Recoverability is a property of database systems that ensures that, in the event of a failure or error, the system can recover the database to a consistent state. Recoverability guarantees that all committed transactions are durable and that their effects are permanently stored in the database, while the effects of uncommitted transactions are undone to maintain data consistency.
The recoverability property is enforced through the use of transaction logs, which record all changes made to the database during transaction processing. When a failure occurs, the system uses the log to recover the database to a consistent state, which involves either undoing the effects of uncommitted transactions or redoing the effects of committed transactions.
There are several levels of recoverability that can be supported by a database system:
No-undo logging: This level of recoverability only guarantees that committed transactions are durable, but does not provide the ability to undo the effects of uncommitted transactions.
Undo logging: This level of recoverability provides the ability to undo the effects of uncommitted transactions but may result in the loss of updates made by committed transactions that occur after the failed transaction.
Redo logging: This level of recoverability provides the ability to redo the effects of committed transactions, ensuring that all committed updates are durable and can be recovered in the event of failure.
Undo-redo logging: This level of recoverability provides both undo and redo capabilities, ensuring that the system can recover to a consistent state regardless of whether a transaction has been committed or not.
In addition to these levels of recoverability, database systems may also use techniques such as checkpointing and shadow paging to improve recovery performance and reduce the overhead associated with logging.
Overall, recoverability is a crucial property of database systems, as it ensures that data is consistent and durable even in the event of failures or errors. It is important for database administrators to understand the level of recoverability provided by their system and to configure it appropriately to meet their application’s requirements.
Prerequisite:
As discussed, a transaction may not execute completely due to hardware failure, system crash or software issues. In that case, we have to roll back the failed transaction. But some other transactions may also have used values produced by the failed transaction. So we have to roll back those transactions as well.
Recoverable Schedules:
- Schedules in which transactions commit only after all transactions whose changes they read commit are called recoverable schedules. In other words, if some transaction Tj is reading value updated or written by some other transaction Ti, then the commit of Tj must occur after the commit of Ti.
Example 1:
S1: R1(x), W1(x), R2(x), R1(y), R2(y),
W2(x), W1(y), C1, C2;
Given schedule follows order of Ti->Tj => C1->C2. Transaction T1 is executed before T2 hence there is no chances of conflict occur. R1(x) appears before W1(x) and transaction T1 is committed before T2 i.e. completion of first transaction performed first update on data item x, hence given schedule is recoverable.
Example 2: Consider the following schedule involving two transactions T1 and T2.
| T1 |
T2 |
| R(A) |
|
| W(A) |
|
| |
W(A) |
| |
R(A) |
| commit |
|
| |
commit |
This is a recoverable schedule since T1 commits before T2, that makes the value read by T2 correct.
Irrecoverable Schedule: The table below shows a schedule with two transactions, T1 reads and writes A and that value is read and written by T2. T2 commits. But later on, T1 fails. So we have to rollback T1. Since T2 has read the value written by T1, it should also be rollbacked. But we have already committed that. So this schedule is irrecoverable schedule. When Tj is reading the value updated by Ti and Tj is committed before committing of Ti, the schedule will be irrecoverable. 
Recoverable with Cascading Rollback: The table below shows a schedule with two transactions, T1 reads and writes A and that value is read and written by T2. But later on, T1 fails. So we have to rollback T1. Since T2 has read the value written by T1, it should also be rollbacked. As it has not committed, we can rollback T2 as well. So it is recoverable with cascading rollback. Therefore, if Tj is reading value updated by Ti and commit of Tj is delayed till commit of Ti, the schedule is called recoverable with cascading rollback.
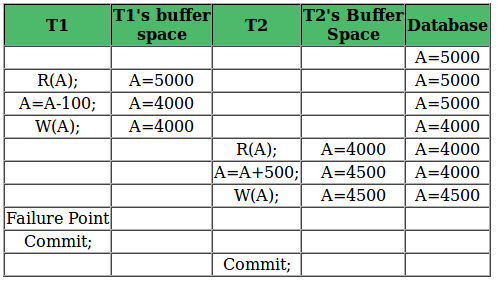
Cascadeless Recoverable Rollback: The table below shows a schedule with two transactions, T1 reads and writes A and commits and that value is read by T2. But if T1 fails before commit, no other transaction has read its value, so there is no need to rollback other transaction. So this is a Cascadeless recoverable schedule. So, if Tj reads value updated by Ti only after Ti is committed, the schedule will be cascadeless recoverable.

Question: Which of the following scenarios may lead to an irrecoverable error in a database system?
- A transaction writes a data item after it is read by an uncommitted transaction.
- A transaction reads a data item after it is read by an uncommitted transaction.
- A transaction reads a data item after it is written by a committed transaction.
- A transaction reads a data item after it is written by an uncommitted transaction.
Answer: See the example discussed in Table 1, a transaction is reading a data item after it is written by an uncommitted transaction, the schedule will be irrecoverable.
The capabilities of recoverability in a DBMS encompass:
Atomicity: Transactions in a DBMS are designed to be atomic, which means that they either entire absolutely or are rolled back to their unique nation in case of a failure. This guarantees that the database is usually in a consistent nation.
Durability: Once a transaction is dedicated, its changes are permanently stored to the database, even in the occasion of a failure. This ensures that the database may be restored to its closing consistent kingdom after a failure.
Logging: A DBMS keeps a log of all transactions to make sure recoverability. The log consists of data about all adjustments made to the database, as well as the transactions that made those changes. In the event of a failure, the log may be used to repair the database to a regular state.
Checkpointing: A checkpoint is a point in time in which the DBMS records the country of the database and logs it. This allows lessen the quantity of time required for recovery in case of a failure, as handiest the transactions since the last checkpoint need to be rolled back or replayed.
Recovery manager: A restoration supervisor is a part of a DBMS that is accountable for restoring the database to a constant state after a failure. The healing supervisor uses the log and checkpoints to determine which transactions want to be rolled returned or replayed to repair the database.
Media recuperation: Media recovery refers back to the capability of a DBMS to recover from a failure that affects the garage media, such as a hard disk crash. This includes restoring the database from a backup and making use of the log to deliver it up to date.
Related Post: Conflict Serializability
Share your thoughts in the comments
Please Login to comment...