Python | Pandas dataframe.cov()
Last Updated :
16 Nov, 2018
Python is a great language for doing data analysis, primarily because of the fantastic ecosystem of data-centric python packages. Pandas is one of those packages and makes importing and analyzing data much easier.
Pandas dataframe.cov() is used to compute pairwise covariance of columns.
If some of the cells in a column contain NaN value, then it is ignored.
Syntax: DataFrame.cov(min_periods=None)
Parameters:
min_periods : Minimum number of observations required per pair of columns to have a valid result.
Returns: y : DataFrame
Example #1: Use cov() function to find the covariance between the columns of the dataframe.
Note : Any non-numeric columns will be ignored.
import pandas as pd
df = pd.DataFrame({"A":[5, 3, 6, 4],
"B":[11, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, 8]})
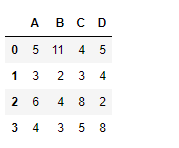
df
|
Output :
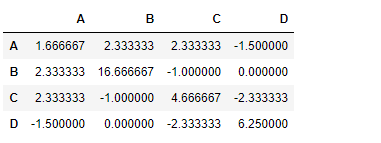
Now find the covariance among the columns of the data frame
Output :
Example #2: Use cov() function to find the covariance between the columns of the dataframe which are having NaN value.
import pandas as pd
df = pd.DataFrame({"A":[5, 3, None, 4],
"B":[None, 2, 4, 3],
"C":[4, 3, 8, 5],
"D":[5, 4, 2, None]})
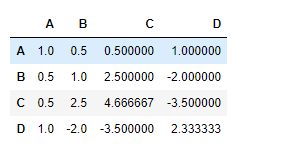
df.cov()
|
Output :
Share your thoughts in the comments
Please Login to comment...