LangChain is a Python module that allows you to develop applications powered by language models. It provides a framework for connecting language models to other data sources and interacting with various APIs. LangChain is designed to be easy to use, even for developers who are not familiar with language models.
How does Langchain work?
LangChain works by providing a set of abstractions that make it easy to interact with language models. These abstractions include:
- Agents: Agents are the core components of LangChain. They are responsible for carrying out specific tasks, such as text generation, summarization, and question answering.
- Memories: Memories are used to store the state between calls to an agent. This allows agents to learn from their previous interactions and make better decisions in the future.
- Chains: Chains are sequences of agents that are used to accomplish specific tasks. For example, a chain could be used to summarize a long piece of text or to answer a question about a specific topic.
Why use LangChain?
There are a few reasons why you might want to use LangChain:
- Ease of use: LangChain is designed to be easy to use, even for developers who are not familiar with language models.
- Flexibility: LangChain provides a flexible framework that can be used to develop a wide variety of applications.
- Extensibility: LangChain is extensible, so you can add your own agents and chains to the framework.
To get started with LangChain, you will need to install the LangChain module. You can do this by running the following command:
! pip install langchain
Modules in Langchain
Langchain offers a variety of modules that can be used to develop applications powered by language models. Some of them include:
Models:
“Models” predominantly refers to Large Language Models (LLMs). These LLMs are characterized by their substantial size, consisting of neural networks with numerous parameters, and being trained on extensive amounts of
unlabeled text data. Several prominent LLMs have been developed by tech giants, including:
- BERT, created by Google
- GPT-3, ChatGPT developed by OpenAI
- LaMDA, also by Google
- PaLM, another creation by Google
- LLaMA, an LLM by Meta AI
- GPT-4, the successor to GPT-3, again by OpenAI, and many more
Python
from langchain.llms import OpenAI
import os
os.environ['OPENAI_API_KEY'] = 'Enter your openAI API key'
model = OpenAI(temperature=0.6)
prompt = model("Tell me a joke")
print(prompt)
|
Output:
Q: What did the fish say when he hit the wall?
A: Dam!
Prompt :
Prompts are a powerful tool for creating prompts that are dynamically generated based on user input, other non-static information, and a fixed template string. They are used in a variety of applications, such as:
- Chatbots: Prompt templates can be used to create chatbots that can understand user input and generate responses that are relevant to the user’s query.
- Question-answering systems: Prompts can be used to create question-answering systems that can answer user questions in a comprehensive and informative way.
- Text summarization: Prompt templates can be used to create text summarization systems that can automatically summarize long pieces of text.
- Code generation: They can be used to create code generation systems that can automatically generate code from natural language descriptions.
- Natural language inference: Prompts/Prompt Templates can be used to create natural language inference systems that can determine the relationship between two statements.
Once you have a good prompt, you may want to use it as a template for other purposes. Thus, LangChain provides you with so-called PromptTemplates, which help you construct prompts from multiple components.
Example:
Python
from langchain import PromptTemplate
template = "{name} is my favourite course at GFG"
prompt = PromptTemplate(
input_variables=["name"],
template=template,
)
example = prompt.format(name="Data Structures and Algorithms")
print(example)
|
Output:
Data Structures and Algorithms is my favourite course at GFG
Memory:
In LangChain, memory is a way of keeping track of the state of a conversation. This can be used to improve the performance of language models by providing them with context from previous messages.
There are many different ways to implement memory in LangChain. Some of the most common methods include:
- Buffer memory: This is the simplest form of memory, and it simply stores a buffer of all previous messages.
- Summary memory: This type of memory stores a summary of the conversation history, such as the most recent N messages or a list of keywords that have been mentioned.
- Seq2seq memory: This type of memory uses a sequence-to-sequence model to learn a representation of the conversation history. This representation can then be used to improve the performance of language models on downstream tasks, such as question answering and summarization.
The choice of which memory type to use depends on the specific application. For example, buffer memory is a good choice for applications where it is important to keep track of the exact order of messages, while summary memory is a good choice for applications where it is more important to focus on the overall content of the conversation.
ChatMessageHistory:
ChatMessageHistory class is one of the important classes in the modules of langchain. It is a convenient lightweight wrapper which is helpful in saving Human and AI messages and then fetching them all.
NOTE: This class is generally used if you are trying to manage the memory outside of a Chain
Example:
Python
from langchain.memory import ChatMessageHistory
chat_history = ChatMessageHistory()
chat_history.add_user_message("Can you give me the solution for 10+10")
chat_history.add_ai_message("The Solution is 10+10=20")
chat_history.add_user_message("Thank You")
print(chat_history.messages)
|
Output:
[HumanMessage(content='Can you give me the solution for 10+10', additional_kwargs={}, example=False), AIMessage(content='The Solution is 10+10=20', additional_kwargs={}, example=False), HumanMessage(content='Thank You', additional_kwargs={}, example=False)]
ConversationBufferMemory:
This class is a wrapper over ChatMessageHistory class and extracts messages in a variable.
Example:
Python
from langchain.memory import ConversationBufferMemory
buff_memory = ConversationBufferMemory()
buff_memory.chat_memory.add_user_message("Can you give me the solution for 10+10")
buff_memory.chat_memory.add_ai_message("he Solution is 10+10=20")
buff_memory.chat_memory.add_user_message("ThankYou")
print(buff_memory.load_memory_variables)
|
Output:
<bound method ConversationBufferMemory.load_memory_variables of ConversationBufferMemory(chat_memory=ChatMessageHistory(messages=[HumanMessage(content='Can you give me the solution for 10+10', additional_kwargs={}, example=False), AIMessage(content='he Solution is 10+10=20', additional_kwargs={}, example=False), HumanMessage(content='ThankYou', additional_kwargs={}, example=False)]), output_key=None, input_key=None, return_messages=False, human_prefix='Human', ai_prefix='AI', memory_key='history')>
CHAINS & AGENTS :
Sometimes, a single API call to an LLM is not enough to solve a task. For example, you might need to get information from Wikipedia and then give that information as input to the model. This module in LangChain allows you to chain together multiple tools in order to solve complex tasks. For example, you could create a chain that first gets information about a topic from Wikipedia, then uses that information to generate a title for a YouTube video, and finally uses that title to generate a script for the video. Chains make it easy to combine multiple tools to solve complex tasks. This can be a powerful way to use LLMs to generate text that is both informative and engaging.
Example:
Python
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
import os
os.environ['OPENAI_API_KEY'] = 'Enter your api key'
model = OpenAI(temperature=0)
chain = ConversationChain(llm=model,
verbose=True,
memory=ConversationBufferMemory()
)
print(chain.predict(input="Can You tell me something about GeeksForGeeks."))
|
Output:
> Entering new chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Can You tell me something about GeeksForGeeks.
AI:
> Finished chain.
Sure! GeeksForGeeks is an online computer science and programming community. It provides a platform for computer science students and professionals to learn, practice, and discuss programming topics. It also provides tutorials, articles, and coding challenges to help users improve their coding skills.
Some applications require a flexible chain of calls to LLMs and other tools based on user input. The Agent interface provides flexibility for such applications. An agent has access to a suite of tools and determines which ones to use depending on the user input. Agents can use multiple tools, and use the output of one tool as the input to the next.
There are two main types of agents:
- Action agents: at each timestep, decide on the next action using the outputs of all previous actions
- Plan-and-execute agents: decide on the full sequence of actions up front, then execute them all without updating the plan
This module provides a set of agents that can be used. And we will learn precisely about chains and agents by building a project.
Build a mini Chatbot Webapp:
Let us recollect everything that we learnt above and create a web app that uses LangChain to generate YouTube video titles and scripts.
To run the code, you will need to have the following dependencies installed:
! pip install streamlit
! pip install OpenAI
! pip install langchain
! pip install WikipediaAPIWrapper
Step 1:
Python3
import os
os.environ['OPENAI_API_KEY'] = "Enter your API key"
|
It sets the value of the environment variable OPENAI_API_KEY to the your apikey. To get your API key, you should create an OpenAI account and then you can get your own API key. Environment variables are used to store and retrieve configuration values in an operating system. In this case, the API key is stored as an environment variable.
Setting the API key as an environment variable is a common practice when working with APIs or other services that require authentication. By storing the API key as an environment variable, you can access it securely without hardcoding it directly into your code. This helps to keep sensitive information, such as API keys, separate from the codebase, reducing the risk of accidental exposure.
Step 2:
The first line imports the “streamlit” module. This module is used to create a web app. The second line sets the title of the web app to “Geeks For Geeks”. The third line creates a text input field where the user can enter text. The “PromptTemplate” class is used to create prompt templates. A prompt template is a string that is used to generate text. The first prompt template is used to generate a title for a YouTube video. The second prompt template is used to generate a script for a YouTube video. The “input_variables” argument of the “PromptTemplate” class specifies the variables that are used in the prompt template. The concept variable is used to store the user’s input. The “wikipedia_research” variable is used to store the research that is retrieved from Wikipedia. The template argument of the “PromptTemplate” class specifies the text of the prompt template. The template for the title prompt template is “Give me a YouTube video title about {concept}”. The template for the script prompt template is “Give me an attractive YouTube video script based on the title “{title}” while making use of the information and knowledge obtained from the Wikipedia research:{wikipedia_research} “.
Python3
import streamlit as st
st.title('Geeks For Geeks ')
input_text = st.text_input('Enter Your Text: ')
from langchain.prompts import PromptTemplate
title_template = PromptTemplate(
input_variables = ['concept'],
template='Give me a youtube video title about {concept}'
)
script_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template=
)
|
Step 3:
We created two instances of the ConversationBufferMemory class. The “ConversationBufferMemory” class is a class for storing a history of the conversation between the user and the language model. This information can be used to improve the language model’s understanding of the user’s intent and to generate more relevant and coherent responses. The “memoryT” object stores the conversation buffer memory for the title. The memoryS object stores the conversation buffer memory for the script. The input_key argument specifies the variable that is used to store the user’s input. The “memory_key” argument specifies the key that is used to store the conversation buffer in the model.
The LLMChain class is a class for chaining together multiple prompts. This means that the LLMChain object can be used to generate text that is based on multiple prompts. The code then creates two instances of the LLMChain class. The chainT object is used to generate a title based on the user’s input. The “script_chainS” object is used to generate a script based on the title and Wikipedia research. The LLM argument specifies the large language model that is used to generate the text. The prompt argument specifies the prompt template that is used to generate the text. The verbose argument specifies whether or not the LLMChain object should print out information about the generation process. The output_key argument specifies the key that is used to store the generated text in the model. The memory argument specifies the conversation buffer memory that is used to improve the language model’s understanding of the user’s intent.
Python3
memoryT = ConversationBufferMemory(input_key='concept', memory_key='chat_history')
memoryS = ConversationBufferMemory(input_key='title', memory_key='chat_history')
model = OpenAI(temperature=0.6)
chainT = LLMChain(llm=model, prompt=title_template, verbose=True, output_key='title', memory=memoryT)
chainS = LLMChain(llm=model, prompt=script_template, verbose=True, output_key='script', memory=memoryS)
|
Step 4:
We had set up a wrapper or interface to interact with the Wikipedia API. A wrapper is a piece of code that simplifies the usage of a more complex system or service, in this case, the Wikipedia API. It acts as a middle layer that handles communication and makes it easier to perform operations like fetching information from Wikipedia.If the input was given, then it generates a title and Wikipedia research based on that text, generates a script using the title and research, and displays the title, script, and Wikipedia research in an expandable section on a web page created with Streamlit.
Python3
wikipedia = WikipediaAPIWrapper()
if input_text:
title = chainT.run(input_text)
wikipedia_research = wikipedia.run(input_text)
script = chainS.run(title=title, wikipedia_research=wiki_research)
st.write(title)
st.write(script)
with st.expander('Wikipedia-based exploration: '):
st.info(wiki_research)
|
Full Code
Python3
import os
os.environ['OPENAI_API_KEY'] = "Enter the api key"
import streamlit as st
st.title(' Geeks For Geeks ')
input_text = st.text_input('Enter Your Text: ')
from langchain.prompts import PromptTemplate
title_template = PromptTemplate(
input_variables = ['concept'],
template='Give me a youtube video title about {concept}'
)
script_template = PromptTemplate(
input_variables = ['title', 'wikipedia_research'],
template=
)
from langchain.memory import ConversationBufferMemory
memoryT = ConversationBufferMemory(input_key='concept', memory_key='chat_history')
memoryS = ConversationBufferMemory(input_key='title', memory_key='chat_history')
from langchain.llms import OpenAI
model = OpenAI(temperature=0.6)
from langchain.chains import LLMChain
chainT = LLMChain(llm=model, prompt=title_template, verbose=True, output_key='title', memory=memoryT)
chainS = LLMChain(llm=model, prompt=script_template, verbose=True, output_key='script', memory=memoryS)
from langchain.utilities import WikipediaAPIWrapper
wikipedia = WikipediaAPIWrapper()
if input_text:
title = chainT.run(input_text)
wikipedia_research = wikipedia.run(input_text)
script = chainS.run(title=title, wikipedia_research=wikipedia_research)
st.write(title)
st.write(script)
with st.expander('Wikipedia-based exploration: '):
st.info(wikipedia_research)
|
Output:
Warning: to view this Streamlit app on a browser, run it with the following
command:
streamlit run /home/gfg19509@gfg.geeksforgeeks.org/PawanKrGunjan/NLP/LongChain/longchain.py [ARGUMENTS]
To run the web app, You have to run the below command in terminal
streamlit run /home/gfg19509@gfg.geeksforgeeks.org/PawanKrGunjan/NLP/LongChain/longchain.py
Then the web app with start in the default browser like below.
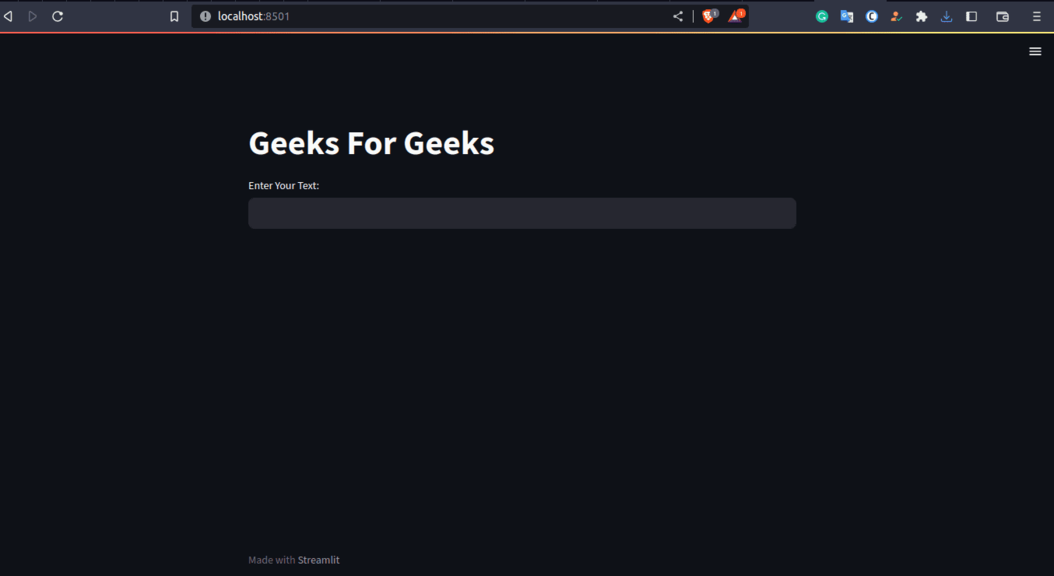
Enter the name to generate the script.
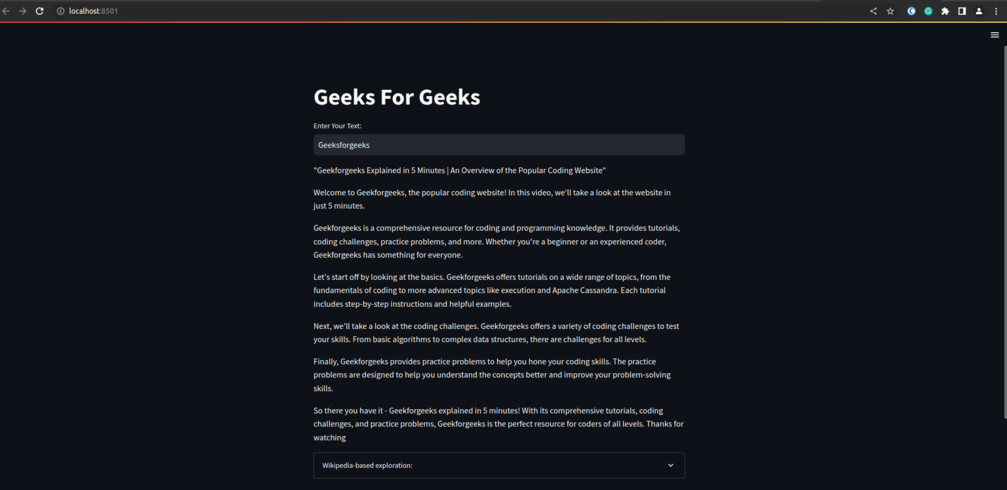
Utilizing Wikipedia’s knowledge :

Conclusion
LangChain is a powerful framework for developing applications powered by language models. It provides a number of features that make it easier to develop applications using language models, such as a standard interface for interacting with language models, a library of pre-built tools for common tasks, and a mechanism for chaining together multiple tools to create complex applications.
Share your thoughts in the comments
Please Login to comment...