What is a Webcrawler and where is it used?
Last Updated :
03 Oct, 2022
Web Crawler is a bot that downloads the content from the internet and indexes it. The main purpose of this bot is to learn about the different web pages on the internet. This kind of bots is mostly operated by search engines. By applying the search algorithms to the data collected by the web crawlers, search engines can provide the relevant links as a response for the request requested by the user. In this article, let’s discuss how the web crawler is implemented.
Webcrawler is a very important application of the Breadth-First Search Algorithm. The idea is that the whole internet can be represented by a directed graph:
- with vertices -> Domains/ URLs/ Websites.
- edges -> Connections.
Example:
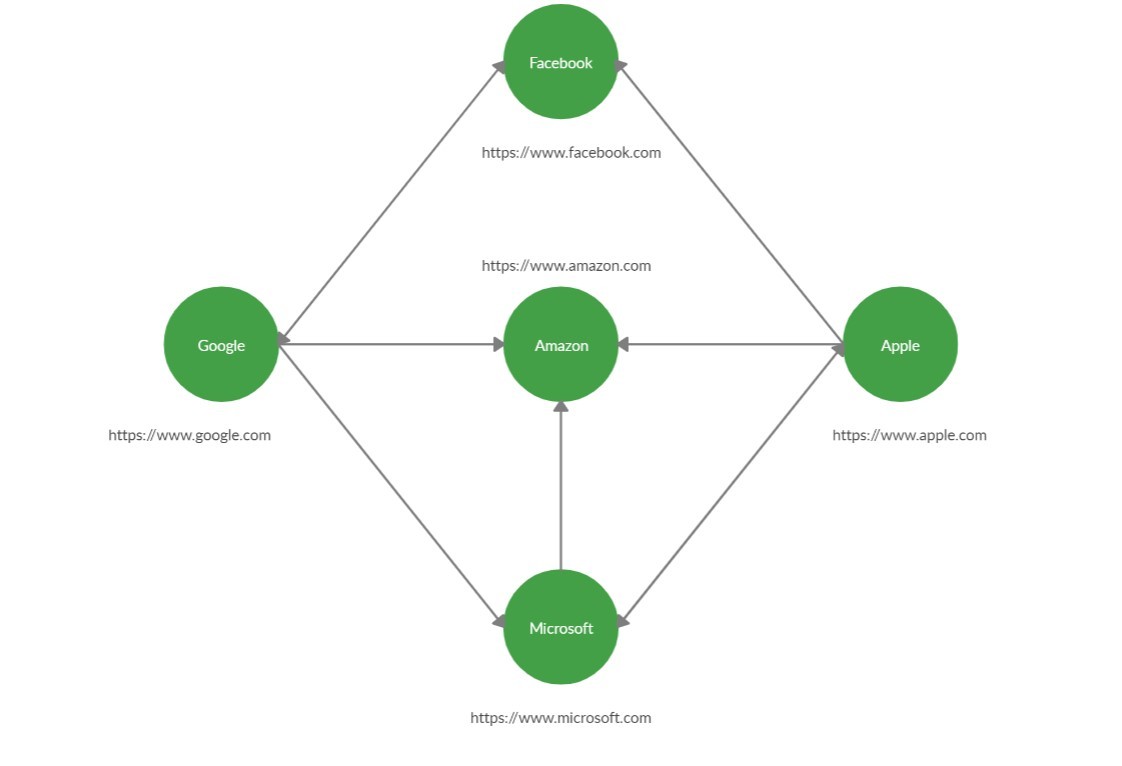
Approach: The idea behind the working of this algorithm is to parse the raw HTML of the website and look for other URL in the obtained data. If there is a URL, then add it to the queue and visit them in breadth-first search manner.
Note: This code will not work on an online IDE due to proxy issues. Try to run on your local computer.
Java
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.util.HashSet;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
class WebCrowler {
/ /FIFO order required for BFS
private Queue<String> queue;
private HashSet<String>
discovered_websites;
public WebCrowler()
{
this.queue
= new LinkedList<>();
this.discovered_websites
= new HashSet<>();
}
public void discover(String root)
{
this.queue.add(root);
this.discovered_websites.add(root);
while (!queue.isEmpty()) {
String v = queue.remove();
String raw = readUrl(v);
String regex
Pattern pattern
= Pattern.compile(regex);
Matcher matcher
= pattern.matcher(raw);
while (matcher.find()) {
String actual = matcher.group();
if (!discovered_websites
.contains(actual)) {
discovered_websites
.add(actual);
System.out.println(
"Website found: "
+ actual);
queue.add(actual);
}
}
}
}
public String readUrl(String v)
{
String raw = "";
try {
URL url = new URL(v);
BufferedReader be
= new BufferedReader(
new InputStreamReader(
url.openStream()));
String input = "";
while ((input
= br.readLine())
!= null) {
raw += input;
}
br.close();
}
catch (Exception ex) {
ex.printStackTrace();
}
return raw;
}
}
public class Main {
public static void main(String[] args)
{
WebCrowler web_crowler
= new WebCrowler();
String root
web_crowler.discover(root);
}
}
|
Output:
Website found: https://www.google.com
Website found: https://www.facebook.com
Website found: https://www.amazon.com
Website found: https://www.microsoft.com
Website found: https://www.apple.com
Problem caused by web crawler: Web crawlers could accidentally flood websites with requests to avoid this inefficiency web crawlers use politeness policies. To implement politeness policy web crawler takes help of two parameters:
- Freshness: As the content on webpages is constantly updated and modified web crawler needs to keep revisiting pages. For that freshness uses HTTP protocol to as HTTP has a special request type called HEAD which returns the information about the last updated date of webpage by which crawler can decide the freshness of a webpage.
- Age: An age of a webpage is T days after it has been last crawled. On average webpage updating follow Poisson distribution and the older a page gets the more costs to crawl the web page so Age is more important factor for crawler than freshness.
Applications: This kind of web crawler is used to acquire the important parameters of the web like:
- What are the frequently visited websites?
- What are the websites that are important in the network as a whole?
- Useful Information on social networks: Facebook, Twitter… etc.
- Who is the most popular person in a group of people?
- Who is the most important software engineer in a company?
Share your thoughts in the comments
Please Login to comment...