How To Extract Data From Common File Formats in Python?
Last Updated :
13 Jan, 2021
Sometimes work with some datasets must have mostly worked with .csv(Comma Separated Value) files only. They are really a great starting point in applying Data Science techniques and algorithms. But many of us will land up in Data Science firms or take up real-world projects in Data Science sooner or later. Unfortunately in real-world projects, the data won’t be available to us in a neat .csv file. There we have to extract data from different sources like images, pdf files, doc files, image files, etc. In this article, we will see the perfect start to tackle those situations.
Below we will see how to extract relevant information from multiple such sources.
1. Multiple Sheet Excel Files
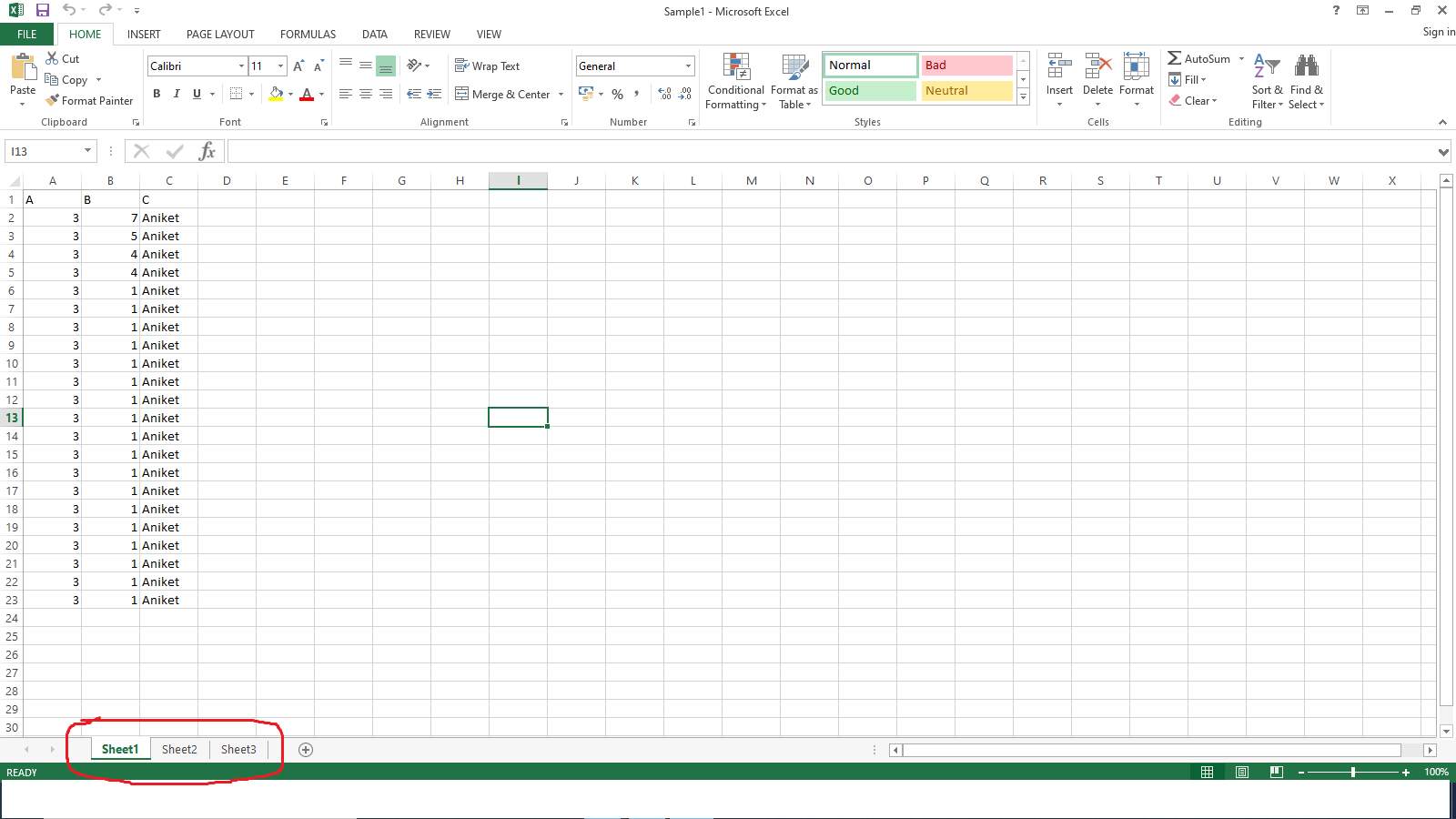
Note that if the Excel file has a single sheet then the same method to read CSV file (pd.read_csv(‘File.xlsx’)) might work. But it won’t in the case of multiple sheet files as shown in the below image where there are 3 sheets( Sheet1, Sheet2, Sheet3). In this case, it will just return the first sheet.
Excel sheet used: Click Here.
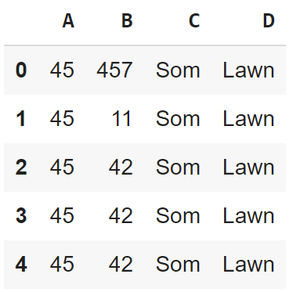
Example: We will see how to read this excel-file.
Python3
import pandas as pd
df = pd.read_excel('Sample1.xlsx', sheet_name = 1)
df.head()
|
Output:
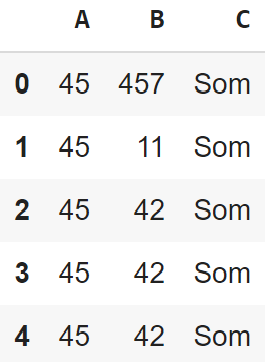
Now let’s read a selected column of the same sheet:
Python3
df=pd.read_excel('Sample1.xlsx',
sheet_name = 1, usecols = 'A : C')
df.head()
|
Output:
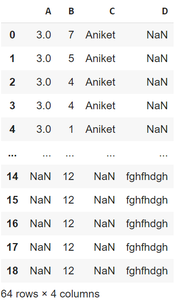
Now let’s read all sheet together:
Sheet1 contains columns A, B, C; Sheet2 contains A, B, C, D and Sheet3 contains B, D. We will see a simple example below on how to read all the 3 sheets together and merge them into common columns.
Python3
df2 = pd.DataFrame()
for i in df.keys():
df2 = pd.concat([df2, df[i]],
axis = 0)
display(df2)
|
Output:
2. Extract Text From Images
Now we will discuss how to extract text from images.
For enabling our python program to have Character recognition capabilities, we would be making use of pytesseract OCR library. The library could be installed onto our python environment by executing the following command in the command interpreter of the OS:-
pip install pytesseract
The library (if used on Windows OS) requires the tesseract.exe binary to be also present for proper installation of the library. During the installation of the aforementioned executable, we would be prompted to specify a path for it. This path needs to be remembered as it would be utilized later on in the code. For most installations the path would be C:\\Program Files (x86)\\Tesseract-OCR\\tesseract.exe.
Image for demonstration:

Python3
from PIL import Image
import pytesseract
image = Image.open(r'pic.png')
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
print(pytesseract.image_to_string(image))
|
Output:
GeeksforGeeks
3. Extracting text from Doc File
Here we will extract text from the doc file using docx module.
For installation:
pip install python-docx
Image for demonstration: Aniket_Doc.docx
Example 1: First we’ll extract the title:
Python3
import docx
doc = docx.Document('csv/g.docx')
print(doc.paragraphs[0].text)
|
Output:
My Name Aniket
Example 2: Then we’ll extract the different texts present(excluding the table).
Python3
l=[doc.paragraphs[i].text for i in range(len(doc.paragraphs))]
l=[i for i in l if len(i)!=0]
print(l)
|
Output:
[‘My Name Aniket’, ‘ Hello I am Aniket’, ‘I am giving tutorial on how to extract text from MS Doc.’, ‘Please go through it carefully.’]
Example 3: Now we’ll extract the table:
Python3
table = doc.tables[0]
list1 = []
list2 = []
for i in range(len(table.rows)):
for j in range(len(table.columns)):
list1.append(table.rows[i].cells[j].paragraphs[0].text)
list2.append(list1[:])
list1.clear()
print(list2)
|
Output:
[['A', 'B', 'C'], ['12', 'aNIKET', '@@@'], ['3', 'SOM', '+12&']]
4. Extracting Data From PDF File
The task is to extract Data( Image, text) from PDF in Python. We will extract the images from PDF files and save them using PyMuPDF library. First, we would have to install the PyMuPDF library using Pillow.
pip install PyMuPDF Pillow
Example 1:
Now we will extract data from the pdf version of the same doc file.
Python3
import fitz
docu=fitz.open('file.pdf')
text_list=[]
for i in range(docu.pageCount):
pg=docu.loadPage(i)
pg_txt=pg.getText('text')
text_list.append(pg_txt)
text_list=[i.replace(u'\u200b','') for i in text_list[0].split('\n') if len(i.strip()) ! = 0]
print(text_list)
|
Output:
[‘My Name Aniket ‘, ‘ Hello I am Aniket ‘, ‘I am giving tutorial on how to extract text from MS Doc. ‘, ‘Please go through it carefully. ‘, ‘A ‘, ‘B ‘, ‘C ‘, ’12 ‘, ‘aNIKET ‘, ‘@@@ ‘, ‘3 ‘, ‘SOM ‘, ‘+12& ‘]
Example 2: Extract image from PDF.
Python3
for current_page in range(len(docu)):
for image in docu.getPageImageList(current_page):
xref=image[0]
pix=fitz.Pixmap(docu,xref)
pix.writePNG('page %s - %s.png'%(current_page,xref))
|
The image is stored in our current file location as in format page_no.-xref.png. In our case, its name is page 0-7.png.
Now let’s plot view the image.
Python3
import matplotlib.pyplot as plt
img=plt.imread('page 0 - 7.png')
plt.imshow(img)
|
Output:
Share your thoughts in the comments
Please Login to comment...