Distributed Data Structures for Real-time Event Processing
Last Updated :
22 Feb, 2023
Real-time event processing is a critical aspect of distributed systems, as it allows for the immediate and accurate handling of data as it is generated. Distributed data structures play a vital role in this process, as they are used to efficiently store and manage the large amounts of data generated by these systems. In this article, we will explore some of the most commonly used distributed data structures for real-time event processing and their specific use cases.
Types of Distributed Data Structures for Real-time Event Processing
1. Distributed Hash Table(DHT):
One of the most widely used distributed data structures for real-time event processing is the distributed hash table (DHT). DHTs are used to store and retrieve data in a distributed system, and they are particularly useful for real-time event processing because they provide fast lookups and low latency. They are also fault-tolerant, which means they can continue to operate even if one or more nodes fail. Distributed hash tables use a consistent hashing algorithm to distribute data evenly across multiple nodes, making them well-suited for large-scale systems.
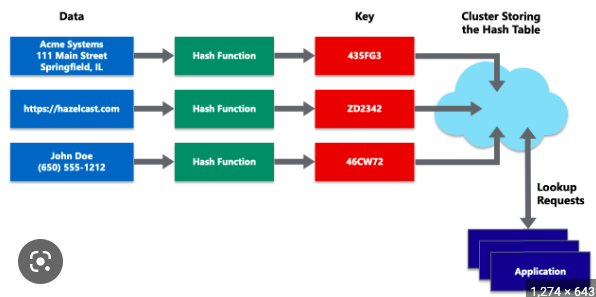
Distributed hash Table
Advantages of Distributed Hash Tables:
- Fast Lookups: Distributed hash tables are designed to provide fast lookups of data, making them well-suited for real-time event processing and other applications that require fast data retrieval.
- Low Latency: Distributed hash tables have low latency, which means that data can be retrieved quickly and with minimal delay.
- Scalability: Distributed hash tables are designed to handle large amounts of data, making them well-suited for large-scale systems.
- Fault-Tolerance: Distributed hash tables are fault-tolerant, which means that they can continue to operate even if one or more nodes fail.
- Load Balancing: Distributed hash tables use consistent hashing algorithms to distribute data evenly across multiple nodes, which helps to ensure that the load is balanced across the system.
Disadvantages of Distributed Hash Tables:
- Complexity: Distributed hash tables can be complex to implement, especially in large-scale systems.
- Limited Data Types: Distributed hash tables are typically limited to storing key-value pairs, which may not be suitable for all types of data.
- Limited Query Capabilities: Distributed hash tables are typically limited in their query capabilities, making them less suitable for more complex queries.
- High Resource Usage: Distributed hash tables can be resource-intensive, which can be a disadvantage in systems with limited resources.
- Limited Security: Distributed hash tables may not be as secure as other data structures, and it can be easy for hackers to penetrate them and extract sensitive information.
2. Distributed Queue:
Distributed queues are used to store and process data in a specific order, and they are particularly useful for real-time event processing because they can handle large amounts of data with low latency. They are also fault-tolerant, which means they can continue to operate even if one or more nodes fail. Distributed queues can be implemented using a variety of algorithms, such as the Kafka algorithm, which is known for its high throughput and low latency.
Advantages of Distributed Queues:
- Order Preservation: Distributed queues are used to store and process data in a specific order, which is useful for real-time event processing and other applications that require data to be processed in a specific order.
- Scalability: Distributed queues are designed to handle large amounts of data, making them well-suited for large-scale systems.
- Fault-Tolerance: Distributed queues are fault-tolerant, which means that they can continue to operate even if one or more nodes fail.
- High Throughput: Distributed queues can handle high volumes of data with low latency, making them well-suited for high-throughput systems.
- Flexibility: Distributed queues can be implemented using a variety of algorithms, such as the Kafka algorithm, which provides high throughput and low latency.
Disadvantages of Distributed Queues:
- Complexity: Distributed queues can be complex to implement, especially in large-scale systems.
- Limited Data Types: Distributed queues are typically limited to storing specific types of data, such as messages or events.
- Limited Query Capabilities: Distributed queues are typically limited in their query capabilities, making them less suitable for more complex queries.
- High Resource Usage: Distributed queues can be resource-intensive, which can be a disadvantage in systems with limited resources.
- Limited Security: Distributed queues may not be as secure as other data structures, and it can be easy for hackers to penetrate them and extract sensitive information.
3. Distributed Trie:
Distributed tries are used to store and retrieve data in a distributed system, and they are particularly useful for real-time event processing because they provide fast lookups and low latency. They are also fault-tolerant, which means they can continue to operate even if one or more nodes fail. Distributed tries are commonly used in distributed systems for efficient data retrieval and storage, and they are particularly useful for large-scale systems.
Advantages of Distributed Tries:
- Fast Lookups: Distributed tries are designed to provide fast lookups of data, making them well-suited for real-time event processing and other applications that require fast data retrieval.
- Low Latency: Distributed tries have low latency, which means that data can be retrieved quickly and with minimal delay.
- Scalability: Distributed tries are designed to handle large amounts of data, making them well-suited for large-scale systems.
- Fault-Tolerance: Distributed tries are fault-tolerant, which means that they can continue to operate even if one or more nodes fail.
- Space Efficiency: Distributed tries are space-efficient, which means they can store large amounts of data in a relatively small amount of memory.
Disadvantages of Distributed Tries:
- Complexity: Distributed tries can be complex to implement, especially in large-scale systems.
- Limited Data Types: Distributed tries are typically limited to storing specific types of data, such as strings.
- Limited Query Capabilities: Distributed tries are typically limited in their query capabilities, making them less suitable for more complex queries.
- High Resource Usage: Distributed tries can be resource-intensive, which can be a disadvantage in systems with limited resources.
- Limited Security: Distributed tries may not be as secure as other data structures, and it can be easy for hackers to penetrate them and extract sensitive information.
4. Distributed Bloom Filters:
A bloom filter is a probabilistic data structure used to test whether an element is a member of a set. Distributed bloom filters are used to test whether an element is a member of a set in a distributed system. They are particularly useful for real-time event processing because they provide fast lookups and low latency. They are also fault-tolerant, which means they can continue to operate even if one or more nodes fail. They are commonly used in distributed systems for efficient data retrieval and storage, and they are particularly useful for large-scale systems.
Advantages of Distributed Bloom Filters:
- Fast Lookups: Distributed Bloom filters are designed to provide fast lookups of data, making them well-suited for real-time event processing and other applications that require fast data retrieval.
- Low Space Requirements: Distributed bloom filters are probabilistic data structures that use a small amount of memory to store large amounts of data.
- Scalability: Distributed bloom filters can be easily scaled to handle large amounts of data.
- Low Latency: Distributed bloom filters have low latency, which means that data can be retrieved quickly and with minimal delay.
- High Throughput: Distributed bloom filters can handle high volumes of data with low latency, making them well-suited for high-throughput systems.
Disadvantages of Distributed Bloom Filters:
- False positives: Distributed bloom filters are probabilistic data structures, which means they may produce false positives, meaning they may indicate that an item is present in the set when it is not.
- Limited Data Types: Distributed bloom filters are typically limited to storing specific types of data, such as keys or values.
- Limited Query Capabilities: Distributed bloom filters are typically limited in their query capabilities, making them less suitable for more complex queries.
- High Resource Usage: Distributed bloom filters can be resource-intensive, which can be a disadvantage in systems with limited resources.
- Limited Security: Distributed bloom filters may not be as secure as other data structures, and it can be easy for hackers to penetrate them and extract sensitive information.
5. Distributed Graph:
Distributed graphs are used to store and retrieve data in a distributed system, and they are particularly useful for real-time event processing because they provide fast lookups and low latency. They are also fault-tolerant, which means they can continue to operate even if one or more nodes fail. Distributed graphs can be implemented using a variety of algorithms, such as the Pregel algorithm, which is known for its high throughput and low latency.
Advantages of Distributed Graphs:
- Scalability: Distributed graphs are designed to handle large amounts of data, making them well-suited for large-scale systems.
- Flexibility: Distributed graphs can be implemented using a variety of algorithms, such as the Pregel algorithm, which provides high throughput and low latency.
- Real-time Processing: Distributed graphs can be used to process real-time data, allowing for fast and accurate analysis of data.
- High Throughput: Distributed graphs can handle high volumes of data with low latency, making them well-suited for high-throughput systems.
- Representing Complex Relationships: Distributed graphs can be used to represent complex relationships between data, allowing for more accurate analysis and understanding of the data.
Disadvantages of Distributed Graphs:
- Complexity: Distributed graphs can be complex to implement, especially in large-scale systems.
- Limited Data Types: Distributed graphs are typically limited to storing specific types of data, such as nodes and edges.
- Limited Query Capabilities: Distributed graphs are typically limited in their query capabilities, making them less suitable for more complex queries.
- High Resource Usage: Distributed graphs can be resource-intensive, which can be a disadvantage in systems with limited resources.
- Limited Security: Distributed graphs may not be as secure as other data structures, and it can be easy for hackers to penetrate them and extract sensitive information.
All these distributed data structures are used for real-time event processing, and they all have their own advantages and disadvantages. DHTs provide fast lookups and low latency, distributed queues handle large amounts of data with low latency, distributed tries are useful for large-scale systems, distributed bloom filters are useful for efficient data retrieval and storage, and distributed graphs are useful for large-scale systems.
Share your thoughts in the comments
Please Login to comment...