Data Mining is a process of extracting useful information from data warehouses or from bulk data. This article contains the Most Popular and Frequently Asked Interview Questions of Data Mining along with their detailed answers. These will help you to crack any interview for a data scientist job. So let’s get started.

1. What is Data Mining?
Data mining refers to extracting or mining knowledge from large amounts of data. In other words, Data mining is the science, art, and technology of discovering large and complex bodies of data in order to discover useful patterns.
2. What are the different tasks of Data Mining?
The following activities are carried out during data mining:
- Classification
- Clustering
- Association Rule Discovery
- Sequential Pattern Discovery
- Regression
- Deviation Detection
3. Discuss the Life cycle of Data Mining projects?
The life cycle of Data mining projects:
- Business understanding: Understanding projects objectives from a business perspective, data mining problem definition.
- Data understanding: Initial data collection and understand it.
- Data preparation: Constructing the final data set from raw data.
- Modeling: Select and apply data modeling techniques.
- Evaluation: Evaluate model, decide on further deployment.
- Deployment: Create a report, carry out actions based on new insights.
4. Explain the process of KDD?
Data mining treat as a synonym for another popularly used term, Knowledge Discovery from Data, or KDD. In others view data mining as simply an essential step in the process of knowledge discovery, in which intelligent methods are applied in order to extract data patterns.
Knowledge discovery from data consists of the following steps:
- Data cleaning (to remove noise or irrelevant data).
- Data integration (where multiple data sources may be combined).
- Data selection (where data relevant to the analysis task are retrieved from the database).
- Data transformation (where data are transmuted or consolidated into forms appropriate for mining by performing summary or aggregation functions, for sample).
- Data mining (an important process where intelligent methods are applied in order to extract data patterns).
- Pattern evaluation (to identify the fascinating patterns representing knowledge based on some interestingness measures).
- Knowledge presentation (where knowledge representation and visualization techniques are used to present the mined knowledge to the user).
5. What is Classification?
Classification is the processing of finding a set of models (or functions) that describe and distinguish data classes or concepts, for the purpose of being able to use the model to predict the class of objects whose class label is unknown. Classification can be used for predicting the class label of data items. However, in many applications, one may like to calculate some missing or unavailable data values rather than class labels.
6. Explain Evolution and deviation analysis?
Data evolution analysis describes and models regularities or trends for objects whose behavior variations over time. Although this may involve discrimination, association, classification, characterization, or clustering of time-related data, distinct features of such an analysis involve time-series data analysis, periodicity pattern matching, and similarity-based data analysis.
In the analysis of time-related data, it is often required not only to model the general evolutionary trend of the data but also to identify data deviations that occur over time. Deviations are differences between measured values and corresponding references such as previous values or normative values. A data mining system performing deviation analysis, upon the detection of a set of deviations, may do the following: describe the characteristics of the deviations, try to describe the reason behindhand them, and suggest actions to bring the deviated values back to their expected values.
7. What is Prediction?
Prediction can be viewed as the construction and use of a model to assess the class of an unlabeled object, or to measure the value or value ranges of an attribute that a given object is likely to have. In this interpretation, classification and regression are the two major types of prediction problems where classification is used to predict discrete or nominal values, while regression is used to predict incessant or ordered values.
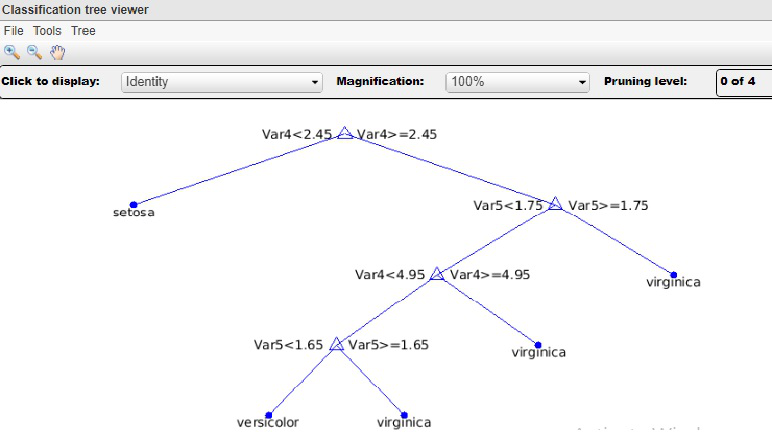
8. Explain the Decision Tree Classifier?
A Decision tree is a flow chart-like tree structure, where each internal node (non-leaf node) denotes a test on an attribute, each branch represents an outcome of the test and each leaf node (or terminal node) holds a class label. The topmost node of a tree is the root node.
A Decision tree is a classification scheme that generates a tree and a set of rules, representing the model of different classes, from a given data set. The set of records available for developing classification methods is generally divided into two disjoint subsets namely a training set and a test set. The former is used for originating the classifier while the latter is used to measure the accuracy of the classifier. The accuracy of the classifier is determined by the percentage of the test examples that are correctly classified.
In the decision tree classifier, we categorize the attributes of the records into two different types. Attributes whose domain is numerical are called the numerical attributes and the attributes whose domain is not numerical are called categorical attributes. There is one distinguished attribute called a class label. The goal of classification is to build a concise model that can be used to predict the class of the records whose class label is unknown. Decision trees can simply be converted to classification rules.
9. What are the advantages of a decision tree classifier?
- Decision trees are able to produce understandable rules.
- They are able to handle both numerical and categorical attributes.
- They are easy to understand.
- Once a decision tree model has been built, classifying a test record is extremely fast.
- Decision tree depiction is rich enough to represent any discrete value classifier.
- Decision trees can handle datasets that may have errors.
- Decision trees can deal with handle datasets that may have missing values.
- They do not require any prior assumptions. Decision trees are self-explanatory and when compacted they are also easy to follow. That is to say, if the decision tree has a reasonable number of leaves it can be grasped by non-professional users. Furthermore, since decision trees can be converted to a set of rules, this sort of representation is considered comprehensible.
10. Explain Bayesian classification in Data Mining?
A Bayesian classifier is a statistical classifier. They can predict class membership probabilities, for instance, the probability that a given sample belongs to a particular class. Bayesian classification is created on the Bayes theorem. A simple Bayesian classifier is known as the naive Bayesian classifier to be comparable in performance with decision trees and neural network classifiers. Bayesian classifiers have also displayed high accuracy and speed when applied to large databases.
11. Why Fuzzy logic is an important area for Data Mining?
Rule-based systems for classification have the disadvantage that they involve exact values for continuous attributes. Fuzzy logic is useful for data mining systems performing classification. It provides the benefit of working at a high level of abstraction. In general, the usage of fuzzy logic in rule-based systems involves the following:
- Attribute values are changed to fuzzy values.
- For a given new sample, more than one fuzzy rule may apply. Every applicable rule contributes a vote for membership in the categories. Typically, the truth values for each projected category are summed.
- The sums obtained above are combined into a value that is returned by the system. This process may be done by weighting each category by its truth sum and multiplying by the mean truth value of each category. The calculations involved may be more complex, depending on the difficulty of the fuzzy membership graphs.
12. What are Neural networks?
A neural network is a set of connected input/output units where each connection has a weight associated with it. During the knowledge phase, the network acquires by adjusting the weights to be able to predict the correct class label of the input samples. Neural network learning is also denoted as connectionist learning due to the connections between units. Neural networks involve long training times and are therefore more appropriate for applications where this is feasible. They require a number of parameters that are typically best determined empirically, such as the network topology or “structure”. Neural networks have been criticized for their poor interpretability since it is difficult for humans to take the symbolic meaning behind the learned weights. These features firstly made neural networks less desirable for data mining.
The advantages of neural networks, however, contain their high tolerance to noisy data as well as their ability to classify patterns on which they have not been trained. In addition, several algorithms have newly been developed for the extraction of rules from trained neural networks. These issues contribute to the usefulness of neural networks for classification in data mining. The most popular neural network algorithm is the backpropagation algorithm, proposed in the 1980s
13. How Backpropagation Network Works?
A Backpropagation learns by iteratively processing a set of training samples, comparing the network’s estimate for each sample with the actual known class label. For each training sample, weights are modified to minimize the mean squared error between the network’s prediction and the actual class. These changes are made in the “backward” direction, i.e., from the output layer, through each concealed layer down to the first hidden layer (hence the name backpropagation). Although it is not guaranteed, in general, the weights will finally converge, and the knowledge process stops.
14. What is a Genetic Algorithm?
Genetic algorithm is a part of evolutionary computing which is a rapidly growing area of artificial intelligence. The genetic algorithm is inspired by Darwin’s theory about evolution. Here the solution to a problem solved by the genetic algorithm is evolved. In a genetic algorithm, a population of strings (called chromosomes or the genotype of the gen me), which encode candidate solutions (called individuals, creatures, or phenotypes) to an optimization problem, is evolved toward better solutions. Traditionally, solutions are represented in the form of binary strings, composed of 0s and 1s, the same way other encoding schemes can also be applied.
15. What is Classification Accuracy?
Classification accuracy or accuracy of the classifier is determined by the percentage of the test data set examples that are correctly classified. The classification accuracy of a classification tree = (1 – Generalization error).
16. Define Clustering in Data Mining?
Clustering is the task of dividing the population or data points into a number of groups such that data points in the same groups are more similar to other data points in the same group and dissimilar to the data points in other groups. It is basically a collection of objects on the basis of similarity and dissimilarity between them.
17. Write a difference between classification and clustering?[IMP]
| Parameters |
CLASSIFICATION |
CLUSTERING |
| Type |
Used for supervised need learning |
Used for unsupervised learning |
| Basic |
Process of classifying the input instances based on their corresponding class labels |
Grouping the instances based on their similarity without the help of class labels |
| Need |
It has labels so there is a need for training and testing data set for verifying the model created |
There is no need for training and testing dataset |
| Complexity |
More complex as compared to clustering |
Less complex as compared to classification |
| Example Algorithms |
Logistic regression, Naive Bayes classifier, Support vector machines, etc. |
k-means clustering algorithm, Fuzzy c-means clustering algorithm, Gaussian (EM) clustering algorithm etc. |
18. What is Supervised and Unsupervised Learning?[TCS interview question]
Supervised learning, as the name indicates, has the presence of a supervisor as a teacher. Basically supervised learning is when we teach or train the machine using data that is well labeled. Which means some data is already tagged with the correct answer. After that, the machine is provided with a new set of examples(data) so that the supervised learning algorithm analyses the training data(set of training examples) and produces a correct outcome from labeled data.
Unsupervised learning is the training of a machine using information that is neither classified nor labeled and allowing the algorithm to act on that information without guidance. Here the task of the machine is to group unsorted information according to similarities, patterns, and differences without any prior training of data.
Unlike supervised learning, no teacher is provided that means no training will be given to the machine. Therefore, the machine is restricted to find the hidden structure in unlabeled data by itself.
19. Name areas of applications of data mining?
- Data Mining Applications for Finance
- Healthcare
- Intelligence
- Telecommunication
- Energy
- Retail
- E-commerce
- Supermarkets
- Crime Agencies
- Businesses Benefit from data mining
20. What are the issues in data mining?
A number of issues that need to be addressed by any serious data mining package
- Uncertainty Handling
- Dealing with Missing Values
- Dealing with Noisy data
- Efficiency of algorithms
- Constraining Knowledge Discovered to only Useful
- Incorporating Domain Knowledge
- Size and Complexity of Data
- Data Selection
- Understandably of Discovered Knowledge: Consistency between Data and Discovered Knowledge.
21. Give an introduction to data mining query language?
DBQL or Data Mining Query Language proposed by Han, Fu, Wang, et.al. This language works on the DBMiner data mining system. DBQL queries were based on SQL(Structured Query language). We can this language for databases and data warehouses as well. This query language support ad hoc and interactive data mining.
22. Differentiate Between Data Mining And Data Warehousing?
Data Mining: It is the process of finding patterns and correlations within large data sets to identify relationships between data. Data mining tools allow a business organization to predict customer behavior. Data mining tools are used to build risk models and detect fraud. Data mining is used in market analysis and management, fraud detection, corporate analysis, and risk management.
It is a technology that aggregates structured data from one or more sources so that it can be compared and analyzed rather than transaction processing.
Data Warehouse: A data warehouse is designed to support the management decision-making process by providing a platform for data cleaning, data integration, and data consolidation. A data warehouse contains subject-oriented, integrated, time-variant, and non-volatile data.
Data warehouse consolidates data from many sources while ensuring data quality, consistency, and accuracy. Data warehouse improves system performance by separating analytics processing from transnational databases. Data flows into a data warehouse from the various databases. A data warehouse works by organizing data into a schema that describes the layout and type of data. Query tools analyze the data tables using schema.
23.What is Data Purging?
The term purging can be defined as Erase or Remove. In the context of data mining, data purging is the process of remove, unnecessary data from the database permanently and clean data to maintain its integrity.
24. What Are Cubes?
A data cube stores data in a summarized version which helps in a faster analysis of data. The data is stored in such a way that it allows reporting easily. E.g. using a data cube A user may want to analyze the weekly, monthly performance of an employee. Here, month and week could be considered as the dimensions of the cube.
25.What are the differences between OLAP And OLTP?[IMP]
| OLAP (Online Analytical Processing) |
OLTP (Online Transaction Processing) |
| Consists of historical data from various Databases. |
Consists only of application-oriented day-to-day operational current data. |
| Application-oriented day-to-dayIt is subject-oriented. Used for Data Mining, Analytics, Decision making, etc. |
It is application-oriented. Used for business tasks. |
| The data is used in planning, problem-solving, and decision-making. |
The data is used to perform day-to-day fundamental operations. |
| It reveals a snapshot of present business tasks. |
It provides a multi-dimensional view of different business tasks. |
| A large forex amount of data is stored typically in TB, PB |
The size of the data is relatively small as the historical data is archived. For example, MB, GB |
| Relatively slow as the amount of data involved is large. Queries may take hours. |
Very Fast as the queries operate on 5% of the data. |
| It only needs backup from time to time as compared to OLTP. |
The backup and recovery process is maintained religiously |
| This data is generally managed by the CEO, MD, GM. |
This data is managed by clerks, managers. |
| Only read and rarely write operation. |
Both read and write operations. |
26. Explain Association Algorithm In Data Mining?
Association analysis is the finding of association rules showing attribute-value conditions that occur frequently together in a given set of data. Association analysis is widely used for a market basket or transaction data analysis. Association rule mining is a significant and exceptionally dynamic area of data mining research. One method of association-based classification, called associative classification, consists of two steps. In the main step, association instructions are generated using a modified version of the standard association rule mining algorithm known as Apriori. The second step constructs a classifier based on the association rules discovered.
27. Explain how to work with data mining algorithms included in SQL server data mining?
SQL Server data mining offers Data Mining Add-ins for Office 2007 that permits finding the patterns and relationships of the information. This helps in an improved analysis. The Add-in called a Data Mining Client for Excel is utilized to initially prepare information, create models, manage, analyze, results.
28. Explain Over-fitting?
The concept of over-fitting is very important in data mining. It refers to the situation in which the induction algorithm generates a classifier that perfectly fits the training data but has lost the capability of generalizing to instances not presented during training. In other words, instead of learning, the classifier just memorizes the training instances. In the decision trees over fitting usually occurs when the tree has too many nodes relative to the amount of training data available. By increasing the number of nodes, the training error usually decreases while at some point the generalization error becomes worse. The Over-fitting can lead to difficulties when there is noise in the training data or when the number of the training datasets, the error of the fully built tree is zero, while the true error is likely to be bigger.
There are many disadvantages of an over-fitted decision tree:
- Over-fitted models are incorrect.
- Over-fitted decision trees require more space and more computational resources.
- They require the collection of unnecessary features.
29. Define Tree Pruning?
When a decision tree is built, many of the branches will reflect anomalies in the training data due to noise or outliers. Tree pruning methods address this problem of over-fitting the data. So the tree pruning is a technique that removes the overfitting problem. Such methods typically use statistical measures to remove the least reliable branches, generally resulting in faster classification and an improvement in the ability of the tree to correctly classify independent test data. The pruning phase eliminates some of the lower branches and nodes to improve their performance. Processing the pruned tree to improve understandability.
30. What is a Sting?
Statistical Information Grid is called STING; it is a grid-based multi-resolution clustering strategy. In the STING strategy, every one of the items is contained into rectangular cells, these cells are kept into different degrees of resolutions and these levels are organized in a hierarchical structure.
31. Define Chameleon Method?
Chameleon is another hierarchical clustering technique that utilization dynamic modeling. Chameleon is acquainted with recover the disadvantages of the CURE clustering technique. In this technique, two groups are combined, if the interconnectivity between two clusters is greater than the inter-connectivity between the object inside a cluster/ group.
32. Explain the Issues regarding Classification And Prediction?
Preparing the data for classification and prediction:
- Data cleaning
- Relevance analysis
- Data transformation
- Comparing classification methods
- Predictive accuracy
- Speed
- Robustness
- Scalability
- Interpretability
33.Explain the use of data mining queries or why data mining queries are more helpful?
The data mining queries are primarily applied to the model of new data to make single or multiple different outcomes. It also permits us to give input values. The query can retrieve information effectively if a particular pattern is defined correctly. It gets the training data statistical memory and gets the specific design and rule of the common case addressing a pattern in the model. It helps in extracting the regression formulas and other computations. It additionally recovers the insights concerning the individual cases utilized in the model. It incorporates the information which isn’t utilized in the analysis, it holds the model with the assistance of adding new data and perform the task and cross-verified.
34. What is a machine learning-based approach to data mining?
This question is the high-level Data Mining Interview Questions asked in an Interview. Machine learning is basically utilized in data mining since it covers automatic programmed processing systems, and it depended on logical or binary tasks. . Machine learning for the most part follows the rule that would permit us to manage more general information types, incorporating cases and in these sorts and number of attributes may differ. Machine learning is one of the famous procedures utilized for data mining and in Artificial intelligence too.
35.What is the K-means algorithm?
K-means clustering algorithm – It is the simplest unsupervised learning algorithm that solves clustering problems. K-means algorithm partition n observations into k clusters where each observation belongs to the cluster with the nearest mean serving as a prototype of the cluster.
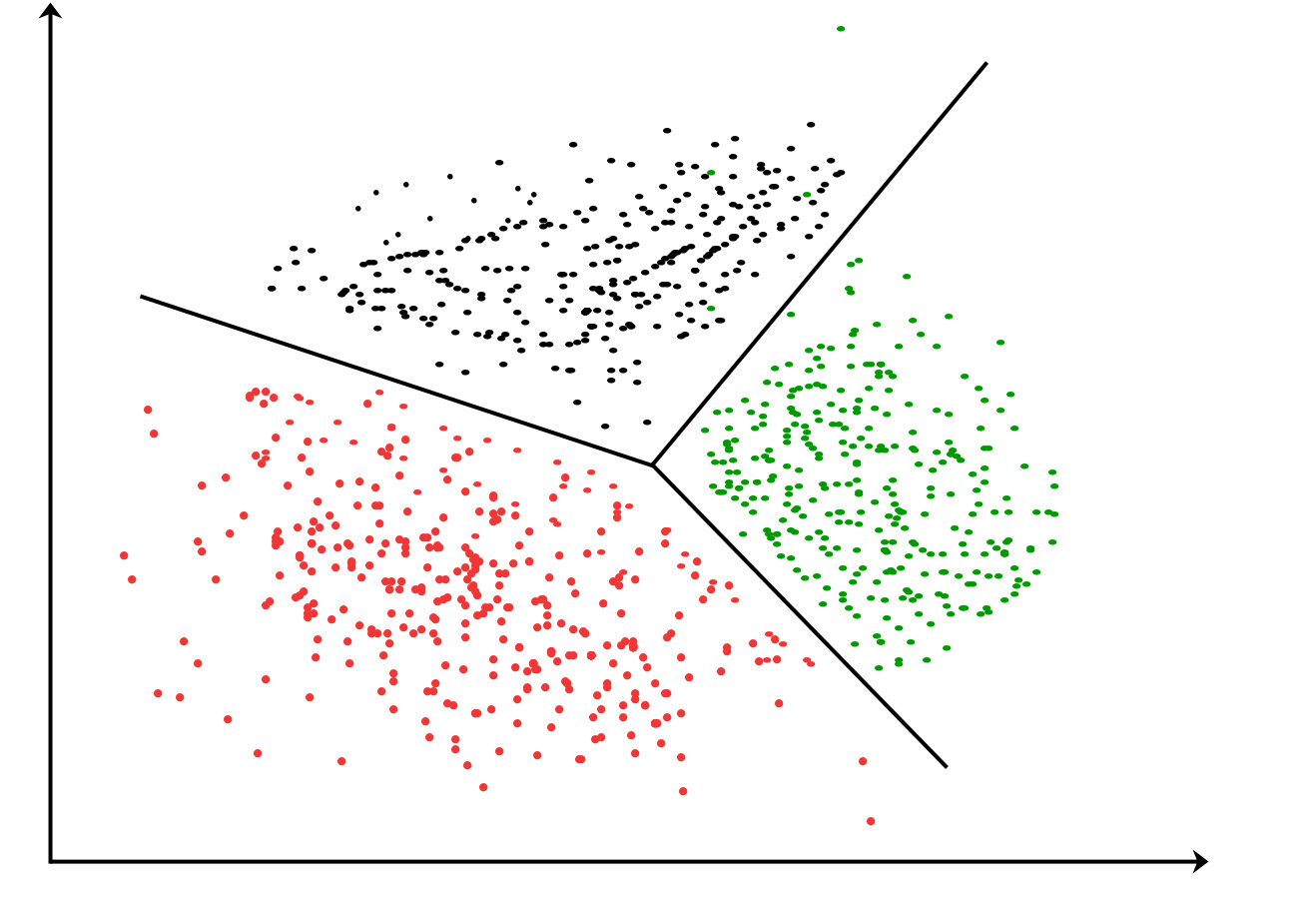
Figure: K-Means Clustering division of attribute
36. What are precision and recall?[IMP]
Precision is the most commonly used error metric in the n classification mechanism. Its range is from 0 to 1, where 1 represents 100%.
Recall can be defined as the number of the Actual Positives in our model which has a class label as Positive (True Positive)”. Recall and the true positive rate is totally identical. Here’s the formula for it:
Recall = (True positive)/(True positive + False negative)
37. What are the ideal situations in which t-test or z-test can be used?
It is a standard practice that a t-test is utilized when there is an example size under 30 attributes and the z-test is viewed as when the example size exceeds 30 by and large.
38. What is the simple difference between standardized and unstandardized coefficients?
In the case of normalized coefficients, they are interpreted dependent on their standard deviation values. While the unstandardized coefficient is estimated depending on the real value present in the dataset.
39. How are outliers detected?
Numerous approaches can be utilized for distinguishing outliers anomalies, but the two most generally utilized techniques are as per the following:
- Standard deviation strategy: Here, the value is considered as an outlier if the value is lower or higher than three standard deviations from the mean value.
- Box plot technique: Here, a value is viewed as an outlier if it is lesser or higher than 1.5 times the interquartile range (IQR)
40. Why is KNN preferred when determining missing numbers in data?
K-Nearest Neighbour (KNN) is preferred here because of the fact that KNN can easily approximate the value to be determined based on the values closest to it.
The k-nearest neighbor (K-NN) classifier is taken into account as an example-based classifier, which means that the training documents are used for comparison instead of an exact class illustration, like the class profiles utilized by other classifiers. As such, there’s no real training section. once a new document has to be classified, the k most similar documents (neighbors) are found and if a large enough proportion of them are allotted to a precise class, the new document is also appointed to the present class, otherwise not. Additionally, finding the closest neighbors is quickened using traditional classification strategies.
41. Explain Prepruning and Post pruning approach in Classification?
Prepruning: In the prepruning approach, a tree is “pruned” by halting its construction early (e.g., by deciding not to further split or partition the subset of training samples at a given node). Upon halting, the node becomes a leaf. The leaf may hold the most frequent class among the subset samples, or the probability distribution of those samples. When constructing a tree, measures such as statistical significance, information gain, etc., can be used to assess the goodness of a split. If partitioning the samples at a node would result in a split that falls below a pre-specified threshold, then further partitioning of the given subset is halted. There are problems, however, in choosing a proper threshold. High thresholds could result in oversimplified trees, while low thresholds could result in very little simplification.
Postpruning: The postpruning approach removes branches from a “fully grown” tree. A tree node is pruned by removing its branches. The cost complexity pruning algorithm is an example of the post pruning approach. The pruned node becomes a leaf and is labeled by the most frequent class among its former branches. For every non-leaf node in the tree, the algorithm calculates the expected error rate that would occur if the subtree at that node were pruned. Next, the predictable error rate occurring if the node were not pruned is calculated using the error rates for each branch, collective by weighting according to the proportion of observations along each branch. If pruning the node leads to a greater probable error rate, then the subtree is reserved. Otherwise, it is pruned. After generating a set of progressively pruned trees, an independent test set is used to estimate the accuracy of each tree. The decision tree that minimizes the expected error rate is preferred.
42. How can one handle suspicious or missing data in a dataset while performing the analysis?
If there are any inconsistencies or uncertainty in the data set, a user can proceed to utilize any of the accompanying techniques: Creation of a validation report with insights regarding the data in conversation Escalating something very similar to an experienced Data Analyst to take a look at it and accept a call Replacing the invalid information with a comparing substantial and latest data information Using numerous methodologies together to discover missing values and utilizing approximation estimate if necessary.
43.What is the simple difference between Principal Component Analysis (PCA) and Factor Analysis (FA)?
Among numerous differences, the significant difference between PCA and FA is that factor analysis is utilized to determine and work with the variance between variables, but the point of PCA is to explain the covariance between the current segments or variables.
44. What is the difference between Data Mining and Data Analysis?
| Data Mining |
Data Analysis |
| Used to perceive designs in data stored. |
Used to arrange and put together raw information in a significant manner. |
| Mining is performed on clean and well-documented. |
The analysis of information includes Data Cleaning. So, information is not available in a well-documented format. |
| Results extracted from data mining are difficult to interpret. |
Results extracted from information analysis are not difficult to interpret. |
45. What is the difference between Data Mining and Data Profiling?
- Data Mining: Data Mining refers to the analysis of information regarding the discovery of relations that have not been found before. It mainly focuses on the recognition of strange records, conditions, and cluster examination.
- Data Profiling: Data Profiling can be described as a process of analyzing single attributes of data. It mostly focuses on giving significant data on information attributes, for example, information type, recurrence, and so on.
46. What are the important steps in the data validation process?
As the name proposes Data Validation is the process of approving information. This progression principally has two methods associated with it. These are Data Screening and Data Verification.
- Data Screening: Different kinds of calculations are utilized in this progression to screen the whole information to discover any inaccurate qualities.
- Data Verification: Each and every presumed value is assessed on different use-cases, and afterward a final conclusion is taken on whether the value must be remembered for the information or not.
47. What is the difference between univariate, bivariate, and multivariate analysis?
The main difference between univariate, bivariate, and multivariate investigation are as per the following:
- Univariate: A statistical procedure that can be separated depending on the check of factors required at a given instance of time.
- Bivariate: This analysis is utilized to discover the distinction between two variables at a time.
- Multivariate: The analysis of multiple variables is known as multivariate. This analysis is utilized to comprehend the impact of factors on the responses.
48. What is the difference between variance and covariance?
Variance and Covariance are two mathematical terms that are frequently in the Statistics field. Variance fundamentally processes how separated numbers are according to the mean. Covariance refers to how two random/irregular factors will change together. This is essentially used to compute the correlation between variables.
49. What are different types of Hypothesis Testing?
The various kinds of hypothesis testing are as per the following:
- T-test: A T-test is utilized when the standard deviation is unknown and the sample size is nearly small.
- Chi-Square Test for Independence: These tests are utilized to discover the significance of the association between all categorical variables in the population sample.
- Analysis of Variance (ANOVA): This type of hypothesis testing is utilized to examine contrasts between the methods in different clusters. This test is utilized comparatively to a T-test but, is utilized for multiple groups.
Welch’s T-test: This test is utilized to discover the test for equality of means between two testing sample tests.
50. Why should we use data warehousing and how can you extract data for analysis?
Data warehousing is a key technology on the way to establishing business intelligence. A data warehouse is a collection of data extracted from the operational or transactional systems in a business, transformed to clean up any inconsistencies in identification coding and definition, and then arranged to support rapid reporting and analysis.
Here are some of the benefits of a data warehouse:
- It is separate from the operational database.
- Integrates data from heterogeneous systems.
- Storage a huge amount of data, more historical than current data.
- Does not require data to be highly accurate.
Bonus Interview Questions & Answers
1. What is Visualization?
Visualization is for the depiction of data and to gain intuition about the data being observed. It assists the analysts in selecting display formats, viewer perspectives, and data representation schema.
2. Give some data mining tools?
- DBMiner
- GeoMiner
- Multimedia miner
- WeblogMiner
3. What are the most significant advantages of Data Mining?
There are many advantages of Data Mining. Some of them are listed below:
- Data Mining is used to polish the raw data and make us able to explore, identify, and understand the patterns hidden within the data.
- It automates finding predictive information in large databases, thereby helping to identify the previously hidden patterns promptly.
- It assists faster and better decision-making, which later helps businesses take necessary actions to increase revenue and lower operational costs.
- It is also used to help data screening and validating to understand where it is coming from.
- Using the Data Mining techniques, the experts can manage applications in various areas such as Market Analysis, Production Control, Sports, Fraud Detection, Astrology, etc.
- The shopping websites use Data Mining to define a shopping pattern and design or select the products for better revenue generation.
- Data Mining also helps in data optimization.
- Data Mining can also be used to determine hidden profitability.
4. What are ‘Training set’ and ‘Test set’?
In various areas of information science like machine learning, a set of data is used to discover the potentially predictive relationship known as ‘Training Set’. The training set is an example given to the learner, while the Test set is used to test the accuracy of the hypotheses generated by the learner, and it is the set of examples held back from the learner. The training set is distinct from the Test set.
5. Explain what is the function of ‘Unsupervised Learning?
- Find clusters of the data
- Find low-dimensional representations of the data
- Find interesting directions in data
- Interesting coordinates and correlations
- Find novel observations/ database cleaning
6. In what areas Pattern Recognition is used?
Pattern Recognition can be used in
- Computer Vision
- Speech Recognition
- Data Mining
- Statistics
- Informal Retrieval
- Bio-Informatics
7. What is ensemble learning?
To solve a particular computational program, multiple models such as classifiers or experts are strategically generated and combined to solve a particular computational program Multiple. This process is known as ensemble learning. Ensemble learning is used when we build component classifiers that are more accurate and independent of each other. This learning is used to improve classification, prediction of data, and function approximation.
8. What is the general principle of an ensemble method and what is bagging and boosting in the ensemble method?
The general principle of an ensemble method is to combine the predictions of several models built with a given learning algorithm to improve robustness over a single model. Bagging is a method in an ensemble for improving unstable estimation or classification schemes. While boosting methods are used sequentially to reduce the bias of the combined model. Boosting and Bagging both can reduce errors by reducing the variance term.
9. What are the components of relational evaluation techniques?
The important components of relational evaluation techniques are
- Data Acquisition
- Ground Truth Acquisition
- Cross-Validation Technique
- Query Type
- Scoring Metric
- Significance Test
10. What are the different methods for Sequential Supervised Learning?
The different methods to solve Sequential Supervised Learning problems are
- Sliding-window methods
- Recurrent sliding windows
- Hidden Markov models
- Maximum entropy Markov models
- Conditional random fields
- Graph transformer networks
11. What is a Random Forest?
Random forest is a machine learning method that helps you to perform all types of regression and classification tasks. It is also used for treating missing values and outlier values.
12. What is reinforcement learning?
Reinforcement Learning is a learning mechanism about how to map situations to actions. The end result should help you to increase the binary reward signal. In this method, a learner is not told which action to take but instead must discover which action offers a maximum reward. This method is based on the reward/penalty mechanism.
13. Is it possible to capture the correlation between continuous and categorical variables?
Yes, we can use the analysis of the covariance technique to capture the association between continuous and categorical variables.
14. What is Visualization?
Visualization is for the depiction of information and to acquire knowledge about the information being observed. It helps the experts in choosing format designs, viewer perspectives, and information representation patterns.
15. Name some best tools which can be used for data analysis.
The most common useful tools for data analysis are:
- Google Search Operators
- KNIME
- Tableau
- Solver
- RapidMiner
- Io
- NodeXL
16. Describe the structure of Artificial Neural Networks?
An artificial neural network (ANN) also referred to as simply a “Neural Network” (NN), could be a process model supported by biological neural networks. Its structure consists of an interconnected collection of artificial neurons. An artificial neural network is an adjective system that changes its structure-supported information that flows through the artificial network during a learning section. The ANN relies on the principle of learning by example. There are, however, 2 classical types of neural networks, perceptron and also multilayer perceptron. Here we are going to target the perceptron algorithmic rule.
17. Do you think 50 small decision trees are better than a large one? Why?
Yes,50 small decision trees are better than a large one because 50 trees make a more robust model (less subject to over-fitting) and simpler to interpret.
Share your thoughts in the comments
Please Login to comment...