fault free and restore it to state forward recovery and backup recovery. Some of the common recovery techniques such as reconfiguration and resynchronization can be used.
Types of Fault Tolerance in Distributed Systems
- Hardware Fault Tolerance: Hardware Fault Tolerance involves keeping a backup plan for hardware devices such as memory, hard disk, CPU, and other hardware peripheral devices. Hardware Fault Tolerance is a type of fault tolerance that does not examine faults and runtime errors but can only provide hardware backup. The two different approaches that are used in Hardware Fault Tolerance are fault-masking and dynamic recovery.
- Software Fault Tolerance: Software Fault Tolerance is a type of fault tolerance where dedicated software is used in order to detect invalid output, runtime, and programming errors. Software Fault Tolerance makes use of static and dynamic methods for detecting and providing the solution. Software Fault Tolerance also consists of additional data points such as recovery rollback and checkpoints.
- System Fault Tolerance: System Fault Tolerance is a type of fault tolerance that consists of a whole system. It has the advantage that it not only stores the checkpoints but also the memory block, and program checkpoints and detects the errors in applications automatically. If the system encounters any type of fault or error it does provide the required mechanism for the solution. Thus system fault tolerance is reliable and efficient.
Conclusion
Fault Tolerance in Distributed Systems is a major task that needs to be accomplished. Faults can lead to a reduction in the overall performance of the system. The faults that arise also differ from one another. Therefore these faults need to be identified and handled according to the working, architecture, and applications of the given distributed systems.
FAQs; Fault Tolerance in Distributed System
1. What is the basic principle of Fault Tolerance?
The basic principle of fault tolerance is to provide a system to continue its working even if any of the parts of it fails and does not affect the performance of the system.
2. What is meant by fault tolerance testing?
Fault Tolerance testing is defined as the process of testing the overall system in order to check for any failure that can occur during performing the intended operation.
3. What is the difference between Fault Tolerance and Load balancing?
Fault Tolerance is a way for working the system even under any failure and makes the system more reliable and robust. Load balancing distributes the load among available processing elements. It ensures better scalability and response time for the users.
4. What is meant by fault in Distributed Systems?
A fault is defined as a weakness or any shortcoming in the system that affects the overall performance and output of the system.
Share your thoughts in the comments
Please Login to comment...