Web scraper for extracting emails based on keywords and regions
Last Updated :
02 Nov, 2022
Web scraping is a task that is normally performed to scrape structured data from the websites which are then stored accordingly, this kind of data is valuable enough to open the doors to a variety of fields from data mining-related stuff to the data science related applications where large amounts of data are required to make business decisions.
And as for this article, we are going to discuss how to use web scrapers for extracting emails based on keywords and locations.
So the question arises, why would we need something like that? Well, emails extracted based on specific topics and regions can be a very productive way of doing advertisement and product promotion, though one would say that this could be used for black hat SEO it actually depends on how you use it.
Requirements:
- Scrapy module: It is used as a Python framework for web scraping. Getting data from a normal website is easier, and can be just achieved by just pulling HTML of the website and fetching data by filtering tags. It can be installed using the below command.
pip install scrapy
- Selenium module: It is a powerful tool for controlling a web browser through the program. It is functional for all browsers, works on all major OS and its scripts are written in various languages i.e Python, Java, C#, etc. It can be installed using the below command.
pip install selenium
- Scrapy-Selenium module: It is a scrapy middleware to handle JavaScript pages using selenium. It can be installed using the below command.
pip install scrapy-selenium
- Google module: Using python package google we can get the result of google search from a python script. It can be installed using the below command.
pip install google
Step-by-step Approach:
Step 1: Creating scrapy project with the below command:
scrapy startproject email_extraction
After executing the above command you will see a folder with the tree like this
├── email_extraction
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── __pycache__
│ ├── settings.py
│ └── spiders
│ ├── email_extractor.py
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
4 directories, 8 files
Create a python file in the spiders directory and open it up in any editor.
Step 2: Importing the required libraries
Python3
import scrapy
from scrapy.spiders import CrawlSpider, Request
from googlesearch import search
import re
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
|
Now the required libraries have been imported we can get to the next step of our script.
Step 3: Setting up required parameters for the crawler
Python3
class email_extractor(CrawlSpider):
name = 'email_ex'
def __init__(self, *args, **kwargs):
super(email_extractor, self).__init__(*args, **kwargs)
self.email_list = []
self.query = " 'market places'.gmail.com "
|
In this we are creating class email_extractor and inheriting CrawlSpider class from the scrapy module, in the next line we are giving a unique name to our crawler which we will use later to run our spider, we don’t need to set allowed domain parameter as we will be jumping from one website domain to the other for extracting emails then we are creating a python constructor and declaring a list and a string variable, the string value given here is going to be fed to the google search engine which is our actual query defining keyword (health), location (usa) and .gmail.com for getting email oriented search results.
Step 4: Getting results and sending requests
Python3
def start_requests(self):
for results in search(self.query, num=10, stop=None, pause=2):
yield SeleniumRequest(
url=results,
callback=self.parse,
wait_until=EC.presence_of_element_located(
(By.TAG_NAME, "html")),
dont_filter=True
)
|
Here, we are creating our method start_requests then we are using search() method from googlesearch module with parameters of
- query variable which has the actual search query that we declared before.
- 10 results after every 2 seconds of pause.
- We are getting all the results there exist for the query with the stop parameter set to None.
After that, we are yielding a request with the method SeleniumRequest from scrapy_selenium module with parameters of:
- Getting the first URL sequentially from the search results.
- Calling back a method for each URL for further processing which we will see in a minute.
- Using wait_until parameter for checking whether the tag with the name html has appeared on the web page or not, it will keep on checking until it appears on the web page.
- The don’t_filter set as True will allow the revisiting of the website with the same domain name.
Step 5: Extracting emails from the main page of each website
Python3
def parse(self, response):
EMAIL_REGEX = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
emails = re.finditer(EMAIL_REGEX, str(response.text))
for email in emails:
self.email_list.append(email.group())
for email in set(self.email_list):
yield{
"emails": email
}
self.email_list.clear()
|
In this step we are creating a method called parse() with the parameter response for getting request object from the start_request method, in the next line we are creating our regular expression system for parsing out the emails from the response HTML then we are appending the emails in the email_list list variable which we declared in the constructor method, and then we are iterating over the set and yielding a dictionary where emails is key or column header and email is an iterator or relative email value and at the very last we are clearing the list so that no duplicate values are written to the file when we start the crawler.
Below is the complete program based on the above approach:
Python3
import scrapy
from scrapy.spiders import CrawlSpider, Request
from googlesearch import search
import re
from scrapy_selenium import SeleniumRequest
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
class email_extractor(CrawlSpider):
name = 'email_ex'
def __init__(self, *args, **kwargs):
super(email_extractor, self).__init__(*args, **kwargs)
self.email_list = []
self.query = " 'market places'.gmail.com "
def start_requests(self):
for results in search(self.query, num=10, stop=None, pause=2):
yield SeleniumRequest(
url=results,
callback=self.parse,
wait_until=EC.presence_of_element_located(
(By.TAG_NAME, "html")),
dont_filter=True
)
def parse(self, response):
EMAIL_REGEX = r'[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+'
emails = re.finditer(EMAIL_REGEX, str(response.text))
for email in emails:
self.email_list.append(email.group())
for email in set(self.email_list):
yield{
"emails": email
}
self.email_list.clear()
|
Now it’s time to run the code, open the terminal and go to the root directory of the project where scrapy.cfg file is located and run this command:
scrapy crawl email_ex -o emails.csv
Scraper will start scraping and storing all the emails to the file emails.csv that is created automatically.
And so the results are:
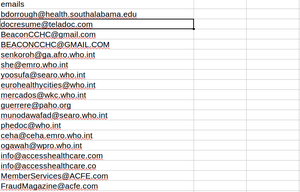
Extracted emails are stored in a csv file
Share your thoughts in the comments
Please Login to comment...