Relational databases are a way of storing and managing data in software development. They help you keep your data in order and find it quickly. But to use relational databases well, you need to follow some patterns that solve common problems and make your data work better. In this article, we will look at different patterns for relational databases, and explain how they can help you with specific issues and improve your database performance.

Important Topics for the Design Patterns for Relational Databases
What are relational databases?
Relational databases are a type of database that store data in tables, which consist of rows and columns. Each row represents a record or an entity, and each column represents an attribute or a property of that entity. For example, a table of customers might have columns for name, email, phone number, and address. Each row in the table would have the information for one customer.
Relational databases use a language called SQL (Structured Query Language) to create, manipulate, and query data. SQL allows you to perform operations such as inserting, updating, deleting, and selecting data from tables. You can also join multiple tables together to get data from different sources.
Design Patterns for Relational Databases
1. Single Table Inheritance (STI)
This is a design pattern where a single database table is used to store multiple types of related objects that share common attributes. The relational databases don’t inherently support inheritance. However, STI is a technique used to represent a hierarchy of classes in a single table by using a column that indicates the type of each row.
For example
Suppose we have a table called vehicles that stores information about cars, trucks, and motorcycles. We can use STI to store all the vehicles in one table, with a column called type that specifies the subclass of each vehicle.
Advantages of Single Table Inheritance:
- It is simple and easy to implement.
- It supports polymorphism by simply changing the type of the row.
- It provides fast data access because the data is in one table.
- It facilitates ad-hoc reporting because all of the data is in one table.
The disadvantages of Single Table Inheritance:
- It increases coupling within the class hierarchy because all classes are directly coupled to the same table.
- It can waste space in the database if there are many null columns for attributes that are not shared by all subclasses.
- It can complicate the logic for indicating the type if there is significant overlap between subclasses.
Note: STI is suitable for simple and shallow class hierarchies where there is little or no overlap between subclasses.
Below is the implementation of Single Table Inheritance:
C++
class Animal < ActiveRecord::Base include EnumInheritance
enum species
: { dog : 1, cat : 2 }
def self.inheritance_column_to_class_map
= { dog : 'Dog', cat : 'Cat' }
def self.inheritance_column
= 'species' end
class Dog
< Animal;
end class Cat < Animal;
end
|
code explaination:
- class Animal: Think of this as a blueprint for storing information about animals in a database. It’s like a form with fields for things like the type of animal, its name, and other details.
- enum species: Here, we’re saying that animals can be either a “dog” or a “cat.” We use numbers (1 for dog, 2 for cat) to represent them. It’s like saying “1 means dog” and “2 means cat.”
- def self.inheritance_column_to_class_map: This part connects the names “dog” and “cat” to specific classes. So, if we have a “dog,” it’s connected to a class called “Dog,” and if it’s a “cat,” it’s linked to a class called “Cat.”
- def self.inheritance_column: This tells our system that we’ll use the “species” to figure out if an animal is a dog or a cat. It’s like a label on a box that says what’s inside.
- class Dog < Animal; end and class Cat < Animal; These lines create special instructions for our system. They say, “If it’s a dog, treat it like an ‘Animal,’ but also follow the rules for a ‘Dog’.” The same goes for cats – they’re animals too, but they also have their own cat rules.
2. Class Table Inheritance (CTI)
This is a design pattern where each class in a hierarchy has its own database table, and the tables are linked by foreign keys. The relational databases don’t inherently support inheritance. However, CTI is a technique used to represent a hierarchy of classes in multiple tables by using inheritance relationships between tables.
For example
Suppose we have a table called vehicles that stores information about vehicles, and two tables called cars and trucks that store information about specific types of vehicles. We can use CTI to store all the vehicles in separate tables, with foreign keys that reference the parent table.
Advantages of the Class Table Inheritance are
- It preserves data integrity and consistency by using foreign keys and constraints.
- It avoids wasting space in the database by storing only relevant attributes for each subclass.
- It allows adding new subclasses easily by creating new tables.
Disadvantages of the Class Table Inheritance are
- It complicates data access and manipulation by requiring joins or unions between tables.
- It reduces performance and scalability by increasing the number of queries and joins.
- It makes ad-hoc reporting difficult because the data is spread across multiple tables.
Note: CTI is suitable for complex and deep class hierarchies where there is significant difference between subclasses.
CTI diagram:
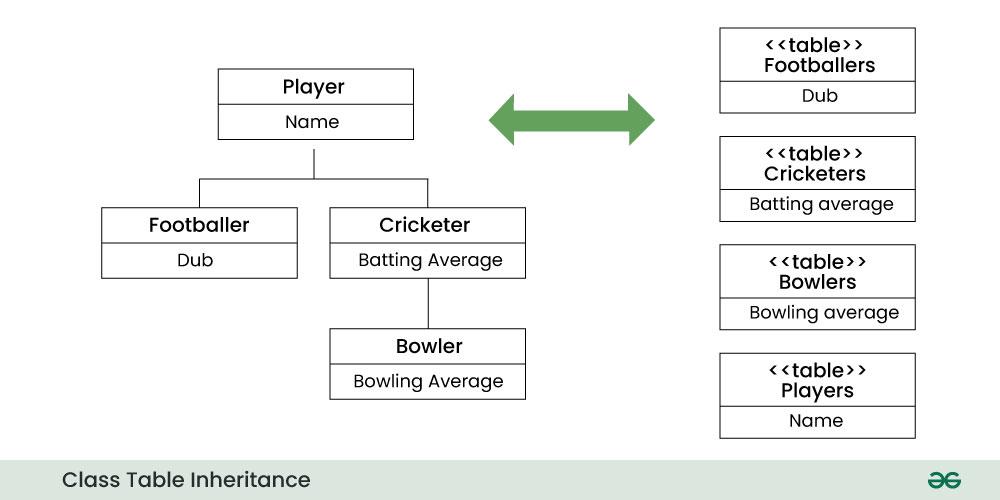
Below is the explanation of the above diagram:
- The diagram shows three tables: Footballers, Cricketers, and Players. Each table has a primary key, which is a field that uniquely identifies each record in the table. The primary key is shown with an underline in the diagram. The tables also have foreign keys, which are fields that reference the primary key of another table. The foreign keys are shown with an arrow in the diagram.
- The Footballers table has fields for the player’s name and club. The name field is the primary key of the table, and it references the name field of the Players table. The club field stores the name of the football club that the player belongs to.
- The Cricketers table has fields for the player’s name, batting average, and bowling average. The name field is the primary key of the table, and it references the name field of the Players table. The batting average field stores the number of runs scored by the player per innings in cricket. The bowling average field stores the number of runs conceded by the player per wicket taken in cricket.
- The Players table has fields for the player’s name and sport. The name field is the primary key of the table, and it stores the full name of the player. The sport field stores the name of the sport that the player plays, such as football or cricket.
3. Entity-Attribute-Value (EAV)
This is a design pattern where each entity is represented by a set of attribute-value pairs, instead of having a fixed schema with predefined columns. The relational databases are based on a rigid structure that requires defining the attributes and data types of each entity beforehand. However, EAV is a technique used to represent entities with dynamic and variable attributes in a flexible way by using three tables: one for entities, one for attributes, and one for values.
For example
Suppose we have a table called products that stores information about products, and we want to store different attributes for different types of products, such as color, size, weight, etc. We can use EAV to store all the products and their attributes in three tables, with foreign keys that link them together. The tables might look like this:
Advantages of the Entity-Attribute-Value
- It provides a flexible and dynamic schema that can accommodate any number and type of attributes for each entity.
- It allows adding new attributes easily by inserting new rows in the attribute table.
- It supports sparse data by storing only the relevant attributes for each entity.
Disadvantages of the Entity-Attribute-Value
- It violates the normal form and the relational model by storing data in a non-tabular format.
- It complicates data access and manipulation by requiring complex queries and joins between tables.
- It reduces performance and scalability by increasing the size and number of tables and indexes.
- It makes data validation and integrity difficult by storing values as strings without data types or constraints.
Note: EAV is suitable for scenarios where the entities have unpredictable and heterogeneous attributes that change frequently.
EAV diagram:
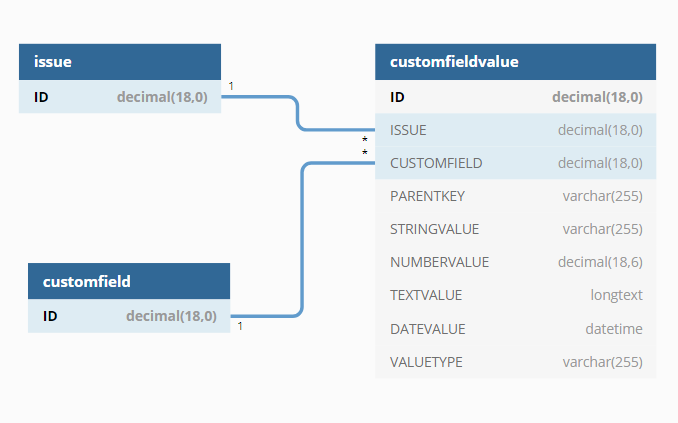
Below is the explanation of the above diagram:
- The image shows three tables: issue, customfieldvalue, and customfield. Each table has a primary key, which is a field that uniquely identifies each record in the table.
- The primary key is shown with an underline in the image. The tables also have foreign keys, which are fields that reference the primary key of another table. The foreign keys are shown with an arrow in the image.
- The issue table has two fields: ID and decimal(18,0). The ID field is the primary key of the table, and it stores a unique number for each issue. The decimal(18,0) field stores the ID of the custom field that is associated with the issue.
- The customfieldvalue table has six fields: ID, decimal(18,0), CUSTOMFIELD, PARENTKEY, STRINGVALUE, NUMBERVALUE, TEXTVALUE, and VALUETYPE. The ID field is the primary key of the table, and it stores a unique number for each custom field value.
- The decimal(18,0) field stores the ID of the issue that has the custom field value. The CUSTOMFIELD field stores the ID of the custom field that defines the custom field value. The PARENTKEY field stores the ID of the parent custom field value, if any.
- The STRINGVALUE, NUMBERVALUE, and TEXTVALUE fields store the actual value of the custom field value, depending on its data type. The VALUETYPE field stores the data type of the custom field value, such as string, number, or text.
- The customfield table has two fields: ID and decimal(18,0). The ID field is the primary key of the table, and it stores a unique number for each custom field. The decimal(18,0) field stores the name of the custom field.
The image shows how the tables are related to each other with arrows. The arrows indicate that there is a one-to-many relationship between the issue and customfieldvalue tables, and between the customfield and customfieldvalue tables. This means that each record in the issue or customfield table can have multiple records in the customfieldvalue table, but each record in the customfieldvalue table can have only one record in the issue or customfield table.
For example, if there is a record for issue 1 in the issue table, there can be multiple records for issue 1 in the customfieldvalue table with different values for different custom fields.
4. Composite Key
This is a design pattern where a combination of two or more columns is used to uniquely identify each row in a table, instead of having a single column as the primary key. The relational databases require defining a primary key for each table, which is a column or a set of columns that can distinguish each row from others. However, composite key is a technique used to create a primary key from multiple columns that together form a unique value for each row.
For example
Suppose we have a table called enrollments that stores information about students enrolled in courses, and we want to use both the student ID and the course ID as the primary key, because each student can enroll in multiple courses, and each course can have multiple students. We can use composite key to create a primary key from the two columns, which ensures that there are no duplicate enrollments in the table.
Advantages of the composite key:
- It avoids creating unnecessary or artificial columns for primary keys, such as auto-incremented numbers or UUIDs.
- It enforces data integrity and consistency by preventing duplicate or invalid data from entering the table.
- It supports natural relationships between entities by using meaningful columns as primary keys.
Disdvantages of the composite key:
- It increases the complexity and length of the primary key, which can affect the performance and readability of queries and joins.
- It requires updating multiple columns when changing the primary key value, which can cause cascading effects on other tables that reference it.
- It can cause problems with some ORM frameworks or tools that expect a single column as the primary key.
Note: Composite key is suitable for scenarios where there is no single column that can uniquely identify each row in a table, but there is a combination of columns that can do so.
Composite key diagram:
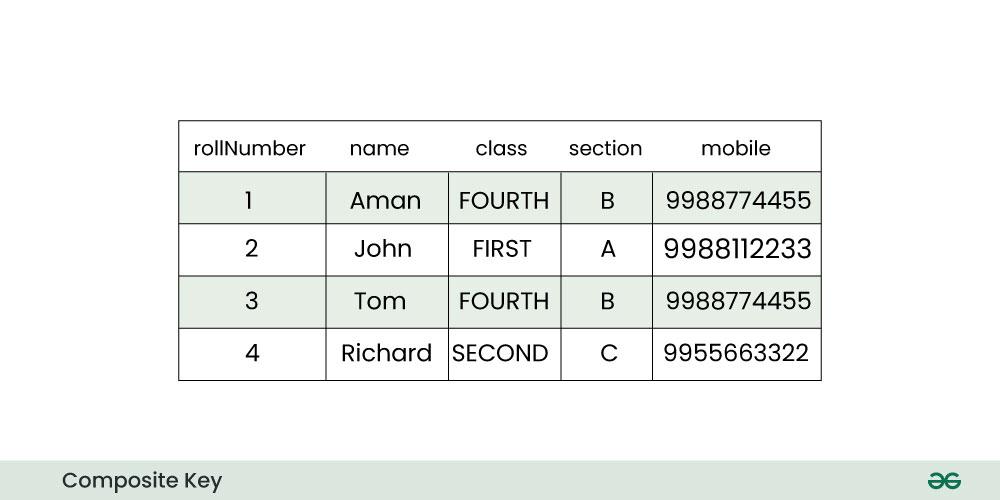
Below is the explanation of the above diagram:
- The example shows a table with five columns: rollNumber, name, class, section, and mobile. The table has four rows, each representing a different student. The rollNumber column is an integer, the name column is a string, the class column is a string, the section column is a string, and the mobile column is an integer. The table is sorted by rollNumber in ascending order.
- The example shows how the composite key works by using the values of the five columns to identify each student.
5. Multipart Index
This is a design pattern where an index is created on two or more columns of a table, instead of having an index on a single column. The relational databases use indexes to speed up data access and manipulation by creating sorted structures or pointers that reference the rows in a table. However, multipart index is a technique used to create an index on multiple columns that together form a search criterion for queries or joins.
For example
Suppose we have a table called orders that stores information about orders placed by customers, and we want to query or join the table by using both the customer_id and the order_date as filters. We can create a multipart index on these two columns like this:
CREATE INDEX idx_orders_customer_date ON orders (customer_id, order_date);
Note: This index will allow us to quickly find all the orders for a given customer and date range, without scanning the entire table.
6. Materialized View
A materialized view is a pre-computed data set that is derived from a query and stored for later use. It can improve the performance of queries that use the same subquery results repeatedly, or that are complex or run on large data sets. A materialized view is updated automatically or on demand when the source data changes, so it always reflects the current state of the data. A materialized view is a type of cache that can be disposed and rebuilt from the source data.
Below is the diagram of the materialized view:

The image shows two groups of tables, Group A and Group B, that are related to each other by some foreign keys. The tables are represented as cylinders and the relationships between them are represented as arrows. The image also shows a Master Site and a Materialized View Site. The Master Site is the original source of the data, where the tables are stored and updated. The Materialized View Site is the destination of the data, where the materialized view is created and refreshed.
The materialized view is created by selecting data from one or more base tables in the Master Site and storing them in a new table in the Materialized View Site. The materialized view can then be queried like a regular table, without having to access the base tables every time. The materialized view can also be refreshed periodically or on demand, to reflect the changes in the base tables.
7. Many-to-Many Relationship
A many-to-many relationship is a type of relationship between two entities in a database, where each entity can be associated with multiple instances of the other entity.
For example
A student can enroll in multiple courses, and a course can have multiple students. To represent a many-to-many relationship in a relational database, you need to create a third table that stores the associations between the two entities, using foreign keys that reference the primary keys of the original tables.
Below is the diagram for a Many-to-Many relationship
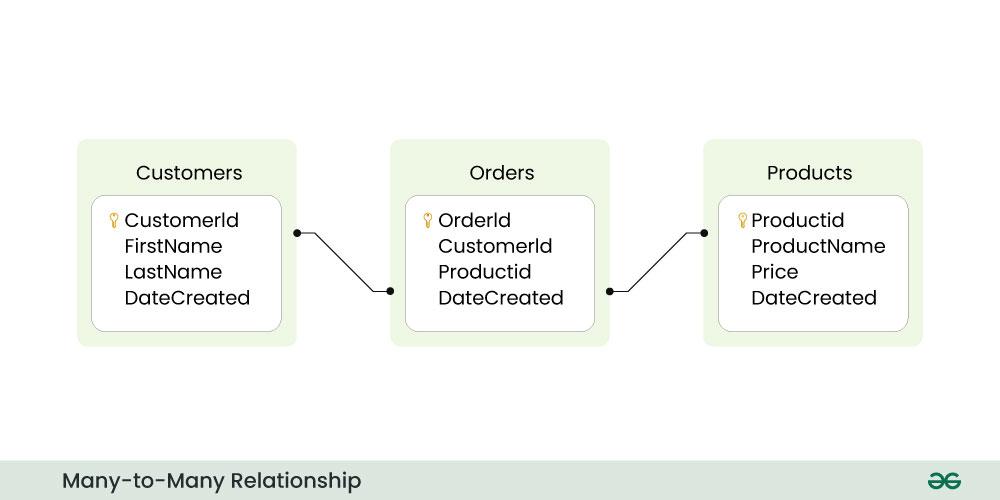
Below is the explanation of the above diagram:
- The diagram explains the many-to-many relationship between three tables: Customers, Orders, and Products. In this relationship, each customer can have multiple orders, and each order can have multiple products. This is represented by the lines connecting the three tables.
- The diagram shows the following information about the tables and their relationships:
- The Customers table has four fields: CustomerId, FirstName, LastName, and DateCreated. The CustomerId field is the primary key of the table, which means it uniquely identifies each row in the table. The FirstName and LastName fields store the first and last name of each customer. The DateCreated field stores the date when the customer record was created.
- The Orders table has four fields: OrderId, CustomerId, ProductId, and DateCreated. The OrderId field is the primary key of the table, which means it uniquely identifies each row in the table. The CustomerId and ProductId fields are foreign keys of the table, which means they reference the primary keys of other tables.
- The CustomerId field references the CustomerId field of the Customers table, which means it indicates which customer placed the order.
- The ProductId field references the ProductId field of the Products table, which means it indicates which product was ordered. The DateCreated field stores the date when the order record was created.
- The Products table has four fields: ProductId, ProductName, Price, and DateCreated. The ProductId field is the primary key of the table, which means it uniquely identifies each row in the table. The ProductName field stores the name of each product. The Price field stores the price of each product. The DateCreated field stores the date when the product record was created.
The relationship between the Customers and Orders tables is a one-to-many relationship, which means that one customer can place multiple orders, but each order can only belong to one customer. This is indicated by the line connecting the tables with a 1 on one end and a N on the other end.
8. Caching
Caching is a technique of storing frequently used or recently accessed data in memory or disk, to reduce latency and workload. Caching can improve the performance and scalability of applications that need to access data from remote or slow sources, such as databases or web services. Caching can also reduce the cost of data access by minimizing network traffic and resource consumption. Caching can be implemented at different levels, such as application level, database level, or network level.
For example
Suppose you have a web application that queries a database server for product information. You can cache some of the query results in the local memory or disk of the web server, so that subsequent requests for the same data can be served faster without hitting the database server again.
10. Queueing
Queueing is a technique of storing data or tasks in a buffer or list, to process them sequentially or asynchronously. Queueing can help manage concurrency and load balancing, by distributing work among multiple workers or threads. Queueing can also help improve reliability and fault tolerance, by ensuring that data or tasks are not lost or duplicated in case of failures or interruptions. Queueing can be implemented using various technologies, such as message brokers, message queues, or distributed streaming platforms.
For example
Suppose you have an application that sends email notifications to users based on some events or triggers. You can use queueing to store the email messages in a queue, and have a separate service or process that consumes the messages from the queue and sends them to the users. This way, you can decouple the email sending logic from the main application logic, and handle the email delivery more efficiently and reliably.
11. Audit Log
An audit log is a record of events or actions that occur in a system or application, such as user activities, system changes, security incidents, or errors. An audit log can help monitor and track the behavior and performance of a system or application, by providing information such as who did what, when, where, and why. An audit log can also help troubleshoot and debug issues, by providing details and context about the events or actions. An audit log can be stored in various formats and locations, such as text files, databases, or cloud services.
For example
Suppose you have a web application that allows users to perform various operations on their accounts, such as login, logout, update profile, change password, etc. You can create an audit log that records each operation performed by each user, along with the timestamp, IP address, browser type, and other relevant information. This way, you can keep track of the user activities and identify any suspicious or malicious behavior.
12. Versioning
Versioning is a technique of managing changes or updates to data or code, by creating and maintaining multiple versions or snapshots of the data or code. Versioning can help preserve the history and evolution of the data or code, by providing information such as who made what changes, when, where, and why. Versioning can also help compare and restore different versions or snapshots of the data or code, by providing tools and mechanisms for diffing and merging. Versioning can be implemented using various technologies and tools, such as version control systems, backup systems, or database features.
For example
Suppose you have a database that stores information about products, such as name, description, price, etc. You want to keep track of the changes made to the product information over time, and be able to revert to previous versions if needed. You can use versioning to store each update to the product information as a new version or snapshot in the database, along with the timestamp, user ID, and other relevant information. This way, you can see the history and evolution of the product information and restore any version if needed.
Share your thoughts in the comments
Please Login to comment...