The S3 bucket is like a big virtual storage depot, where Amazon is the hosting provider (AWS) for data. There it is, a place where you can keep everything, like pictures, videos, and documents, that you’ll need to stay safe and accessible. S3 buckets are a cool thing because they are easy to use and safe to store. Setting aside necessary space allows you to archive as much data as possible, and it removes location restrictions for access even with a poor internet connection. Moreover, like that, AWS does not forget to make sure that your data is secure and has the proper backups, so you need not be worried about data loss. With the S3 buckets, you can combine them with other AWS services, where you may decide to use them for different things, such as hosting websites, backing up databases, or processing large sources of data.
Tools like Databricks make it possible for companies to work with their enormous amounts of data without too much effort. It is like a social club for people to come and work closely together on any data analysis or technical work that involves large amounts of data. Sparks are right at the center of Databricks, which is an effective way of doing fast and accurate analyses. Via Databricks, teams can easily do the data exploration processing, including the data cleaning, and visualizations, using familiar languages like Python, R, and even SQL without spending undisputed effort due to technical details. Instead of spending time on technical setup and maintenance, teams can focus on the most important part: smart cities will utilize this data to come up with deeper insights and smarter decisions. Databricks unites operations involving data engineering with world-class analytics to make organizations capable of transforming data into action that ultimately drives growth in a data-driven world today.
What is a S3 bucket to Databricks?
Say that you have your data kept in a digital locker in Amazon S3 and you want to interact with it with Databricks (a robust tool that can help uncover insights from large data sets) to perform the work. Initially, you have to set Databricks up to read any S3 bucket data that you have access to. This Databricks key is like turning the locker’s lock in the way that only Databricks possesses a unique one. Following that, the Databricks cluster will be set up. This is analogous to a pack of computers, which can be used as worker nodes to process your data. This is about as complicated as it gets; in a way, it’s like hiring a team of data wizards who learn on the job. When you’ve finished setting up the cluster, you should install some libraries or plugins that will allow communication between Databricks and the S3 bucket. If you’re using Python, you can install Boto3 and can have your app work. You will then mount the S3 bucket to the Databricks File System (DBFS), which can be compared to a bridge connecting to a data repository and the Databricks’ workspace. As soon as the bridge button gets clicked, you can begin to read and do data operations on Databricks. This is equivalent to transferring your files from the locker into the Databricks’ workspace, where you perform operations, analysis, and learning with various tools and operations written in languages like Spark, SQL, Python, R, and Scala. During this time, make sure you have efficient data storage and that your resources are used wisely so as not to increase the cost of the project. Therefore, at the end of the data work, you can just “unmount” the S3 bucket from Databricks, which will roughly mean that you have come back to your side of the ocean. The steps in this process automate the upload of your data from the S3 storage system provided by Amazon into Databrick’s analytics platform, which gives you the ability to derive insights from data for analytics reasons of well-informed decisions.
Features of adding a S3 bucket to Databricks
- Single Source of Truth: By an S3 bucket with Databricks you get a central hub that enables storage and data processing. This ability of various teams to adjust the same data leads to the management of data being more efficient and the teams working in an integrated way.
- Flexibility to Grow: In the case of S3 buckets, the company does not ever have to worry about the storage of their data becoming a problem, because, unlike most storage devices, S3 buckets have unlimited storage space. The combination of Databricks with S3 makes them capable of walking through complex data analysis and having no obstacles to deal with while dealing with large-scale.
- Speedy Performance: Databricks is particularly renowned for being capable of managing large data operations comfortably and when it is used alongside S3, the users can take advantage of the high-speed access and processing. This enables a rapid and more data moment translating to effective and timely decision-making.
- Cost-Effective Solution: S3 buckets have a reputation for giving mostly cheap storage options which in cases when businesses are handling a sizeable amount of data. Additionally, S3 and Databricks running on a consumption-oriented system mean that the cost of the operations is a function of utilization yielding in an optimized benefits-cost ratio.
- Secure and Compliant: S3 buckets have the following security properties: encryption, access controls, and compliance certifications. Therefore, data can be safe from unauthorized access, manipulation, or loss, because it remains confidential, intact, and available at all times. Through S3 with Databricks, the company is able to meet such high security and compliance requirements concurrently something such as performing advanced analytics and machine learning tasks.
How do I add a S3 bucket to Databricks?
Step 1: Our first step is to create an S3 Bucket. If you haven’t already, create an S3 bucket in your AWS account where you want to store your data.

Step 2: Now, Configure AWS Credentials in Databricks, user need to configure your AWS credentials to allow Databricks to access their S3 bucket. This can be done by following these steps:
- Go to the Databricks UI and click on the “Compute” tab. Click on the cluster you want to use or create a new one.

- Now we need to create a IAM>Users>User_name>create an access key. This access key by the user will be used in the compute tab where user can use the command to add the S3 bucket in Databricks.
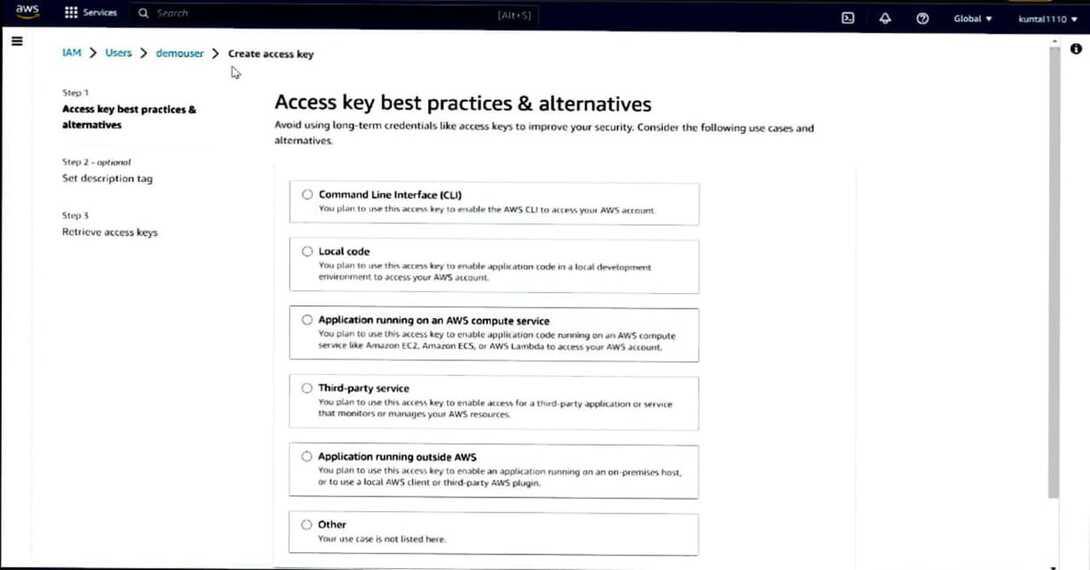
- Optionally, user can also specify an AWS Region if your S3 bucket is in a specific region.

Step 3: Create a new notebook from the compute tab where user can use the command to add the S3 bucket in Databricks.

Step 4: Now we need to mount the S3 Bucket. Once you have configured your AWS credentials, you can mount the S3 bucket in Databricks using the following command in a Databricks notebook:
access_key = ‘xxx’
secret_key = ‘xxx’
encoded_secret_key = secret_key.replace(“/”, “%2F”)
aws_bucket_name = “my-s3-bucket-name”
mount_name = “s3dataread”
dbutils.fs.mount(f”s3a://{access_key}:{encoded_secret_key}@{aws_bucket_name}”, f”/mnt/{mount_name}”)
display(dbutils.fs.ls(f”/mnt/{mount_name}”))
file_location = “dbfs:/mnt/s3dataread/foldername/*”
#Example#
#file_location = “dbfs:/mnt/s3dataread/employee/*”
# The applied options are for CSV files. For other file types, these will be ignored.
df = spark.read.csv(file_location, inferSchema = True, header= True)
df.printSchema()
- Replace <bucket-name> with the name of your S3 bucket, and <mount-name> with the name you want to give to the mount point.

Step 5: Access the Data: After mounting the S3 bucket, you can access the data stored in the bucket using the mount point path /mnt/<mount-name>. For example, if you mounted the bucket with the name “my-bucket” and gave it a mount name “my-data”, you can access the data in the bucket using the path /mnt/my-data.
Advantages of adding a S3 bucket to Databricks
- Grow Without Limits: S3 objects have unlimited storage capacity. Thus when combined with Databricks, companies will never come across the upsurge in their data requirements. These combo can be scaled up which helps them to deploy more comprehensive analytics as their data volume grows.
- Pay Only for What You Use: With S3, storage is usage-based pricing tier, making it one of the low cost storage options. Through it together with Databricks, users of which also have to pay in proportion to utilization, the companies may economize their costs and only pay for the data storage and processing they actually relay on.
- Lightning-Fast Performance: The S3 is built for a quick data service. By connecting it to the Databricks, the users will have the power to do various real-time analytics and data processing. This exponentially improves speed and the quality of the data arrived.
- Easy Data Access: Embedding an S3 bucket is responsible for Databricks users to install this kind of data in the Databricks environment to their disposal. In this manner, various manual data transportation activities are eliminated and thereby, the volumes of workflows gets fast-tracked through boosting the productivity.
- One-Stop Data Shop: A data warehouse integration with S3 enables establishing the centralized area for storing and analyze the data provider by the organization in the whole. It does not matter what data is coming from, it is simplificated, and we are all sure about the consistency.
- Lock it Down: S3 support encryption and access control features in their systems that allow managing and securing critical data completely. This helps to do a good job of data analytics while Databricks is only applicable to your data and hence you have a high standard of maintenance.
- Data Protection: S3 does not need to configure it because S3 automatically creates redundant backups of data which can be used later in case of disaster recovery. Databricks’ Integration offers rules that help the users protect their data when needed.
- Seamless Connections: In AWS, S3 being one of the ecosystem services makes it very easy to integrate it with other analytics services from AWS. Integrating it with Databricks brings the feature into play as data pipelines to create comprehensive interconnected networks which traces back information from many sources.
Disadvantages of adding a S3 bucket to Databricks
- Data Moving Costs: Unlike loading data from S3 to Databricks is inexpensive but you could end up spending more as the constant intersection of large volumes of datasets results in extra overhead expenses. This data transfer can raise significantly production cost if the managers will not give extra attention over them cautiously.
- Potential Lag Time: Using the data stored in S3 service which is beyond the cluster for the storage may cause such that data retrieval take some time-gap as well. This is the case with workloads that majorly manipulate data seeking very fast data retrievals, since the query and processing performance can get significantly deteriorated, especially when larger data sets or high concurrency is involved.
- External Dependency: Databricks may become too reliant on data storage in S3 if Databricks uses S3 for its mass storage. The reliability of the service and the uptime of the S3 service are critical for Databricks and make Databricks dependent on these factors. In this case, the shortcomings of S3 won’t just impact Databricks’ workflows based on S3 data, but will halt them entirely.
- Keeping Data Synced: Keeping the same data states constant in both Databricks and S3 as fairly easy and could get even complicated in distributed environment where different users or processes concurrently work with the same data files. Having inconsistent data could cause you to go wrong with your findings.
- Security Considerations: Combining these two systems necessitates very particular setting up of the security measures which comprise access controls and violation policies to stop unauthorized data access or breaches. Misfit in the configuration could turn out to be to a great security risk by endangering S3 sensitive data.
Conclusion
Finally, combining the Databricks Analytics we have just referred to this incorporation of Amazon S3 is a complete game-changer for companies that focus on data analytics. With the help of these effective tools, the data hub becomes the core of a single source of truth, which makes it possible for teams to find or deliver what they need. S3 has hardly any limit on its storage capacity, thus helping businesses to grow bigger and bigger, without the need for advance preparation, meanwhile Databricks’ pay-as-you-use design lowers down the cost as compared to other products.
Moreover, the fact that the information from S3 is hosted at lightning-fast speed feeds the engines of real-time analytics and computations. “Fluid” setup of data from S3 without manual transferring into the Databricks platform is a way to automate the workflow process. The provider of Now will be continued to make things simple in sharing these hosted platforms with each other thus enhancing the services. So, the “but” side there is the fact that we could be up for data transfer fees that could add up, possible delays with data retrieval from S3, and it is important to be aware of the security issues between the systems. However, sensible planning would address the many more benefits when comparing the negatives.
On closing of the day, a company might take advantage of this integration to empower data analysis and drive smarter decisions making since the current data-driven world has incredibly demanded smarter businesses. Powerful and agile data analysis capabilities that S3 and Databricks possess are vital for organizations that think seriously about transforming data into actionable insights and steady growth.
Adding a S3 bucket to Databricks – FAQ’S
Is there a limit to the size of the S3 bucket I can add to Databricks?
No, there is no inherent limit to the size of the S3 bucket you can add to Databricks. S3 buckets offer virtually unlimited storage capacity, allowing you to scale your data storage needs as required.
Are there additional costs associated with integrating S3 buckets with Databricks?
While there are no specific costs for integrating S3 buckets with Databricks, you should consider potential data moving costs and processing fees incurred by Databricks for accessing and analyzing data stored in the S3 buckets.
How secure is the data stored in S3 buckets when accessed through Databricks?
Both Amazon S3 and Databricks offer robust security features such as encryption, access controls, and compliance certifications. When properly configured, data accessed through Databricks from S3 buckets remains confidential, intact, and available, meeting high-security standards.
Can I access data stored in multiple S3 buckets simultaneously in Databricks?
Yes, you can mount multiple S3 buckets to Databricks and access data from them simultaneously. This capability allows you to aggregate and analyze data from multiple sources seamlessly within the Databricks environment.
What happens if the connection between Databricks and S3 is interrupted?
In the event of a connection interruption between Databricks and S3, access to the S3 data may be temporarily disrupted. However, once the connection is restored, you can resume accessing and analyzing the data without loss or corruption, provided appropriate backup and recovery measures are in place.
Share your thoughts in the comments
Please Login to comment...