Residual Networks (ResNet) – Deep Learning
Last Updated :
10 Jan, 2023
After the first CNN-based architecture (AlexNet) that win the ImageNet 2012 competition, Every subsequent winning architecture uses more layers in a deep neural network to reduce the error rate. This works for less number of layers, but when we increase the number of layers, there is a common problem in deep learning associated with that called the Vanishing/Exploding gradient. This causes the gradient to become 0 or too large. Thus when we increases number of layers, the training and test error rate also increases.
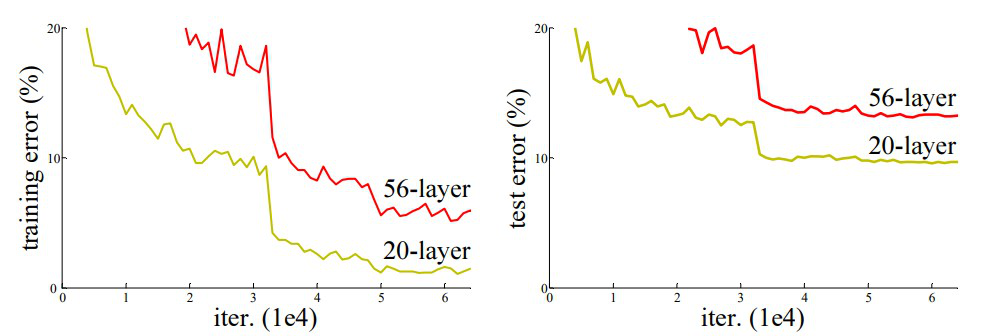
Comparison of 20-layer vs 56-layer architecture
In the above plot, we can observe that a 56-layer CNN gives more error rate on both training and testing dataset than a 20-layer CNN architecture. After analyzing more on error rate the authors were able to reach conclusion that it is caused by vanishing/exploding gradient.
ResNet, which was proposed in 2015 by researchers at Microsoft Research introduced a new architecture called Residual Network.
Residual Network: In order to solve the problem of the vanishing/exploding gradient, this architecture introduced the concept called Residual Blocks. In this network, we use a technique called skip connections. The skip connection connects activations of a layer to further layers by skipping some layers in between. This forms a residual block. Resnets are made by stacking these residual blocks together.
The approach behind this network is instead of layers learning the underlying mapping, we allow the network to fit the residual mapping. So, instead of say H(x), initial mapping, let the network fit,
F(x) := H(x) - x which gives H(x) := F(x) + x.
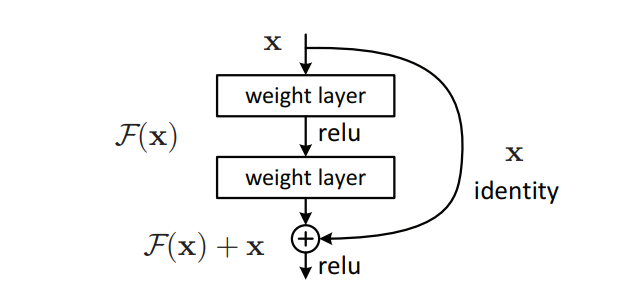
Skip (Shortcut) connection
The advantage of adding this type of skip connection is that if any layer hurt the performance of architecture then it will be skipped by regularization. So, this results in training a very deep neural network without the problems caused by vanishing/exploding gradient. The authors of the paper experimented on 100-1000 layers of the CIFAR-10 dataset.
There is a similar approach called “highway networks”, these networks also use skip connection. Similar to LSTM these skip connections also use parametric gates. These gates determine how much information passes through the skip connection. This architecture however has not provided accuracy better than ResNet architecture.
Network Architecture: This network uses a 34-layer plain network architecture inspired by VGG-19 in which then the shortcut connection is added. These shortcut connections then convert the architecture into a residual network.
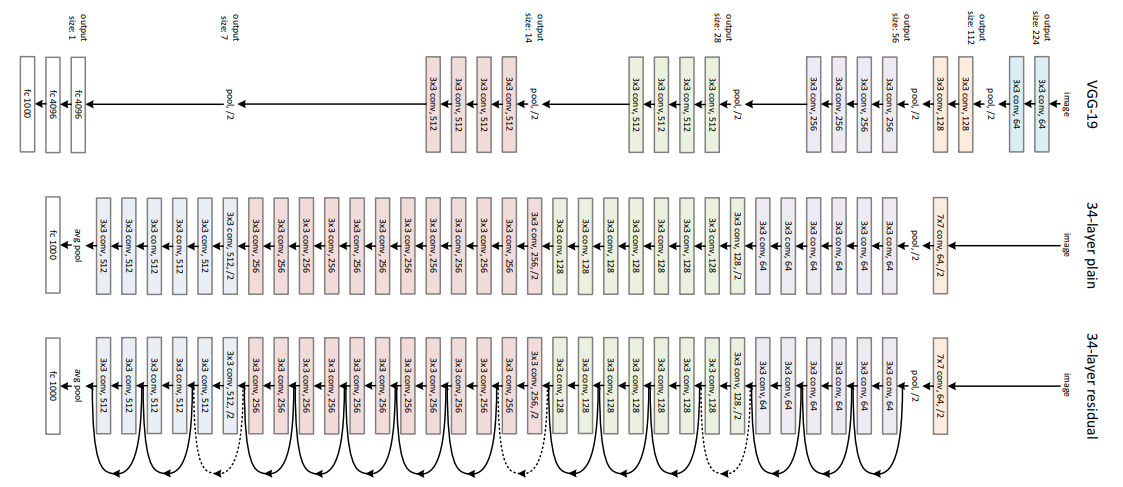
ResNet -34 architecture
Implementation: Using the Tensorflow and Keras API, we can design ResNet architecture (including Residual Blocks) from scratch. Below is the implementation of different ResNet architecture. For this implementation, we use the CIFAR-10 dataset. This dataset contains 60, 000 32×32 color images in 10 different classes (airplanes, cars, birds, cats, deer, dogs, frogs, horses, ships, and trucks), etc. This dataset can be assessed from keras.datasets API function.
Step 1: First, we import the keras module and its APIs. These APIs help in building the architecture of the ResNet model.
Code: Importing libraries
# Import Keras modules and its important APIs
import keras
from keras.layers import Dense, Conv2D, BatchNormalization, Activation
from keras.layers import AveragePooling2D, Input, Flatten
from keras.optimizers import Adam
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras.callbacks import ReduceLROnPlateau
from keras.preprocessing.image import ImageDataGenerator
from keras.regularizers import l2
from keras import backend as K
from keras.models import Model
from keras.datasets import cifar10
import numpy as np
import os
Step 2: Now, We set different hyper parameters that are required for ResNet architecture. We also did some preprocessing on our dataset to prepare it for training.
Code: Setting Training Hyperparameters
python3
batch_size = 32
epochs = 200
data_augmentation = True
num_classes = 10
subtract_pixel_mean = True
n = 3
version = 1
if version == 1:
depth = n * 6 + 2
elif version == 2:
depth = n * 9 + 2
model_type = 'ResNet % dv % d' % (depth, version)
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
input_shape = x_train.shape[1:]
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
if subtract_pixel_mean:
x_train_mean = np.mean(x_train, axis = 0)
x_train -= x_train_mean
x_test -= x_train_mean
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
print('y_train shape:', y_train.shape)
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
|
Step 3: In this step, we set the learning rate according to the number of epochs. As the number of epochs the learning rate must be decreased to ensure better learning.
Code: Setting LR for different numbers of Epochs
python3
def lr_schedule(epoch):
lr = 1e-3
if epoch > 180:
lr *= 0.5e-3
elif epoch > 160:
lr *= 1e-3
elif epoch > 120:
lr *= 1e-2
elif epoch > 80:
lr *= 1e-1
print('Learning rate: ', lr)
return lr
|
Step 4: Define basic ResNet building block that can be used for defining the ResNet V1 and V2 architecture.
Code: Basic ResNet Building Block
python3
def resnet_layer(inputs,
num_filters=16,
kernel_size=3,
strides=1,
activation='relu',
batch_normalization=True,
conv=Conv2D(num_filters,
kernel_size=kernel_size,
strides=strides,
padding='same',
kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))
x=inputs
if conv_first:
x = conv(x)
if batch_normalization:
x = BatchNormalization()(x)
if activation is not None:
x = Activation(activation)(x)
else:
if batch_normalization:
x = BatchNormalization()(x)
if activation is not None:
x = Activation(activation)(x)
x = conv(x)
return x
|
Step 5: Define ResNet V1 architecture that is based on the ResNet building block we defined above:
Code: ResNet V1 architecture
python3
def resnet_v1(input_shape, depth, num_classes=10):
if (depth - 2) % 6 != 0:
raise ValueError('depth should be 6n + 2 (eg 20, 32, 44 in [a])')
num_filters = 16
num_res_blocks = int((depth - 2) / 6)
inputs = Input(shape=input_shape)
x = resnet_layer(inputs=inputs)
for stack in range(3):
for res_block in range(num_res_blocks):
strides = 1
if stack & gt
0 and res_block == 0:
strides = 2
y = resnet_layer(inputs=x,
num_filters=num_filters,
strides=strides)
y = resnet_layer(inputs=y,
num_filters=num_filters,
activation=None)
if stack & gt
0 and res_block == 0:
x = resnet_layer(inputs=x,
num_filters=num_filters,
kernel_size=1,
strides=strides,
activation=None,
batch_normalization=False)
x = keras.layers.add([x, y])
x = Activation('relu')(x)
num_filters *= 2
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
model = Model(inputs=inputs, outputs=outputs)
return model
|
Step 6: Define ResNet V2 architecture that is based on the ResNet building block we defined above:
Code: ResNet V2 architecture
python3
def resnet_v2(input_shape, depth, num_classes=10):
if (depth - 2) % 9 != 0:
raise ValueError('depth should be 9n + 2 (eg 56 or 110 in [b])')
num_filters_in = 16
num_res_blocks = int((depth - 2) / 9)
inputs = Input(shape=input_shape)
x = resnet_layer(inputs=inputs,
num_filters=num_filters_in,
conv_first=True)
for stage in range(3):
for res_block in range(num_res_blocks):
activation = 'relu'
batch_normalization = True
strides = 1
if stage == 0:
num_filters_out = num_filters_in * 4
if res_block == 0:
activation = None
batch_normalization = False
else:
num_filters_out = num_filters_in * 2
if res_block == 0:
strides = 2
y = resnet_layer(inputs=x,
num_filters=num_filters_in,
kernel_size=1,
strides=strides,
activation=activation,
batch_normalization=batch_normalization,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_in,
conv_first=False)
y = resnet_layer(inputs=y,
num_filters=num_filters_out,
kernel_size=1,
conv_first=False)
if res_block == 0:
x = resnet_layer(inputs=x,
num_filters=num_filters_out,
kernel_size=1,
strides=strides,
activation=None,
batch_normalization=False)
x = keras.layers.add([x, y])
num_filters_in = num_filters_out
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = AveragePooling2D(pool_size=8)(x)
y = Flatten()(x)
outputs = Dense(num_classes,
activation='softmax',
kernel_initializer='he_normal')(y)
model = Model(inputs=inputs, outputs=outputs)
return model
|
Step 7: The code below is used to train and test the ResNet v1 and v2 architecture we defined above:
Code: Main function
python3
if version == 2:
model = resnet_v2(input_shape = input_shape, depth = depth)
else:
model = resnet_v1(input_shape = input_shape, depth = depth)
model.compile(loss ='categorical_crossentropy',
optimizer = Adam(learning_rate = lr_schedule(0)),
metrics =['accuracy'])
model.summary()
print(model_type)
save_dir = os.path.join(os.getcwd(), 'saved_models')
model_name = 'cifar10_% s_model.{epoch:03d}.h5' % model_type
if not os.path.isdir(save_dir):
os.makedirs(save_dir)
filepath = os.path.join(save_dir, model_name)
checkpoint = ModelCheckpoint(filepath = filepath,
monitor ='val_acc',
verbose = 1,
save_best_only = True)
lr_scheduler = LearningRateScheduler(lr_schedule)
lr_reducer = ReduceLROnPlateau(factor = np.sqrt(0.1),
cooldown = 0,
patience = 5,
min_lr = 0.5e-6)
callbacks = [checkpoint, lr_reducer, lr_scheduler]
if not data_augmentation:
print('Not using data augmentation.')
model.fit(x_train, y_train,
batch_size = batch_size,
epochs = epochs,
validation_data =(x_test, y_test),
shuffle = True,
callbacks = callbacks)
else:
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(
featurewise_center = False,
samplewise_center = False,
featurewise_std_normalization = False,
samplewise_std_normalization = False,
zca_whitening = False,
zca_epsilon = 1e-06,
rotation_range = 0,
width_shift_range = 0.1,
height_shift_range = 0.1,
shear_range = 0.,
zoom_range = 0.,
channel_shift_range = 0.,
fill_mode ='nearest',
cval = 0.,
horizontal_flip = True,
vertical_flip = False,
rescale = None,
preprocessing_function = None,
data_format = None,
validation_split = 0.0)
datagen.fit(x_train)
model.fit_generator(datagen.flow(x_train, y_train, batch_size = batch_size),
validation_data =(x_test, y_test),
epochs = epochs, verbose = 1, workers = 4,
callbacks = callbacks)
scores = model.evaluate(x_test, y_test, verbose = 1)
print('Test loss:', scores[0])
print('Test accuracy:', scores[1])
|
Results & Conclusion:
On the ImageNet dataset, the authors uses a 152-layers ResNet, which is 8 times more deep than VGG19 but still have less parameters. An ensemble of these ResNets generated an error of only 3.7% on ImageNet test set, the result which won ILSVRC 2015 competition. On COCO object detection dataset, it also generates a 28% relative improvement due to its very deep representation.
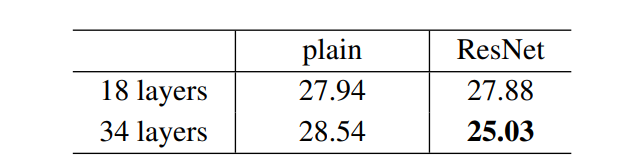
Error-rate on ResNet Architecture
- The result above shows that shortcut connections would be able to solve the problem caused by increasing the layers because as we increase layers from 18 to 34 the error rate on ImageNet Validation Set also decreases unlike the plain network.
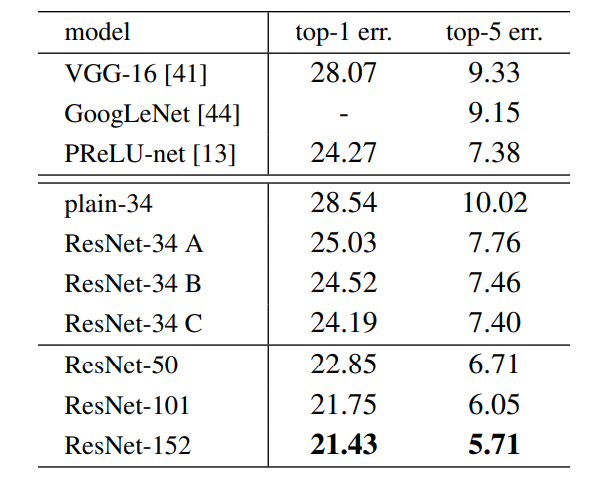
top-1 and top-5 Error rate on ImageNet Validation Set.
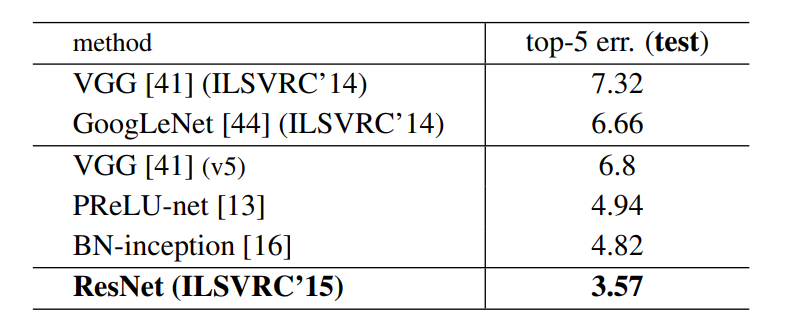
- Below are the results on ImageNet Test Set. The 3.57% top-5 error rate of ResNet was the lowest and thus ResNet architecture came first in ImageNet classification challenge in 2015.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...