NLP | Chunking using Corpus Reader
Last Updated :
24 Dec, 2021
What are Chunks?
These are made up of words and the kinds of words are defined using the part-of-speech tags. One can even define a pattern or words that can’t be a part of chuck and such words are known as chinks. A ChunkRule class specifies what words or patterns to include and exclude in a chunk.
How it works :
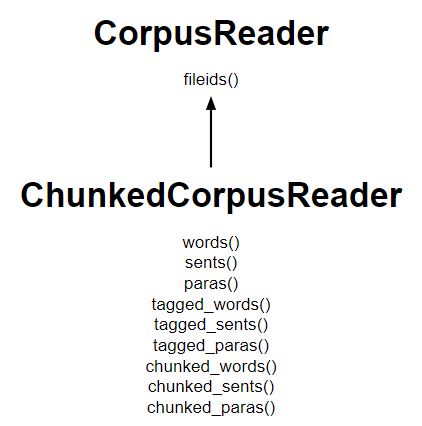
- The ChunkedCorpusReader class works similar to the TaggedCorpusReader for getting tagged tokens, plus it also provides three new methods for getting chunks.
- An instance of nltk.tree.Tree represents each chunk.
- Noun phrase trees look like Tree(‘NP’, […]) where as Sentence level trees look like Tree(‘S’, […]).
- A list of sentence trees, with each noun phrase as a subtree of the sentence is obtained in n chunked_sents()
- A list of noun phrase trees alongside tagged tokens of words that were not in a chunk is obtained in chunked_words().
Diagram listing the major methods:
Code #1 : Creating a ChunkedCorpusReader for words
Python3
from nltk.corpus.reader import ChunkedCorpusReader
x = ChunkedCorpusReader('.', r'.*\.chunk')
words = x.chunked_words()
print ("Words : \n", words)
|
Output :
Words :
[Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ...]
Code #2 : For sentence
Python3
Chunked Sentence = x.chunked_sents()
print ("Chunked Sentence : \n", tagged_sent)
|
Output :
Chunked Sentence :
[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction', 'NN'),
('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'), ('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]
Code #3 : For paragraphs
Python3
para = x.chunked_paras()()
print ("para : \n", para)
|
Output :
[[Tree('S', [Tree('NP', [('Earlier', 'JJR'), ('staff-reduction',
'NN'), ('moves', 'NNS')]), ('have', 'VBP'), ('trimmed', 'VBN'),
('about', 'IN'),
Tree('NP', [('300', 'CD'), ('jobs', 'NNS')]), (', ', ', '),
Tree('NP', [('the', 'DT'), ('spokesman', 'NN')]), ('said', 'VBD'), ('.', '.')])]]
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...