How Job runs on MapReduce
Last Updated :
22 Jun, 2022
MapReduce can be used to work with a solitary method call: submit() on a Job object (you can likewise call waitForCompletion(), which presents the activity on the off chance that it hasn’t been submitted effectively, at that point sits tight for it to finish).
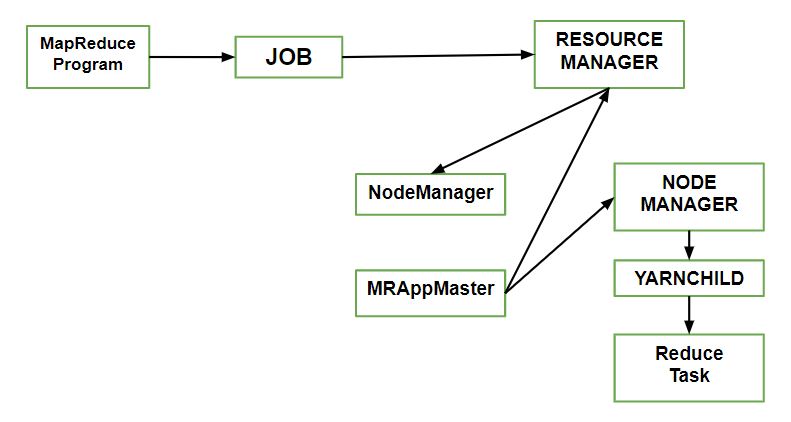
Let’s understand the components –
- Client: Submitting the MapReduce job.
- Yarn node manager: In a cluster, it monitors and launches the compute containers on machines.
- Yarn resource manager: Handles the allocation of computing resources coordination on the cluster.
- MapReduce application master Facilitates the tasks running the MapReduce work.
- Distributed Filesystem: Shares job files with other entities.
How to submit Job?
To create an internal JobSubmitter instance, use the submit() which further calls submitJobInternal() on it. Having submitted the job,
waitForCompletion() polls the job’s progress after submitting the job once per second. If the reports have changed since the last report, it further reports the progress to the console. The job counters are displayed when the job completes successfully. Else the error (that caused the job to fail) is logged to the console.
Processes implemented by JobSubmitter for submitting the Job :
- The resource manager asks for a new application ID that is used for MapReduce Job ID.
- Output specification of the job is checked. For e.g. an error is thrown to the MapReduce program or the job is not submitted or the output directory already exists or it has not been specified.
- If the splits cannot be computed, it computes the input splits for the job. This can be due to the job is not submitted and an error is thrown to the MapReduce program.
- Resources needed to run the job are copied – it includes the job JAR file, and the computed input splits, to the shared filesystem in a directory named after the job ID and the configuration file.
- It copies job JAR with a high replication factor, which is controlled by mapreduce.client.submit.file.replication property. AS there are a number of copies across the cluster for the node managers to access.
- By calling submitApplication(), submits the job to the resource manager.
Share your thoughts in the comments
Please Login to comment...