Insert Operation in B-Tree
Last Updated :
19 Mar, 2024
In the previous post, we introduced B-Tree. We also discussed search() and traverse() functions.
In this post, insert() operation is discussed. A new key is always inserted at the leaf node. Let the key to be inserted be k. Like BST, we start from the root and traverse down till we reach a leaf node. Once we reach a leaf node, we insert the key in that leaf node. Unlike BSTs, we have a predefined range on the number of keys that a node can contain. So before inserting a key to the node, we make sure that the node has extra space.
How to make sure that a node has space available for a key before the key is inserted? We use an operation called splitChild() that is used to split a child of a node. See the following diagram to understand split. In the following diagram, child y of x is being split into two nodes y and z. Note that the splitChild operation moves a key up and this is the reason B-Trees grow up, unlike BSTs which grow down.
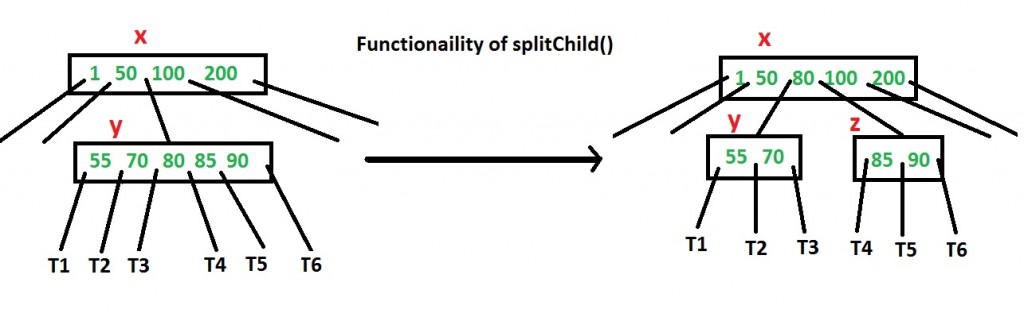
As discussed above, to insert a new key, we go down from root to leaf. Before traversing down to a node, we first check if the node is full. If the node is full, we split it to create space. Following is the complete algorithm.
Insertion
1) Initialize x as root.
2) While x is not leaf, do following
..a) Find the child of x that is going to be traversed next. Let the child be y.
..b) If y is not full, change x to point to y.
..c) If y is full, split it and change x to point to one of the two parts of y. If k is smaller than mid key in y, then set x as the first part of y. Else second part of y. When we split y, we move a key from y to its parent x.
3) The loop in step 2 stops when x is leaf. x must have space for 1 extra key as we have been splitting all nodes in advance. So simply insert k to x.
Note that the algorithm follows the Cormen book. It is actually a proactive insertion algorithm where before going down to a node, we split it if it is full. The advantage of splitting before is, we never traverse a node twice. If we don’t split a node before going down to it and split it only if a new key is inserted (reactive), we may end up traversing all nodes again from leaf to root. This happens in cases when all nodes on the path from the root to leaf are full. So when we come to the leaf node, we split it and move a key up. Moving a key up will cause a split in parent node (because the parent was already full). This cascading effect never happens in this proactive insertion algorithm. There is a disadvantage of this proactive insertion though, we may do unnecessary splits.
Let us understand the algorithm with an example tree of minimum degree ‘t’ as 3 and a sequence of integers 10, 20, 30, 40, 50, 60, 70, 80 and 90 in an initially empty B-Tree.
Initially root is NULL. Let us first insert 10.

Let us now insert 20, 30, 40 and 50. They all will be inserted in root because the maximum number of keys a node can accommodate is 2*t – 1 which is 5.

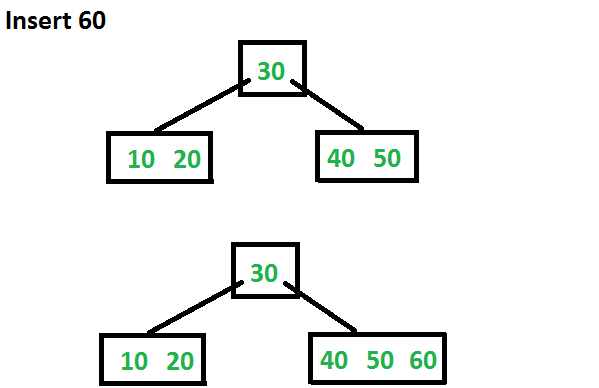
Let us now insert 60. Since root node is full, it will first split into two, then 60 will be inserted into the appropriate child.
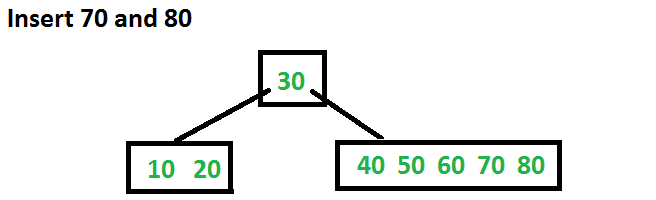
Let us now insert 70 and 80. These new keys will be inserted into the appropriate leaf without any split.
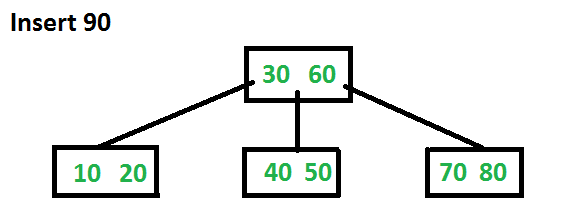
Let us now insert 90. This insertion will cause a split. The middle key will go up to the parent.
Following are the implementations of the above proactive algorithm.
C++
// C++ program for B-Tree insertion
#include<iostream>
using namespace std;
// A BTree node
class BTreeNode
{
int *keys; // An array of keys
int t; // Minimum degree (defines the range for number of keys)
BTreeNode **C; // An array of child pointers
int n; // Current number of keys
bool leaf; // Is true when node is leaf. Otherwise false
public:
BTreeNode(int _t, bool _leaf); // Constructor
// A utility function to insert a new key in the subtree rooted with
// this node. The assumption is, the node must be non-full when this
// function is called
void insertNonFull(int k);
// A utility function to split the child y of this node. i is index of y in
// child array C[]. The Child y must be full when this function is called
void splitChild(int i, BTreeNode *y);
// A function to traverse all nodes in a subtree rooted with this node
void traverse();
// A function to search a key in the subtree rooted with this node.
BTreeNode *search(int k); // returns NULL if k is not present.
// Make BTree friend of this so that we can access private members of this
// class in BTree functions
friend class BTree;
};
// A BTree
class BTree
{
BTreeNode *root; // Pointer to root node
int t; // Minimum degree
public:
// Constructor (Initializes tree as empty)
BTree(int _t)
{ root = NULL; t = _t; }
// function to traverse the tree
void traverse()
{ if (root != NULL) root->traverse(); }
// function to search a key in this tree
BTreeNode* search(int k)
{ return (root == NULL)? NULL : root->search(k); }
// The main function that inserts a new key in this B-Tree
void insert(int k);
};
// Constructor for BTreeNode class
BTreeNode::BTreeNode(int t1, bool leaf1)
{
// Copy the given minimum degree and leaf property
t = t1;
leaf = leaf1;
// Allocate memory for maximum number of possible keys
// and child pointers
keys = new int[2*t-1];
C = new BTreeNode *[2*t];
// Initialize the number of keys as 0
n = 0;
}
// Function to traverse all nodes in a subtree rooted with this node
void BTreeNode::traverse()
{
// There are n keys and n+1 children, traverse through n keys
// and first n children
int i;
for (i = 0; i < n; i++)
{
// If this is not leaf, then before printing key[i],
// traverse the subtree rooted with child C[i].
if (leaf == false)
C[i]->traverse();
cout << " " << keys[i];
}
// Print the subtree rooted with last child
if (leaf == false)
C[i]->traverse();
}
// Function to search key k in subtree rooted with this node
BTreeNode *BTreeNode::search(int k)
{
// Find the first key greater than or equal to k
int i = 0;
while (i < n && k > keys[i])
i++;
// If the found key is equal to k, return this node
if (keys[i] == k)
return this;
// If key is not found here and this is a leaf node
if (leaf == true)
return NULL;
// Go to the appropriate child
return C[i]->search(k);
}
// The main function that inserts a new key in this B-Tree
void BTree::insert(int k)
{
// If tree is empty
if (root == NULL)
{
// Allocate memory for root
root = new BTreeNode(t, true);
root->keys[0] = k; // Insert key
root->n = 1; // Update number of keys in root
}
else // If tree is not empty
{
// If root is full, then tree grows in height
if (root->n == 2*t-1)
{
// Allocate memory for new root
BTreeNode *s = new BTreeNode(t, false);
// Make old root as child of new root
s->C[0] = root;
// Split the old root and move 1 key to the new root
s->splitChild(0, root);
// New root has two children now. Decide which of the
// two children is going to have new key
int i = 0;
if (s->keys[0] < k)
i++;
s->C[i]->insertNonFull(k);
// Change root
root = s;
}
else // If root is not full, call insertNonFull for root
root->insertNonFull(k);
}
}
// A utility function to insert a new key in this node
// The assumption is, the node must be non-full when this
// function is called
void BTreeNode::insertNonFull(int k)
{
// Initialize index as index of rightmost element
int i = n-1;
// If this is a leaf node
if (leaf == true)
{
// The following loop does two things
// a) Finds the location of new key to be inserted
// b) Moves all greater keys to one place ahead
while (i >= 0 && keys[i] > k)
{
keys[i+1] = keys[i];
i--;
}
// Insert the new key at found location
keys[i+1] = k;
n = n+1;
}
else // If this node is not leaf
{
// Find the child which is going to have the new key
while (i >= 0 && keys[i] > k)
i--;
// See if the found child is full
if (C[i+1]->n == 2*t-1)
{
// If the child is full, then split it
splitChild(i+1, C[i+1]);
// After split, the middle key of C[i] goes up and
// C[i] is splitted into two. See which of the two
// is going to have the new key
if (keys[i+1] < k)
i++;
}
C[i+1]->insertNonFull(k);
}
}
// A utility function to split the child y of this node
// Note that y must be full when this function is called
void BTreeNode::splitChild(int i, BTreeNode *y)
{
// Create a new node which is going to store (t-1) keys
// of y
BTreeNode *z = new BTreeNode(y->t, y->leaf);
z->n = t - 1;
// Copy the last (t-1) keys of y to z
for (int j = 0; j < t-1; j++)
z->keys[j] = y->keys[j+t];
// Copy the last t children of y to z
if (y->leaf == false)
{
for (int j = 0; j < t; j++)
z->C[j] = y->C[j+t];
}
// Reduce the number of keys in y
y->n = t - 1;
// Since this node is going to have a new child,
// create space of new child
for (int j = n; j >= i+1; j--)
C[j+1] = C[j];
// Link the new child to this node
C[i+1] = z;
// A key of y will move to this node. Find the location of
// new key and move all greater keys one space ahead
for (int j = n-1; j >= i; j--)
keys[j+1] = keys[j];
// Copy the middle key of y to this node
keys[i] = y->keys[t-1];
// Increment count of keys in this node
n = n + 1;
}
// Driver program to test above functions
int main()
{
BTree t(3); // A B-Tree with minimum degree 3
t.insert(10);
t.insert(20);
t.insert(5);
t.insert(6);
t.insert(12);
t.insert(30);
t.insert(7);
t.insert(17);
cout << "Traversal of the constructed tree is ";
t.traverse();
int k = 6;
(t.search(k) != NULL)? cout << "\nPresent" : cout << "\nNot Present";
k = 15;
(t.search(k) != NULL)? cout << "\nPresent" : cout << "\nNot Present";
return 0;
}
class BTreeNode {
int[] keys;
int t;
BTreeNode[] C;
int n;
boolean leaf;
public BTreeNode(int t, boolean leaf) {
this.keys = new int[2 * t - 1];
this.t = t;
this.C = new BTreeNode[2 * t];
this.n = 0;
this.leaf = leaf;
}
void insertNonFull(int k) {
int i = n - 1;
if (leaf) {
while (i >= 0 && keys[i] > k) {
keys[i + 1] = keys[i];
i--;
}
keys[i + 1] = k;
n++;
} else {
while (i >= 0 && keys[i] > k) {
i--;
}
if (C[i + 1].n == 2 * t - 1) {
splitChild(i + 1, C[i + 1]);
if (keys[i + 1] < k) {
i++;
}
}
C[i + 1].insertNonFull(k);
}
}
void splitChild(int i, BTreeNode y) {
BTreeNode z = new BTreeNode(y.t, y.leaf);
z.n = t - 1;
for (int j = 0; j < t - 1; j++) {
z.keys[j] = y.keys[j + t];
}
if (!y.leaf) {
for (int j = 0; j < t; j++) {
z.C[j] = y.C[j + t];
}
}
y.n = t - 1;
for (int j = n; j > i; j--) {
C[j + 1] = C[j];
}
C[i + 1] = z;
for (int j = n - 1; j >= i; j--) {
keys[j + 1] = keys[j];
}
keys[i] = y.keys[t - 1];
n++;
}
void traverse() {
for (int i = 0; i < n; i++) {
if (!leaf) {
C[i].traverse();
}
System.out.print(" " + keys[i]);
}
if (!leaf) {
C[n].traverse();
}
}
BTreeNode search(int k) {
int i = 0;
while (i < n && k > keys[i]) {
i++;
}
if (i < n && k == keys[i]) {
return this;
}
if (leaf) {
return null;
}
return C[i].search(k);
}
}
class BTree {
BTreeNode root;
int t;
public BTree(int t) {
this.root = null;
this.t = t;
}
void traverse() {
if (root != null) {
root.traverse();
}
}
BTreeNode search(int k) {
return root == null ? null : root.search(k);
}
void insert(int k) {
if (root == null) {
root = new BTreeNode(t, true);
root.keys[0] = k;
root.n = 1;
} else {
if (root.n == 2 * t - 1) {
BTreeNode s = new BTreeNode(t, false);
s.C[0] = root;
s.splitChild(0, root);
int i = 0;
if (s.keys[0] < k) {
i++;
}
s.C[i].insertNonFull(k);
root = s;
} else {
root.insertNonFull(k);
}
}
}
}
class Main {
public static void main(String[] args) {
BTree t = new BTree(3);
t.insert(10);
t.insert(20);
t.insert(5);
t.insert(6);
t.insert(12);
t.insert(30);
t.insert(7);
t.insert(17);
System.out.print("Traversal of the constructed tree is ");
t.traverse();
System.out.println();
int key = 6;
if (t.search(key) != null) {
System.out.println(" | Present");
} else {
System.out.println(" | Not Present");
}
key = 15;
if (t.search(key) != null) {
System.out.println(" | Present");
} else {
System.out.println(" | Not Present");
}
}
}
using System;
// Class representing a B-tree node
public class BTreeNode
{
public int[] keys; // An array of keys
public BTreeNode[] C; // An array of child pointers
public int n; // Current number of keys
public bool leaf; // Indicates whether the node is a leaf
public int t; // Minimum degree (defines the range for the number of keys)
// Constructor to initialize a B-tree node
public BTreeNode(int t, bool leaf)
{
this.t = t;
this.leaf = leaf;
this.keys = new int[2 * t - 1];
this.C = new BTreeNode[2 * t];
this.n = 0;
}
// Function to insert a new key in a non-full node
public void InsertNonFull(int k)
{
int i = n - 1;
if (leaf)
{
// Insert key into a leaf node
while (i >= 0 && keys[i] > k)
{
keys[i + 1] = keys[i];
i--;
}
keys[i + 1] = k;
n++;
}
else
{
// Insert key into a non-leaf node
while (i >= 0 && keys[i] > k)
{
i--;
}
if (C[i + 1].n == 2 * t - 1)
{
// Split the child if it is full
SplitChild(i + 1, C[i + 1]);
if (keys[i + 1] < k)
{
i++;
}
}
C[i + 1].InsertNonFull(k);
}
}
// Function to split a full child node
public void SplitChild(int i, BTreeNode y)
{
BTreeNode z = new BTreeNode(y.t, y.leaf);
z.n = t - 1;
// Copy the second half of keys from y to z
for (int j = 0; j < t - 1; j++)
{
z.keys[j] = y.keys[j + t];
}
// Copy the second half of child pointers from y to z if y is not a leaf
if (!y.leaf)
{
for (int j = 0; j < t; j++)
{
z.C[j] = y.C[j + t];
}
}
y.n = t - 1;
// Rearrange keys and child pointers in the parent node
for (int j = n; j > i; j--)
{
C[j + 1] = C[j];
}
C[i + 1] = z;
for (int j = n - 1; j >= i; j--)
{
keys[j + 1] = keys[j];
}
keys[i] = y.keys[t - 1];
n++;
}
// Function to traverse all nodes in a subtree rooted with this node
public void Traverse()
{
int i;
for (i = 0; i < n; i++)
{
if (!leaf)
{
C[i].Traverse();
}
Console.Write(keys[i] + " ");
}
if (!leaf)
{
C[i].Traverse();
}
}
// Function to search a key in the subtree rooted with this node
public BTreeNode Search(int k)
{
int i = 0;
while (i < n && k > keys[i])
{
i++;
}
if (i < n && k == keys[i])
{
return this;
}
return leaf ? null : C[i].Search(k);
}
}
// Class representing a B-tree
public class BTree
{
public BTreeNode root; // Pointer to root node
public int t; // Minimum degree
// Constructor to initialize a B-tree
public BTree(int t)
{
this.t = t;
root = null;
}
// Function to traverse the tree
public void Traverse()
{
if (root != null)
{
root.Traverse();
}
}
// Function to search a key in this tree
public BTreeNode Search(int k)
{
return root == null ? null : root.Search(k);
}
// Main function to insert a new key in this B-tree
public void Insert(int k)
{
if (root == null)
{
// If the tree is empty, create a new root
root = new BTreeNode(t, true);
root.keys[0] = k;
root.n = 1;
}
else
{
if (root.n == 2 * t - 1)
{
// If the root is full, create a new root and split the old root
BTreeNode s = new BTreeNode(t, false);
s.C[0] = root;
s.SplitChild(0, root);
int i = 0;
if (s.keys[0] < k)
{
i++;
}
s.C[i].InsertNonFull(k);
root = s;
}
else
{
// If the root is not full, insert into the root
root.InsertNonFull(k);
}
}
}
}
class Program
{
static void Main()
{
BTree t = new BTree(3); // A B-tree with a minimum degree of 3
t.Insert(10);
t.Insert(20);
t.Insert(5);
t.Insert(6);
t.Insert(12);
t.Insert(30);
t.Insert(7);
t.Insert(17);
Console.Write("Traversal of the constructed tree is ");
t.Traverse();
Console.WriteLine();
int k = 6;
Console.WriteLine(t.Search(k) != null ? "Present" : "Not Present");
k = 15;
Console.WriteLine(t.Search(k) != null ? "Present" : "Not Present");
}
}
class BTreeNode {
constructor(t, leaf) {
this.keys = Array(2 * t - 1).fill(null); // An array of keys
this.t = t; // Minimum degree (defines the range for the number of keys)
this.C = Array(2 * t).fill(null); // An array of child pointers
this.n = 0; // Current number of keys
this.leaf = leaf; // Is true when the node is a leaf, otherwise false
}
// A utility function to insert a new key in the subtree rooted with
// this node. The assumption is that the node must be non-full when this
// function is called
insertNonFull(k) {
let i = this.n - 1;
if (this.leaf) {
while (i >= 0 && this.keys[i] > k) {
this.keys[i + 1] = this.keys[i];
i--;
}
this.keys[i + 1] = k;
this.n++;
} else {
while (i >= 0 && this.keys[i] > k) {
i--;
}
if (this.C[i + 1].n === 2 * this.t - 1) {
this.splitChild(i + 1, this.C[i + 1]);
if (this.keys[i + 1] < k) {
i++;
}
}
this.C[i + 1].insertNonFull(k);
}
}
// A utility function to split the child y of this node. i is the index of y in
// the child array C[]. The Child y must be full when this function is called
splitChild(i, y) {
const z = new BTreeNode(y.t, y.leaf);
z.n = this.t - 1;
for (let j = 0; j < this.t - 1; j++) {
z.keys[j] = y.keys[j + this.t];
}
if (!y.leaf) {
for (let j = 0; j < this.t; j++) {
z.C[j] = y.C[j + this.t];
}
}
y.n = this.t - 1;
for (let j = this.n; j > i; j--) {
this.C[j + 1] = this.C[j];
}
this.C[i + 1] = z;
for (let j = this.n - 1; j >= i; j--) {
this.keys[j + 1] = this.keys[j];
}
this.keys[i] = y.keys[this.t - 1];
this.n++;
}
// A function to traverse all nodes in a subtree rooted with this node
traverse() {
for (let i = 0; i < this.n; i++) {
if (!this.leaf) {
this.C[i].traverse();
}
console.log(this.keys[i]);
}
if (!this.leaf) {
this.C[this.n].traverse();
}
}
// A function to search a key in the subtree rooted with this node
search(k) {
let i = 0;
while (i < this.n && k > this.keys[i]) {
i++;
}
if (i < this.n && k === this.keys[i]) {
return this;
}
if (this.leaf) {
return null;
}
return this.C[i].search(k);
}
}
// A BTree
class BTree {
constructor(t) {
this.root = null; // Pointer to the root node
this.t = t; // Minimum degree
}
// Function to traverse the tree
traverse() {
if (this.root !== null) {
this.root.traverse();
}
}
// Function to search a key in this tree
search(k) {
return this.root === null ? null : this.root.search(k);
}
// The main function that inserts a new key in this B-Tree
insert(k) {
if (this.root === null) {
this.root = new BTreeNode(this.t, true);
this.root.keys[0] = k; // Insert key
this.root.n = 1;
} else {
if (this.root.n === 2 * this.t - 1) {
const s = new BTreeNode(this.t, false);
s.C[0] = this.root;
s.splitChild(0, this.root);
let i = 0;
if (s.keys[0] < k) {
i++;
}
s.C[i].insertNonFull(k);
this.root = s;
} else {
this.root.insertNonFull(k);
}
}
}
}
// Driver program to test above functions
const t = new BTree(3); // A B-Tree with a minimum degree of 3
t.insert(10);
t.insert(20);
t.insert(5);
t.insert(6);
t.insert(12);
t.insert(30);
t.insert(7);
t.insert(17);
console.log("Traversal of the constructed tree is ");
t.traverse();
console.log();
let key = 6;
if (t.search(key) !== null) {
console.log("Present");
} else {
console.log("Not Present");
}
key = 15;
if (t.search(key) !== null) {
console.log("Present");
} else {
console.log("Not Present");
}
# Python program for B-Tree insertion
class BTreeNode:
def __init__(self, t, leaf):
self.keys = [None] * (2 * t - 1) # An array of keys
self.t = t # Minimum degree (defines the range for number of keys)
self.C = [None] * (2 * t) # An array of child pointers
self.n = 0 # Current number of keys
self.leaf = leaf # Is true when node is leaf. Otherwise false
# A utility function to insert a new key in the subtree rooted with
# this node. The assumption is, the node must be non-full when this
# function is called
def insertNonFull(self, k):
i = self.n - 1
if self.leaf:
while i >= 0 and self.keys[i] > k:
self.keys[i + 1] = self.keys[i]
i -= 1
self.keys[i + 1] = k
self.n += 1
else:
while i >= 0 and self.keys[i] > k:
i -= 1
if self.C[i + 1].n == 2 * self.t - 1:
self.splitChild(i + 1, self.C[i + 1])
if self.keys[i + 1] < k:
i += 1
self.C[i + 1].insertNonFull(k)
# A utility function to split the child y of this node. i is index of y in
# child array C[]. The Child y must be full when this function is called
def splitChild(self, i, y):
z = BTreeNode(y.t, y.leaf)
z.n = self.t - 1
for j in range(self.t - 1):
z.keys[j] = y.keys[j + self.t]
if not y.leaf:
for j in range(self.t):
z.C[j] = y.C[j + self.t]
y.n = self.t - 1
for j in range(self.n, i, -1):
self.C[j + 1] = self.C[j]
self.C[i + 1] = z
for j in range(self.n - 1, i - 1, -1):
self.keys[j + 1] = self.keys[j]
self.keys[i] = y.keys[self.t - 1]
self.n += 1
# A function to traverse all nodes in a subtree rooted with this node
def traverse(self):
for i in range(self.n):
if not self.leaf:
self.C[i].traverse()
print(self.keys[i], end=' ')
if not self.leaf:
self.C[i + 1].traverse()
# A function to search a key in the subtree rooted with this node.
def search(self, k):
i = 0
while i < self.n and k > self.keys[i]:
i += 1
if i < self.n and k == self.keys[i]:
return self
if self.leaf:
return None
return self.C[i].search(k)
# A BTree
class BTree:
def __init__(self, t):
self.root = None # Pointer to root node
self.t = t # Minimum degree
# function to traverse the tree
def traverse(self):
if self.root != None:
self.root.traverse()
# function to search a key in this tree
def search(self, k):
return None if self.root == None else self.root.search(k)
# The main function that inserts a new key in this B-Tree
def insert(self, k):
if self.root == None:
self.root = BTreeNode(self.t, True)
self.root.keys[0] = k # Insert key
self.root.n = 1
else:
if self.root.n == 2 * self.t - 1:
s = BTreeNode(self.t, False)
s.C[0] = self.root
s.splitChild(0, self.root)
i = 0
if s.keys[0] < k:
i += 1
s.C[i].insertNonFull(k)
self.root = s
else:
self.root.insertNonFull(k)
# Driver program to test above functions
if __name__ == '__main__':
t = BTree(3) # A B-Tree with minimum degree 3
t.insert(10)
t.insert(20)
t.insert(5)
t.insert(6)
t.insert(12)
t.insert(30)
t.insert(7)
t.insert(17)
print("Traversal of the constructed tree is ", end = ' ')
t.traverse()
print()
k = 6
if t.search(k) != None:
print("Present")
else:
print("Not Present")
k = 15
if t.search(k) != None:
print("Present")
else:
print("Not Present")
OutputTraversal of the constructed tree is 5 6 7 10 12 17 20 30
Present
Not Present
The B-tree is a data structure that is similar to a binary search tree, but allows multiple keys per node and has a higher fanout. This allows the B-tree to store a large amount of data in an efficient manner, and it is commonly used in database and file systems.
The B-tree is a balanced tree, which means that all paths from the root to a leaf have the same length. The tree has a minimum degree t, which is the minimum number of keys in a non-root node. Each node can have at most 2t-1 keys and 2t children. The root can have at least one key and at most 2t-1 keys. All non-root nodes have at least t-1 keys and at most 2t-1 keys.
The B-tree supports the following operations:
Search(k): search for a key k in the tree.
Insert(k): insert a key k into the tree.
Delete(k): delete a key k from the tree.
The search operation is similar to that of a binary search tree. The insert operation is more complicated, since inserting a key can cause a node to become full. If a node is full, it must be split into two nodes, and the median key moved up to the parent node. The delete operation is also more complicated, since deleting a key can cause a node to have too few keys. If a node has too few keys, it can be merged with a sibling node or borrow a key from a sibling node.
The B-tree has a number of advantages over other data structures. It has a higher fanout than binary search trees, which means that fewer disk accesses are required to search for a key. It is also a balanced tree, which means that all operations have a worst-case time complexity of O(log n). Finally, the B-tree is self-adjusting, which means that it can adapt to changes in the data set without requiring expensive rebalancing operations.
References:
Introduction to Algorithms 3rd Edition by Clifford Stein, Thomas H. Cormen, Charles E. Leiserson, Ronald L. Rivest
http://www.cs.utexas.edu/users/djimenez/utsa/cs3343/lecture17.html
Share your thoughts in the comments
Please Login to comment...