Repository Design Pattern
Last Updated :
12 Feb, 2024
In the world of software creation, managing data is a big deal. It’s like organizing your room but in the digital world. The Repository Design Pattern is like a magical closet that helps you keep your data tidy and easy to use.
When you build software, one of the big challenges is how to handle all the data. In the case of a room example, data can be like books, clothes, or toys scattered all over your room, and you need a system to keep things in order. The Repository Design Pattern is that system. It’s like a super organized closet that stores your data and helps you find it when you need it.
But it’s more than just a closet. The Repository Design Pattern is a set of rules and practices that make your software better. It’s like having a superpower in the world of software. It helps you keep your data organized and makes your software flexible, easier to understand, and simpler to test.
-copy.webp)
Important Topics for the Repository Design Pattern
Repository Design Pattern: Simplifying Data Access
Below is the step-by-step explanation of the Repository Design Pattern
- The Repository Design Pattern is a software design pattern that acts as an intermediary layer between an application’s business logic and data storage.
- Its primary purpose is to provide a structured and standardized way to access, manage, and manipulate data while abstracting the underlying details of data storage technologies.
- This pattern promotes a clear separation of concerns, making software more maintainable, testable, and adaptable to changes in data sources, without entangling the core application logic with data access intricacies.
- In essence, the Repository Design Pattern is a blueprint for organizing and simplifying data access, enhancing the efficiency and flexibility of software systems.
Repository Design Pattern explained with an example(Library Analogy)
The Repository Design Pattern is like a librarian in a library.
Imagine you’re at a library to find a book. You don’t go into the storage room to search for it yourself, instead, you ask the librarian to help you find the book. The librarian knows where the books are kept and can give you the book you want without you having to worry about where it’s stored.
In the same way, the Repository Design Pattern works as a librarian between a program and data (like books in a library). Instead of the program directly looking for data, it asks for repository to find save, update, or delete the data it needs.
For example:
let’s say you have a program (like an app) that keeps track of different products in a store. The program needs to store these products, update information about them, and delete them if necessary. Instead of app directly talking to the storage where the data is kept (like a database), it uses a Repository to do these tasks.
The Repository knows how to communicate with the storage to perform these actions.
Step-by-Step Implementation of Repository Design Pattern in C++
Let’s consider an example of managing products in an online store using the Repository Design Pattern in C++
Problem Statement
Suppose you are developing an e-commerce application that needs to manage products. The application should be able to add new products, retrieve existing products, update product information, and delete products. Instead of directly interacting with the database, we will utilize the Repository Pattern to handle these operations.
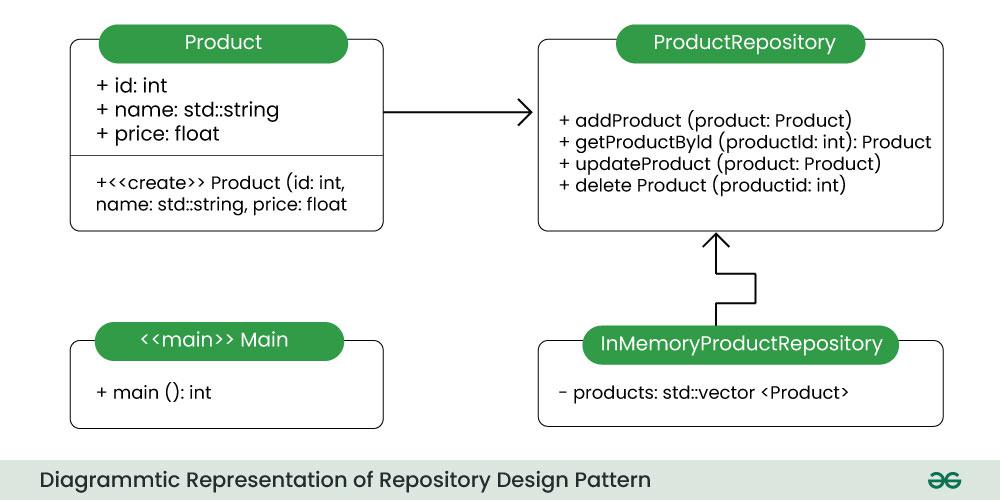
Step 1: Define the Product Entity
The Product class defines the attributes of product, such as id, name and price. This serves as the basic data structure representing a product.
C++
class Product {
public:
int id;
std::string name;
float price;
Product(int id, std::string name, float price) : id(id), name(std::move(name)), price(price) {}
};
|
In this step, the Product class acts as a blueprint for creating product objects, each having a unique identifier (id), a name, and a price.
Step 2: Create the Repository Interface
The ProductRepository class is an abstract class that declares methods to manage products, such as adding, retrieving, updating, and deleting.
C++
class ProductRepository {
public:
virtual void addProduct(const Product& product) = 0;
virtual Product getProductById(int productId) = 0;
virtual void updateProduct(const Product& product) = 0;
virtual void deleteProduct(int productId) = 0;
};
|
In this step, we create a set of rules that any class, intending to work as a repository for products, must follow. These rules specify the exact methods that a real repository class must have. It’s like making a list of instructions that every repository class must follow.
Step 3: Implement a Concrete Repository
The InMemoryProductRepository class is a concrete implementation of the ProductRepository. It uses an in-memory data structure (here, a vector) to manage products.
C++
class InMemoryProductRepository : public ProductRepository {
private:
std::vector<Product> products;
public:
void addProduct(const Product& product) override {
products.push_back(product);
}
Product getProductById(int productId) override {
for (const auto& product : products) {
if (product.id == productId) {
return product;
}
}
return Product(-1, "Not Found", 0.0);
}
void updateProduct(const Product& updatedProduct) override {
for (auto& product : products) {
if (product.id == updatedProduct.id) {
product = updatedProduct;
return;
}
}
}
void deleteProduct(int productId) override {
products.erase(std::remove_if(products.begin(), products.end(),
[productId](const Product& product) { return product.id == productId; }),
products.end());
}
};
|
This step involves the implementation of the actual methods declared in the ProductRepository interface. In this case, an in-memory data store (vector) is used to store and manage products. It includes functionalities like adding, retrieving, updating, and deleting products.
Step 4: Usage in Main Function
The main function demonstrates the usage of the InMemoryProductRepository by performing various operations on products.
C++
int main() {
InMemoryProductRepository productRepo;
productRepo.addProduct(Product(1, "Keyboard", 25.0));
productRepo.addProduct(Product(2, "Mouse", 15.0));
Product retrievedProduct = productRepo.getProductById(1);
std::cout << "Retrieved Product: " << retrievedProduct.name << " - $" << retrievedProduct.price << std::endl;
retrievedProduct.price = 30.0;
productRepo.updateProduct(retrievedProduct);
productRepo.deleteProduct(2);
return 0;
}
|
The main function serves as an entry point and demonstrates the functionality provided by the InMemoryProductRepository It creates an instance of the repository, adds products, retrieves a product, updates its prices, and deletes a product.
This code implements a simple in-memory repository for demonstration purposes, but in real-world scenario, the repository would likely interact with a database or some other persistent storage.
Advantages of Repository Design Pattern
- Centralized Data Access: The pattern centralizes and abstracts data access logic, allowing the rest of the application to interact with data through a consistent interface. This simplifies code maintenance by managing all data-related operations in one place.
- Enhanced Testability: Separating data access logic from the business logic facilitates easier unit testing. With a clear interface for data operations, mocking or substituting the repository makes it simpler to test other parts of the application independently.
- Improve Code Maintainability: The repository design pattern promotes clean code by isolating data access logic. This separation allows developers to make changes or optimize data access without affecting the rest of the application.
- Reusability and Extensibility: By adhering to the repository contract, multiple parts of the application can reuse the same data access methods. It allows for easy addition of new data sources or technologies without having to change the main logic of the application.
Disadvantages of Repository Design Pattern
- Overhead for Simple Applications: Implementing the repository design pattern might introduce unnecessary complexity in smaller or straightforward applications. In such cases, the added layers of abstraction might be more cumbersome than beneficial.
- Learning Curve and Development Time: Adopting the repository design pattern might require additional time for development, as it involves creating interfaces, defining contracts, and implementing concrete repository classes. This learning curve could impact project timelines.
- Potential Abstraction Leaks: In some cases, the repository design pattern might leak underlying implementation details to higher layers, making the abstraction less effective. This can happen if the repository needs to cater to complex queries or operations.
Use Cases for Repository Design Pattern
- Web Applications: Repositories are commonly used in web applications to manage data access to databases. They abstract the interaction with the database and make it easier to switch to a different database system.
- APIs and Services: When building APIs or microservices, the Repository Pattern can help manage data access in a clean and organized way. It enables multiple services to interact with data consistently.
- Large and Complex Systems: For large, complex systems where data access logic can become tangled and messy, the Repository Pattern offers a tidy way to handle how data is accessed. This makes the code easier to maintain and manage.
- Testing Environments: It’s valuable in testing environments where you want to isolate data access for testing purposes. Mock repositories can be created to simulate data access without modifying the actual data source.
- Data Migration: When migrating data from one database to another, the Repository Pattern allows for a smoother transition. You can replace the repository’s implementation to work with the new data source while keeping the rest of the application intact.
Conclusion
In essence, the Repository Design Pattern is a crucial framework in software development. It neatly organizes data access logic, separating it from the core application. This separation makes code more reusable, maintainable, and easier to test.
By providing a clear division between the application and the data storage, the pattern allows developers to focus on the main logic without worrying about intricate storage details. Its adaptability enables smooth transitions between different data sources and supports efficient testing through the creation of simulated data repositories.
Share your thoughts in the comments
Please Login to comment...