Job Initialisation in MapReduce
Last Updated :
14 Jul, 2019
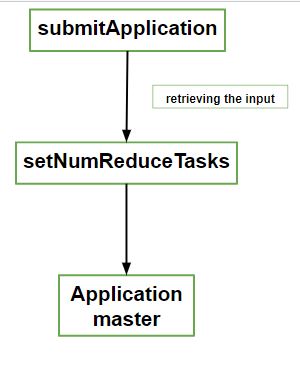
Resource manager hands off the request to the YARN scheduler when it receives a call to its submitApplication() method. The resource manager launches the application master’s process there when the scheduler allocates a container under the node manager’s management. MRAppMaster is the main class of Java application for the Java application that masters for MapReduce jobs. By creating a number of bookkeeping objects, it initializes the job to keep track of the job’s progress. This is because it will receive completion reports and receive progress from the tasks.
The next step is retrieving the input splits. These are computed in the client from the shared filesystem. Then a map task object is created for each split. It also creates a number of reduce task objects determined by the mapreduce.job.reduces property. This property is set by the setNumReduceTasks() method on Job. At this point, tasks are given IDs and how to run the tasks that make up the MapReduce job is decided up by the application master.
Application master may choose to run the tasks in the same JVM as itself if the job is small. If the running tasks and overhead of application running and allocation outweigh the gain to be running in parallel, application master will work on. Such a task is said to be uberised.
A job that is one that has less than 10 mappers, only one reducer can be defined as a small job. For a small job, the size of the input is less that one HDFS block. By setting mapreduce.job.ubertask.maxmaps, mapreduce.job.ubertask.maxreduces, and mapreduce.job.ubertask.maxbytes, these values may be changed for a job.
By setting mapreduce.job.ubertask.enable to true, Uber tasks must be enabled explicitly (for an individual job, or across the cluster). The application master calls the setupJob() method on the OutputCommitter, finally before any tasks can be run, the application master calls the setupJob() method on the OutputCommitter.
The final output directory for the job and the temporary working space for the task output is created by the FileOutputCommitter (it is the default). Final output directory for the job is created and for the task output, the temporary working space is created.
Like Article
Suggest improvement
Share your thoughts in the comments
Please Login to comment...