Iterative Deepening Search(IDS) or Iterative Deepening Depth First Search(IDDFS)
Last Updated :
20 Feb, 2023
There are two common ways to traverse a graph, BFS and DFS. Considering a Tree (or Graph) of huge height and width, both BFS and DFS are not very efficient due to following reasons.
- DFS first traverses nodes going through one adjacent of root, then next adjacent. The problem with this approach is, if there is a node close to root, but not in first few subtrees explored by DFS, then DFS reaches that node very late. Also, DFS may not find shortest path to a node (in terms of number of edges).
- BFS goes level by level, but requires more space. The space required by DFS is O(d) where d is depth of tree, but space required by BFS is O(n) where n is number of nodes in tree (Why? Note that the last level of tree can have around n/2 nodes and second last level n/4 nodes and in BFS we need to have every level one by one in queue).
IDDFS combines depth-first search’s space-efficiency and breadth-first search’s fast search (for nodes closer to root).
How does IDDFS work?
IDDFS calls DFS for different depths starting from an initial value. In every call, DFS is restricted from going beyond given depth. So basically we do DFS in a BFS fashion.
Algorithm:
// Returns true if target is reachable from
// src within max_depth
bool IDDFS(src, target, max_depth)
for limit from 0 to max_depth
if DLS(src, target, limit) == true
return true
return false
bool DLS(src, target, limit)
if (src == target)
return true;
// If reached the maximum depth,
// stop recursing.
if (limit <= 0)
return false;
foreach adjacent i of src
if DLS(i, target, limit?1)
return true
return false
An important thing to note is, we visit top level nodes multiple times. The last (or max depth) level is visited once, second last level is visited twice, and so on. It may seem expensive, but it turns out to be not so costly, since in a tree most of the nodes are in the bottom level. So it does not matter much if the upper levels are visited multiple times. Below is implementation of above algorithm
C++
#include<bits/stdc++.h>
using namespace std;
class Graph
{
int V;
list<int> *adj;
bool DLS(int v, int target, int limit);
public:
Graph(int V);
void addEdge(int v, int w);
bool IDDFS(int v, int target, int max_depth);
};
Graph::Graph(int V)
{
this->V = V;
adj = new list<int>[V];
}
void Graph::addEdge(int v, int w)
{
adj[v].push_back(w);
}
bool Graph::DLS(int src, int target, int limit)
{
if (src == target)
return true;
if (limit <= 0)
return false;
for (auto i = adj[src].begin(); i != adj[src].end(); ++i)
if (DLS(*i, target, limit-1) == true)
return true;
return false;
}
bool Graph::IDDFS(int src, int target, int max_depth)
{
for (int i = 0; i <= max_depth; i++)
if (DLS(src, target, i) == true)
return true;
return false;
}
int main()
{
Graph g(7);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(2, 6);
int target = 6, maxDepth = 3, src = 0;
if (g.IDDFS(src, target, maxDepth) == true)
cout << "Target is reachable from source "
"within max depth";
else
cout << "Target is NOT reachable from source "
"within max depth";
return 0;
}
|
Java
import java.util.*;
class Graph {
int V;
LinkedList<Integer> adj[];
boolean DLS(int v, int target, int limit)
{
if (v == target)
return true;
if (limit <= 0)
return false;
for (int i : adj[v])
if (DLS(i, target, limit - 1))
return true;
return false;
}
public Graph(int v)
{
V = v;
adj = new LinkedList[v];
for (int i = 0; i < v; ++i)
adj[i] = new LinkedList();
}
void addEdge(int v, int w)
{
adj[v].add(w);
}
boolean IDDFS(int src, int target, int max_depth)
{
for (int i = 0; i <= max_depth; i++)
if (DLS(src, target, i))
return true;
return false;
}
}
class Main {
public static void main(String[] args)
{
Graph g = new Graph(7);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(2, 6);
int target = 6, maxDepth = 3, src = 0;
if (g.IDDFS(src, target, maxDepth))
System.out.println(
"Target is reachable from source "
+ "within max depth");
else
System.out.println(
"Target is NOT reachable from source "
+ "within max depth");
}
}
|
Python
from collections import defaultdict
class Graph:
def __init__(self,vertices):
self.V = vertices
self.graph = defaultdict(list)
def addEdge(self,u,v):
self.graph[u].append(v)
def DLS(self,src,target,maxDepth):
if src == target : return True
if maxDepth <= 0 : return False
for i in self.graph[src]:
if(self.DLS(i,target,maxDepth-1)):
return True
return False
def IDDFS(self,src, target, maxDepth):
for i in range(maxDepth):
if (self.DLS(src, target, i)):
return True
return False
g = Graph (7);
g.addEdge(0, 1)
g.addEdge(0, 2)
g.addEdge(1, 3)
g.addEdge(1, 4)
g.addEdge(2, 5)
g.addEdge(2, 6)
target = 6; maxDepth = 3; src = 0
if g.IDDFS(src, target, maxDepth) == True:
print ("Target is reachable from source " +
"within max depth")
else :
print ("Target is NOT reachable from source " +
"within max depth")
|
C#
using System;
using System.Collections.Generic;
class Graph {
private int V;
private List<int>[] adj;
public Graph(int V)
{
this.V = V;
adj = new List<int>[ V ];
for (int i = 0; i < V; ++i)
adj[i] = new List<int>();
}
public void addEdge(int v, int w) { adj[v].Add(w); }
private bool DLS(int v, int target, int limit)
{
if (v == target)
return true;
if (limit <= 0)
return false;
foreach(
int i in adj[v]) if (DLS(i, target,
limit
- 1)) return true;
return false;
}
public bool IDDFS(int src, int target, int max_depth)
{
for (int i = 0; i <= max_depth; i++)
if (DLS(src, target, i))
return true;
return false;
}
}
class Program {
static void Main(string[] args)
{
Graph g = new Graph(7);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(2, 6);
int target = 6, maxDepth = 3, src = 0;
if (g.IDDFS(src, target, maxDepth))
Console.WriteLine(
"Target is reachable from source within max depth");
else
Console.WriteLine(
"Target is NOT reachable from source within max depth");
}
}
|
Javascript
<script>
class Graph
{
constructor(V)
{
this.V = V;
this.adj = new Array(V);
for(let i = 0; i < V; i++)
this.adj[i] = [];
}
addEdge(v, w)
{
this.adj[v].push(w);
}
DLS(src, target, limit)
{
if (src == target)
return true;
if (limit <= 0)
return false;
for (let i of this.adj[src].values())
{
if (this.DLS(i, target, limit-1) == true)
return true;
}
return false;
}
IDDFS(src, target, max_depth)
{
for (let i = 0; i <= max_depth; i++)
{
if (this.DLS(src, target, i) == true)
return true;
}
return false;
}
}
g = new Graph(7);
g.addEdge(0, 1);
g.addEdge(0, 2);
g.addEdge(1, 3);
g.addEdge(1, 4);
g.addEdge(2, 5);
g.addEdge(2, 6);
let target = 6, maxDepth = 3, src = 0;
if (g.IDDFS(src, target, maxDepth) == true)
document.write("Target is reachable from source within max depth");
else
document.write("Target is NOT reachable from source within max depth");
</script>
|
Output
Target is reachable from source within max depth
Illustration: There can be two cases:
- When the graph has no cycle: This case is simple. We can DFS multiple times with different height limits.
- When the graph has cycles. This is interesting as there is no visited flag in IDDFS.
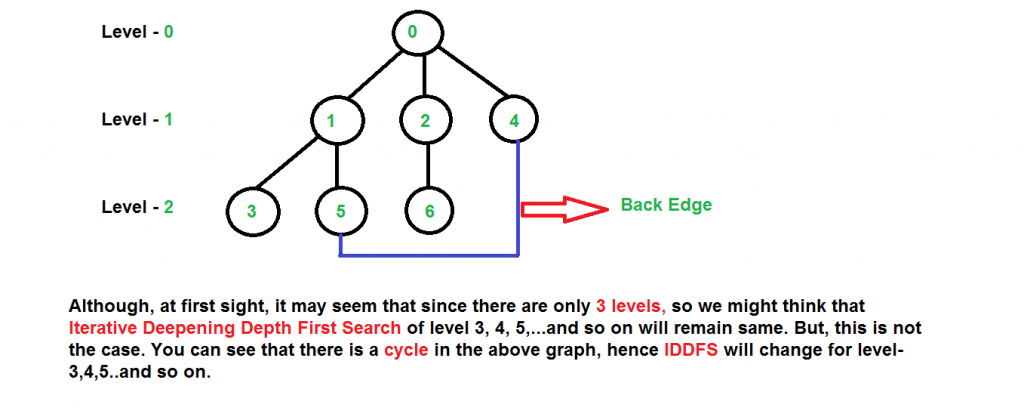
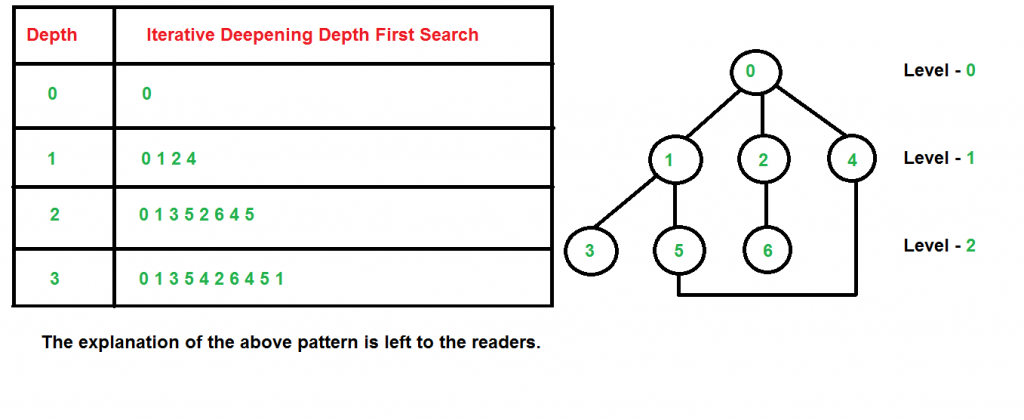
Time Complexity: Suppose we have a tree having branching factor ‘b’ (number of children of each node), and its depth ‘d’, i.e., there are bd nodes. In an iterative deepening search, the nodes on the bottom level are expanded once, those on the next to bottom level are expanded twice, and so on, up to the root of the search tree, which is expanded d+1 times. So the total number of expansions in an iterative deepening search is-
(d)b + (d-1)b2 + .... + 3bd-2 + 2bd-1 + bd
That is,
Summation[(d + 1 - i) bi], from i = 0 to i = d
Which is same as O(bd)
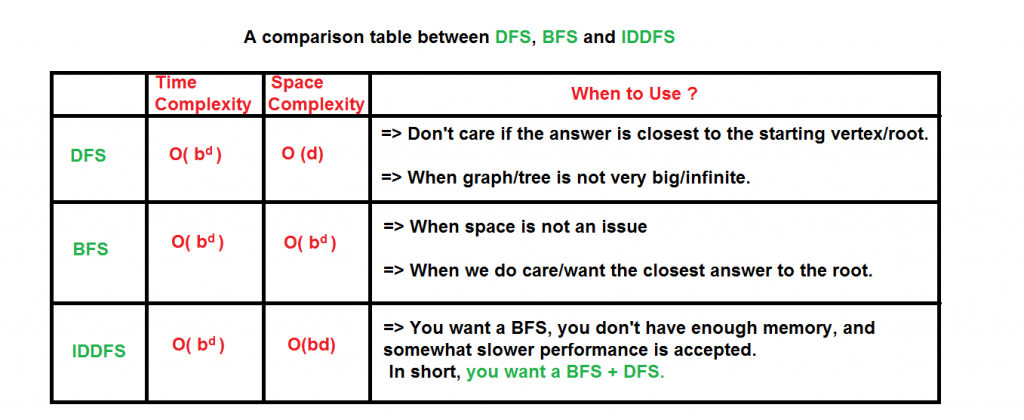
After evaluating the above expression, we find that asymptotically IDDFS takes the same time as that of DFS and BFS, but it is indeed slower than both of them as it has a higher constant factor in its time complexity expression. IDDFS is best suited for a complete infinite tree
Complexity:
Time: O(b^d)
Space: O(d)
Share your thoughts in the comments
Please Login to comment...