NLP | Part of speech tagged – word corpus
Last Updated :
11 Apr, 2022
What is Part-of-speech (POS) tagging ?
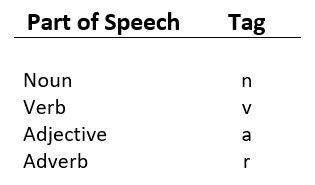
It is a process of converting a sentence to forms – list of words, list of tuples (where each tuple is having a form (word, tag)). The tag in case of is a part-of-speech tag, and signifies whether the word is a noun, adjective, verb, and so on.
Example of Part-of-speech (POS) tagged corpus
The/at-tl expense/nn and/cc time/nn involved/vbn are/ber astronomical/jj ./.
format for a tagged corpus is of the form word/tag. Each word is with a tag denoting its POS. For example, nn refers to a noun, vb is a verb.
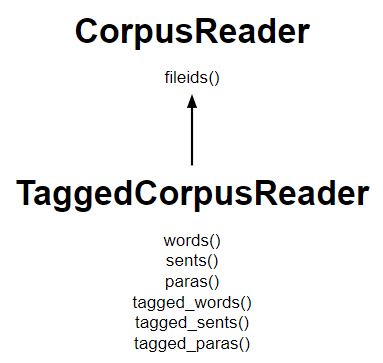
Code #1 : Creating a TaggedCorpusReader. for words
Python3
from nltk.corpus.reader import TaggedCorpusReader
x = TaggedCorpusReader('.', r'.*\.pos')
words = x.words()
print ("Words : \n", words)
tag_words = x.tagged_words()
print ("\ntag_words : \n", tag_words)
|
Output :
Words :
['The', 'expense', 'and', 'time', 'involved', 'are', ...]
tag_words :
[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ...]
Code #2 : For sentence
Python3
tagged_sent = x.tagged_sents()
print ("tagged_sent : \n", tagged_sent)
|
Output :
tagged_sent :
[[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ('time', 'NN'),
('involved', 'VBN'), ('are', 'BER'), ('astronomical', 'JJ'), ('.', '.')]]
Code #3 : For paragraphs
Python3
para = x.para()
print ("para : \n", para)
tagged_para = x.tagged_paras()
print ("\ntagged_paras : \n", tagged_paras)
|
Output :
para:
[[['The', 'expense', 'and', 'time', 'involved', 'are', 'astronomical', '.']]]
tagged_paras :
[[[('The', 'AT-TL'), ('expense', 'NN'), ('and', 'CC'), ('time', 'NN'),
('involved', 'VBN'), ('are', 'BER'), ('astronomical', 'JJ'), ('.', '.')]]]
Share your thoughts in the comments
Please Login to comment...