Compare Pandas Dataframes using DataComPy
Last Updated :
04 May, 2020
It’s well known that Python is a multi-paradigm, general-purpose language that is widely used for data analytics because of its extensive library support and an active community. The most commonly known methods to compare two Pandas dataframes using python are:
These methods are widely in use by seasoned and new developers but what if we require a report to find all of the matching/mismatching columns & rows? Here’s when the DataComPy library comes into the picture.
DataComPy is a Pandas library open-sourced by capitalone. It was started with an aim to replace PROC COMPARE for Pandas data frames. It takes two dataframes as input and gives us a human-readable report containing statistics that lets us know the similarities and dissimilarities between the two dataframes.
Install via pip3:
pip3 install datacompy
Example:
from io import StringIO
import pandas as pd
import datacompy
data1 =
data2 =
df1 = pd.read_csv(StringIO(data1))
df2 = pd.read_csv(StringIO(data2))
compare = datacompy.Compare(
df1,
df2,
join_columns = 'employee_id',
abs_tol = 0,
rel_tol = 0,
df1_name = 'Original',
df2_name = 'New'
)
compare.matches(ignore_extra_columns = False)
print(compare.report())
|
Output:
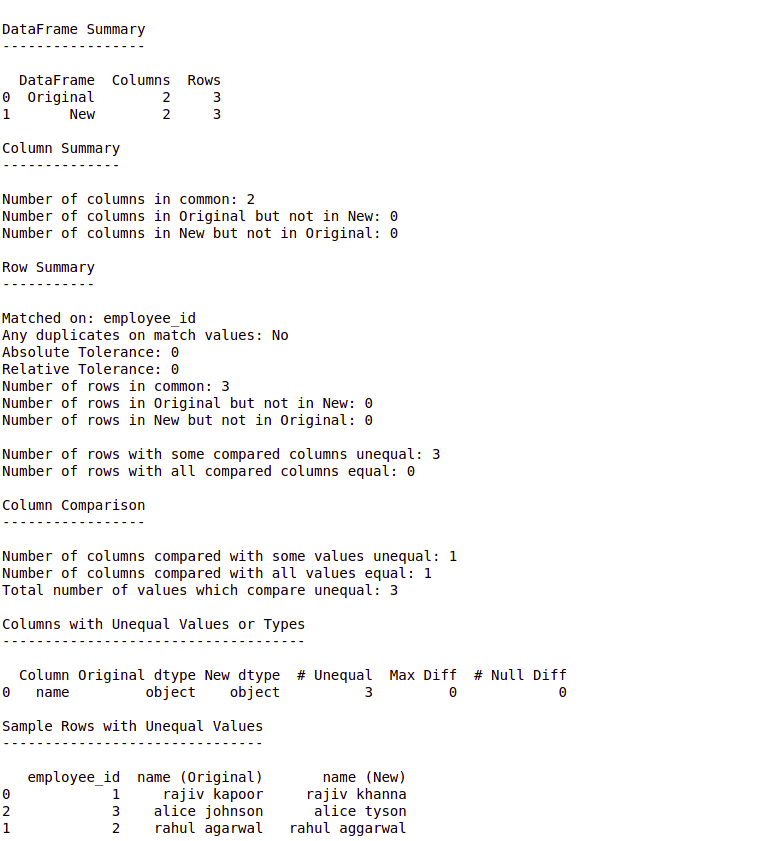
Explanation:
- In the above example, we are joining the two data frames on a matching column. We can also pass:
on_index = True instead of “join_columns” to join on the index instead.
Compare.matches() is a Boolean function. It returns True if there’s a match, else it returns False.
- DataComPy by default returns True only if there’s a 100% match. We can tweak this by setting the values of abs_tol & rel_tol to non-zero, which empowers us to specify an amount of deviation between numeric values that can be tolerated. They stand for absolute tolerance and relative tolerance respectively.
- We can see from the above example that DataComPy is a really powerful library & it is extremely helpful in cases when we have to generate a comparison report of 2 dataframes.
Share your thoughts in the comments
Please Login to comment...