Impact of Dataset Size on Deep Learning Model
Last Updated :
09 Apr, 2024
In the field of deep learning, where models are designed to learn intricate patterns and representations from data, the significance of the dataset size cannot be overstated. The amount of data available for training has a profound impact on the performance, robustness, and generalization capabilities of deep learning models. In this article, we will observe the effects of dataset size on deep learning models by focusing on a single code example that demonstrates how varying dataset sizes influence model performance.
Why is dataset size important?
Deep learning models learn to recognize patterns by analyzing vast amounts of data. The fundamental principle behind this is that more data enables the model to learn more diverse and nuanced representations, leading to better performance. A larger dataset provides the model with more examples to learn from, thereby reducing the chances of overfitting and improving its ability to generalize to unseen data.
Impact on Model Performance
- Overfitting vs. Generalization: Overfitting occurs when a model learns to perform well on the training data but fails to generalize to new, unseen data. A small dataset exacerbates this issue, as the model may memorize noise or outliers present in the limited training samples. In contrast, a larger dataset helps mitigate overfitting by exposing the model to a more comprehensive representation of the underlying data distribution, resulting in improved generalization to unseen examples.
- Improved Generalization : Deep learning models trained on larger datasets tend to generalize better to unseen examples. By training on a diverse and extensive dataset, the model learns more robust and invariant representations, leading to better performance on real-world tasks.
- Model Complexity and Capacity: The size of the dataset influences the complexity and capacity of the deep learning model. With a small dataset, using a highly complex model may lead to overfitting, as the model can easily memorize the limited training samples. Conversely, a larger dataset can support the use of more complex models without overfitting, allowing the model to capture intricate patterns and variations present in the data.
Implementation of Using Different Dataset Size
To illustrate the impact of dataset size on model performance, let’s consider a simple image classification task using the CIFAR-10 dataset. We’ll train a convolutional neural network (CNN) with varying sizes of training data and observe how the model’s performance changes.
Importing Libraries
- The code begins by importing the necessary libraries. TensorFlow is imported to build and train deep learning models, Keras is utilized for constructing neural network architectures, and Matplotlib is included for visualizing training metrics.
Python3
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
Loading CIFAR-10 Dataset
- The CIFAR-10 dataset, comprising 60,000 32×32 color images in 10 classes, is loaded using the datasets.cifar10.load_data() function.
- This dataset serves as a benchmark for image classification tasks.
Python3
(train_images, train_labels), (test_images, test_labels) = datasets.cifar10.load_data()
Data Preprocessing
- The pixel values of the images are normalized to the range [0, 1] by dividing each pixel value by 255.0.
- This normalization ensures that the input data is within a suitable range for training neural networks.
Python3
train_images, test_images = train_images / 255.0, test_images / 255.0
Defining CNN Architecture
- A CNN architecture is defined using the Sequential API provided by Keras.
- This architecture comprises convolutional layers followed by max-pooling layers for feature extraction, and fully connected (dense) layers for classification.
Python3
model = models.Sequential([
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.MaxPooling2D((2, 2)),
layers.Conv2D(64, (3, 3), activation='relu'),
layers.Flatten(),
layers.Dense(64, activation='relu'),
layers.Dense(10)
])
Compiling the Model
- The model is compiled with the Adam optimizer and sparse categorical cross-entropy loss function, suitable for multi-class classification tasks.
- Additionally, accuracy is chosen as the metric to monitor during training.
Python3
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
Training and Evaluation Function
- A function train_and_evaluate() is defined to train the model and visualize its performance.
- It takes the size of the training data as input and trains the model for a fixed number of epochs (10 in this case), while validating on the test set. The training and validation accuracy are then plotted over epochs to assess model performance.
Python3
def train_and_evaluate(train_size):
history = model.fit(train_images[:train_size], train_labels[:train_size], epochs=10,
validation_data=(test_images, test_labels))
plt.plot(history.history['accuracy'], label='accuracy')
plt.plot(history.history['val_accuracy'], label = 'val_accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.ylim([0, 1])
plt.legend(loc='lower right')
plt.show()
Training with Different Dataset Sizes
- The train_and_evaluate() function is called iteratively with different sizes of training data (100, 1000, 5000, 10000, and 50000 samples).
- For each size, the model is trained and evaluated, and the training and validation accuracy plots are displayed.
Python3
train_sizes = [100, 1000, 5000, 10000, 50000]
for size in train_sizes:
print(f"Training with {size} samples:")
train_and_evaluate(size)
Output:
Training with 100 samples:
Epoch 1/10
4/4 [==============================] - 5s 1s/step - loss: 2.3030 - accuracy: 0.1200 - val_loss: 2.3225 - val_accuracy: 0.1000
Epoch 2/10
4/4 [==============================] - 5s 2s/step - loss: 2.2565 - accuracy: 0.1600 - val_loss: 2.3696 - val_accuracy: 0.1000
Epoch 3/10
4/4 [==============================] - 5s 2s/step - loss: 2.2302 - accuracy: 0.1600 - val_loss: 2.3489 - val_accuracy: 0.1008
.
.
.
Epoch 8/10
4/4 [==============================] - 4s 1s/step - loss: 2.1485 - accuracy: 0.1700 - val_loss: 2.2933 - val_accuracy: 0.1032
Epoch 9/10
4/4 [==============================] - 3s 1s/step - loss: 2.1483 - accuracy: 0.2400 - val_loss: 2.2892 - val_accuracy: 0.1256
Epoch 10/10
4/4 [==============================] - 5s 2s/step - loss: 2.1004 - accuracy: 0.2600 - val_loss: 2.3912 - val_accuracy: 0.1249
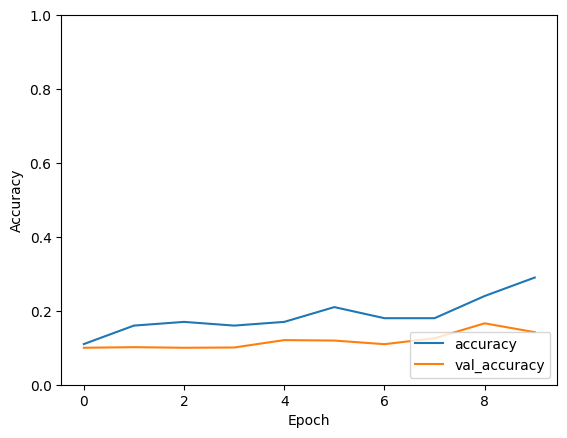
Output with 100 data points
Training with 1000 samples:
Epoch 1/10
32/32 [==============================] - 2s 71ms/step - loss: 2.2294 - accuracy: 0.1730 - val_loss: 2.1505 - val_accuracy: 0.2431
Epoch 2/10
32/32 [==============================] - 2s 49ms/step - loss: 2.0221 - accuracy: 0.2670 - val_loss: 1.9398 - val_accuracy: 0.2945
Epoch 3/10
32/32 [==============================] - 2s 51ms/step - loss: 1.8943 - accuracy: 0.3100 - val_loss: 1.8513 - val_accuracy: 0.3165
.
.
.
Epoch 8/10
32/32 [==============================] - 1s 29ms/step - loss: 1.4951 - accuracy: 0.4660 - val_loss: 1.7325 - val_accuracy: 0.3595
Epoch 9/10
32/32 [==============================] - 1s 47ms/step - loss: 1.3798 - accuracy: 0.4890 - val_loss: 1.7162 - val_accuracy: 0.3854
Epoch 10/10
32/32 [==============================] - 1s 30ms/step - loss: 1.3379 - accuracy: 0.5110 - val_loss: 1.6838 - val_accuracy: 0.3860
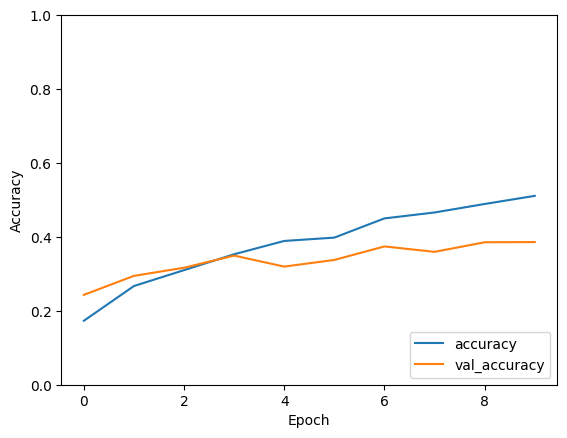
Output for 1000 data points
Training with 5000 samples:
Epoch 1/10
157/157 [==============================] - 3s 17ms/step - loss: 1.5479 - accuracy: 0.4316 - val_loss: 1.5290 - val_accuracy: 0.4495
Epoch 2/10
157/157 [==============================] - 2s 14ms/step - loss: 1.4194 - accuracy: 0.4904 - val_loss: 1.4532 - val_accuracy: 0.4793
Epoch 3/10
157/157 [==============================] - 2s 14ms/step - loss: 1.3258 - accuracy: 0.5228 - val_loss: 1.3945 - val_accuracy: 0.4989
.
.
.
Epoch 8/10
157/157 [==============================] - 2s 14ms/step - loss: 0.9636 - accuracy: 0.6604 - val_loss: 1.3662 - val_accuracy: 0.5241
Epoch 9/10
157/157 [==============================] - 2s 10ms/step - loss: 0.9253 - accuracy: 0.6746 - val_loss: 1.3837 - val_accuracy: 0.5409
Epoch 10/10
157/157 [==============================] - 2s 13ms/step - loss: 0.8462 - accuracy: 0.7042 - val_loss: 1.4249 - val_accuracy: 0.5319
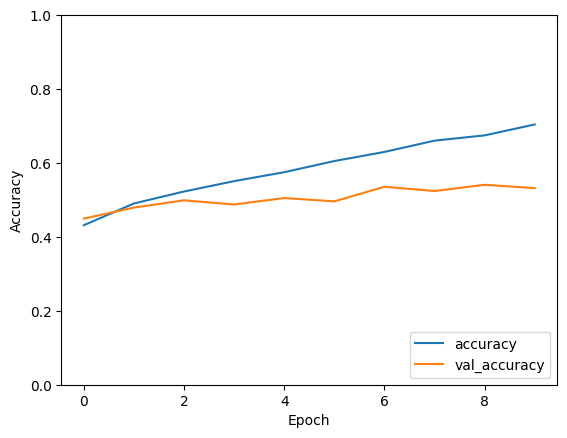
Output for 5000 data points
Training with 10000 samples:
Epoch 1/10
313/313 [==============================] - 3s 10ms/step - loss: 1.0743 - accuracy: 0.6344 - val_loss: 1.2363 - val_accuracy: 0.5682
Epoch 2/10
313/313 [==============================] - 3s 10ms/step - loss: 0.9710 - accuracy: 0.6650 - val_loss: 1.2780 - val_accuracy: 0.5637
Epoch 3/10
313/313 [==============================] - 2s 8ms/step - loss: 0.8948 - accuracy: 0.6869 - val_loss: 1.2504 - val_accuracy: 0.5703
.
.
.
Epoch 8/10
313/313 [==============================] - 3s 9ms/step - loss: 0.5643 - accuracy: 0.8052 - val_loss: 1.4885 - val_accuracy: 0.5727
Epoch 9/10
313/313 [==============================] - 3s 10ms/step - loss: 0.5106 - accuracy: 0.8253 - val_loss: 1.4424 - val_accuracy: 0.5851
Epoch 10/10
313/313 [==============================] - 2s 8ms/step - loss: 0.4473 - accuracy: 0.8448 - val_loss: 1.5830 - val_accuracy: 0.5709
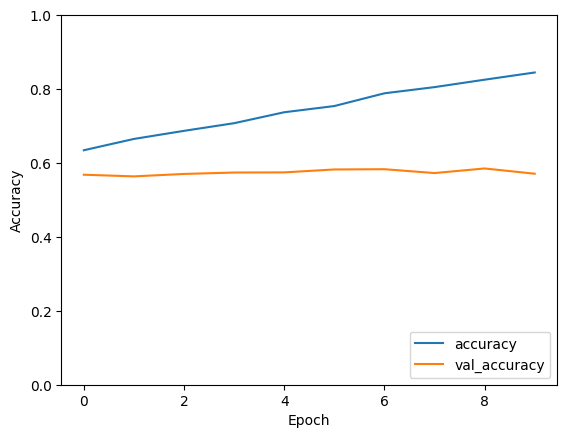
output for 10000 data points
Training with 50000 samples:
Epoch 1/10
1563/1563 [==============================] - 10s 6ms/step - loss: 1.0400 - accuracy: 0.6469 - val_loss: 1.0482 - val_accuracy: 0.6371
Epoch 2/10
1563/1563 [==============================] - 10s 6ms/step - loss: 0.9036 - accuracy: 0.6872 - val_loss: 1.0218 - val_accuracy: 0.6500
Epoch 3/10
1563/1563 [==============================] - 10s 6ms/step - loss: 0.8237 - accuracy: 0.7145 - val_loss: 0.9680 - val_accuracy: 0.6644
.
.
.
Epoch 8/10
1563/1563 [==============================] - 10s 6ms/step - loss: 0.5563 - accuracy: 0.8020 - val_loss: 0.9427 - val_accuracy: 0.6987
Epoch 9/10
1563/1563 [==============================] - 10s 6ms/step - loss: 0.5158 - accuracy: 0.8187 - val_loss: 1.0011 - val_accuracy: 0.6935
Epoch 10/10
1563/1563 [==============================] - 10s 7ms/step - loss: 0.4768 - accuracy: 0.8299 - val_loss: 1.0219 - val_accuracy: 0.6884
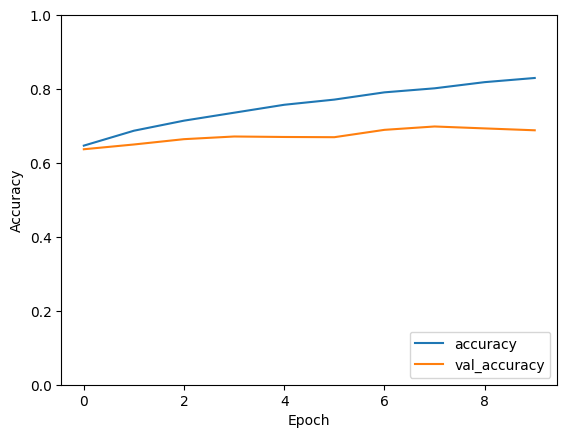
output for 50000 data points
- Training with 100 samples: With a very limited dataset of only 100 samples, the model struggles to learn meaningful patterns. Despite training for 10 epochs, both training and validation accuracies remain low, indicating poor model performance. The training accuracy reaches around 29%, while the validation accuracy stagnates around 14%, suggesting significant overfitting due to the small dataset size.
- Training with 1000 samples: Increasing the dataset size to 1000 samples leads to improved model performance. Over the course of 10 epochs, both training and validation accuracies show a noticeable increase. The model achieves a training accuracy of approximately 51% and a validation accuracy of around 39%, indicating better generalization compared to the previous scenario.
- Training with 5000 samples: With a dataset size of 5000 samples, the model exhibits further improvement in performance. The training and validation accuracies continue to increase steadily over epochs, reaching approximately 70% and 53%, respectively, by the end of training. This suggests that the model is learning more robust representations with the larger dataset.
- Training with 10000 samples:Increasing the dataset size to 10000 samples results in continued improvement in model performance. Both training and validation accuracies show consistent growth over epochs, with the model achieving training and validation accuracies of around 84% and 57%, respectively, by the end of training.
- Training with 50000 samples: Finally, with a dataset size of 50000 samples, the model achieves its highest performance. Both training and validation accuracies demonstrate significant improvement, with the model achieving a training accuracy of approximately 83% and a validation accuracy of around 69% after 10 epochs. This indicates that the model has learned highly discriminative features from the extensive dataset, resulting in superior generalization capabilities.
Training with increasingly larger datasets, from 100 to 50000 samples, demonstrates a clear trend of improving model performance. With 100 samples, the model struggles to learn meaningful patterns, showing low training and validation accuracies and significant overfitting. However, as the dataset size increases, the model’s performance steadily improves. By the time the dataset reaches 50000 samples, the model achieves its highest performance, with significantly improved training and validation accuracies, indicating superior generalization capabilities. This highlights the importance of dataset size in deep learning, as larger datasets enable the model to learn more robust representations and achieve better performance.
Share your thoughts in the comments
Please Login to comment...