Difference between Hierarchical and Relational data model
Last Updated :
11 Oct, 2022
1. Hierarchical Data Model :
Hierarchical data model is the oldest type of data model. It was developed by IBM in 1968. It organizes data in a tree-like structure. Hierarchical model consists of the following :
- It contains nodes that are connected by branches.
- Topmost node is called the root node.
- If there are multiple nodes that appear at the top level, then these can be called root segments.
- Each node has exactly one parent.
- One parent may have many children.
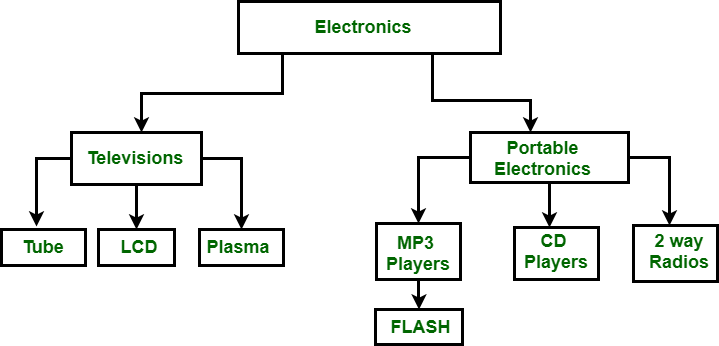
In the above figure, Electronics is the root node which has two children i.e. Television and Portable Electronics. These two has further children for which they act as a parent. For example Television has children as Tube, LCD, and Plasma, for these three Television act as parents. It follows one-to-many relationship.
2. Relational Data Model :
Relational data model was developed by E.F. Codd in 1970. There are no physical links as they are in the hierarchical data model. Following are properties of the relational data model :
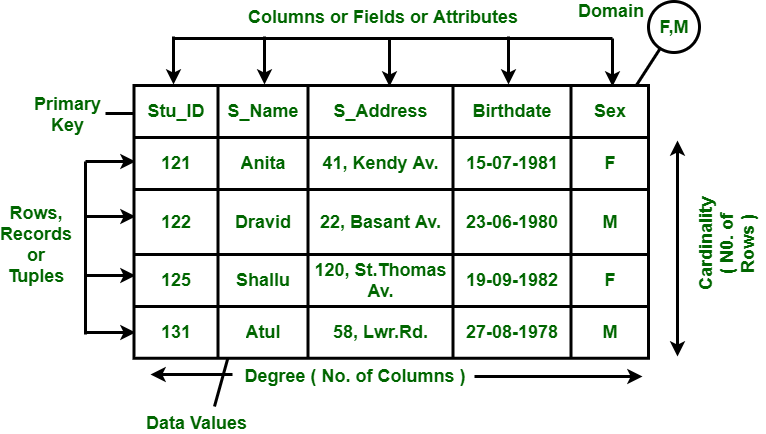
- Data is represented in form of a table only.
- It deals only with data, not with physical structure.
- It provides information regarding metadata.
- At the intersection of row and column there will be only one value for the tuple.
- It provides a way to handle queries with ease.
Difference between Hierarchical and Relational Data Model:
| S. No. |
Hierarchical Data Model
|
Relational Data Model
|
| 1. |
In this model, to store data hierarchy method is used. It is oldest method. |
It is the most flexible and efficient database model. It is most used database in today. |
| 2. |
It implements 1:1 and 1:n. |
In addition to 1:1 and 1:n, it also implements many to many relationships. |
| 3. |
To organize records, it uses a tree structure. |
To organize records, it uses a table. |
| 4. |
More chances of complexity. |
No chance of complexity. |
| 5. |
There is a lack of declarative query facility. In current times they are being modeled using NoSQL. |
It provides facility of declarative query facility using SQL. |
| 6. |
Records are linked with help of pointers. |
Records are linked with help of rows and columns. |
| 7. |
Insertion anomaly exits in this model i.e. child node cannot be inserted without parent node. |
There is no insertion anomaly. |
| 8. |
Deletion anomaly exists in this model i.e. it is difficult to delete parent node. |
There is no deletion anomaly. |
| 9. |
It is used to access data which is complex and asymmetric. |
It is used to access data which is complex and symmetric. |
| 10. |
This model lacks data independence. |
This model provides data independence. |
| 11. |
This design is used in modern times for faster access of data. This is obtained by trade offs i.e. on giving up on redundancy where the levels(parents to child) are relatively less. |
Due to many to many to many relationship joins take a heavy toll on search with multiple parameter query. |
| 12. |
Complexity leads to difficulty in designing database. |
It is not complex as physical level details are not visible to user. |
| 13. |
It is having an inconsistency problem while updating the records due to multiple instances of a child record. |
The normalization is used to remove the redundancy while updating the records. |
| 14. |
Currently this model is being used in shopping carts and search engine. There are tools that can emulate hierarchical database e.g. Mongodb, firebase |
Most of the traditional software are using relational database common e.g. Oracle dB, MS sql server, IBM DB2 |
Share your thoughts in the comments
Please Login to comment...