ML | Types of Linkages in Clustering
Last Updated :
20 Mar, 2024
Prerequisites: Hierarchical Clustering
Hierarchical clustering is a versatile technique used in machine learning and data analysis for grouping similar data points into clusters. This process involves organizing the data points into a hierarchical structure, where clusters are either merged into larger clusters in a bottom-up approach (agglomerative) or divided into smaller clusters in a top-down approach (divisive). Regardless of the direction, the computation of distances between sub-clusters is crucial in hierarchical clustering.
The various types of linkages describe distinct methods for measuring the distance between two sub-clusters of data points, influencing the overall clustering outcome.
Single Linkage:
For two clusters R and S, the single linkage returns the minimum distance between two points i and j such that i belongs to R and j belongs to S.

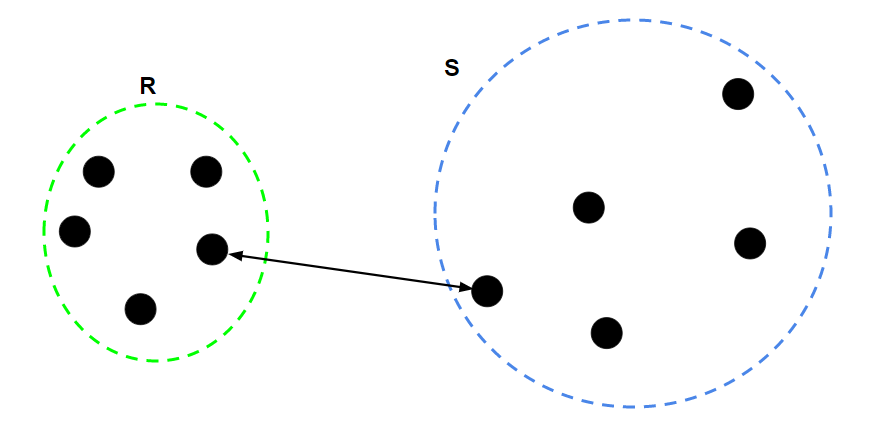
2. Complete Linkage:
For two clusters R and S, the complete linkage returns the maximum distance between two points i and j such that i belongs to R and j belongs to S.

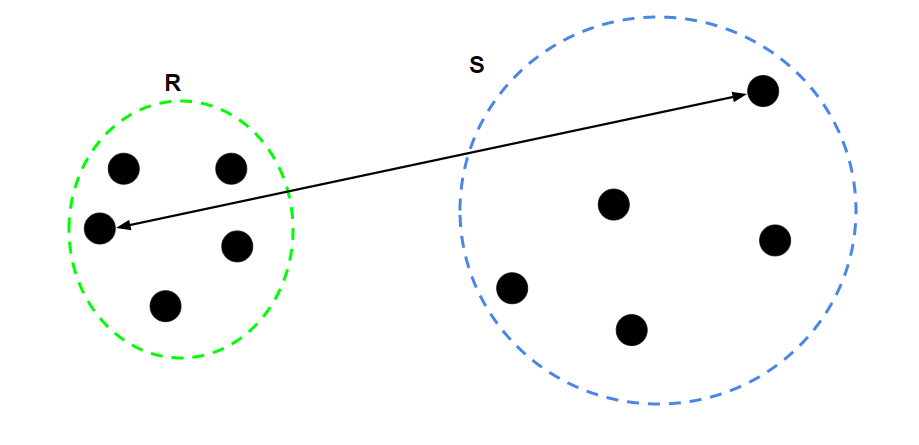
3. Average Linkage:
For two clusters R and S, first for the distance between any data-point i in R and any data-point j in S and then the arithmetic mean of these distances are calculated. Average Linkage returns this value of the arithmetic mean.

where,
 : Number of data-points in R
: Number of data-points in R  : Number of data-points in S
: Number of data-points in S
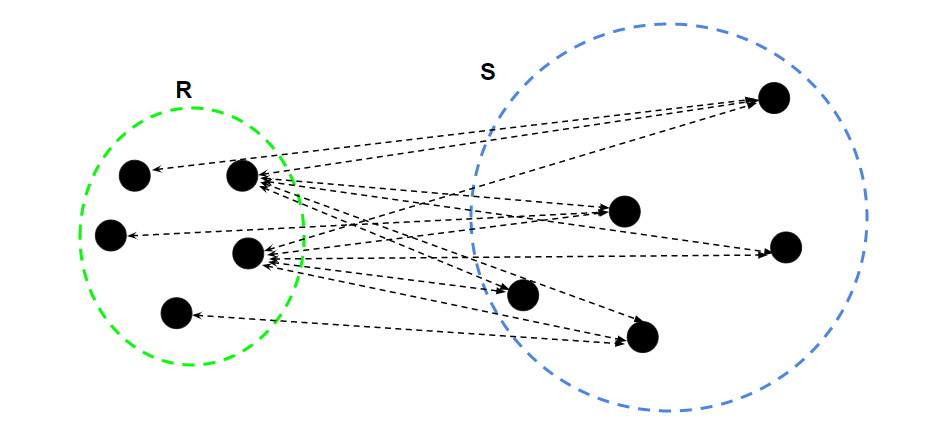
Share your thoughts in the comments
Please Login to comment...