Hadoop – Rack and Rack Awareness
Last Updated :
15 Dec, 2022
Most of us are familiar with the term Rack. The rack is a physical collection of nodes in our Hadoop cluster (maybe 30 to 40). A large Hadoop cluster is consists of many Racks. With the help of this Racks information, Namenode chooses the closest Datanode to achieve maximum performance while performing the read/write information which reduces the Network Traffic. A rack can have multiple data nodes storing the file blocks and their replica’s. The Hadoop itself is so smart that it will automatically write a particular file block in 2 different Data nodes in Rack. If you want to store that block of data into more than 2 Racks then you can do that. Also as this feature is configurable means you can change it Manually. Example of Rack in a cluster: 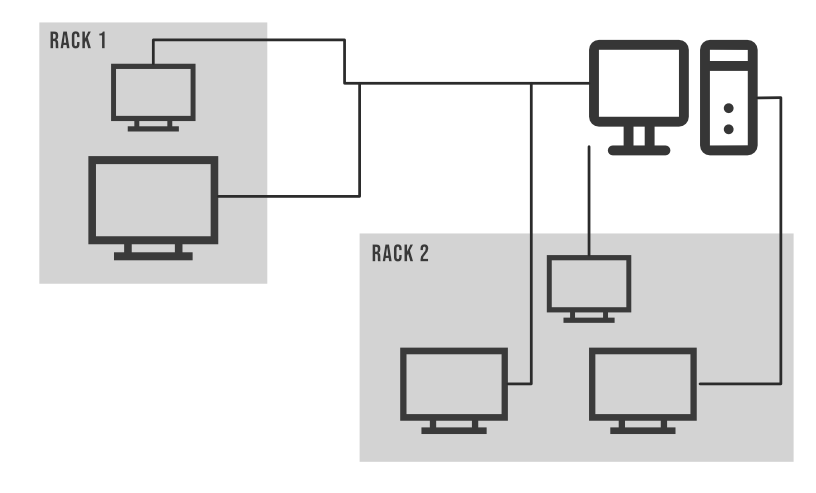 As we all know a large Hadoop cluster contains multiple Racks, in each rack there are lots of data nodes are available. Communication between the Datanodes that are present on the same rack is quite much faster than the communication between the data node present at the 2 different racks. The name node has the feature of finding the closest data node for faster performance for that Name node holds the ids of all the Racks present in the Hadoop cluster. This concept of choosing the closest data node for serving a purpose is Rack Awareness. Let’s understand this with an example.
As we all know a large Hadoop cluster contains multiple Racks, in each rack there are lots of data nodes are available. Communication between the Datanodes that are present on the same rack is quite much faster than the communication between the data node present at the 2 different racks. The name node has the feature of finding the closest data node for faster performance for that Name node holds the ids of all the Racks present in the Hadoop cluster. This concept of choosing the closest data node for serving a purpose is Rack Awareness. Let’s understand this with an example. 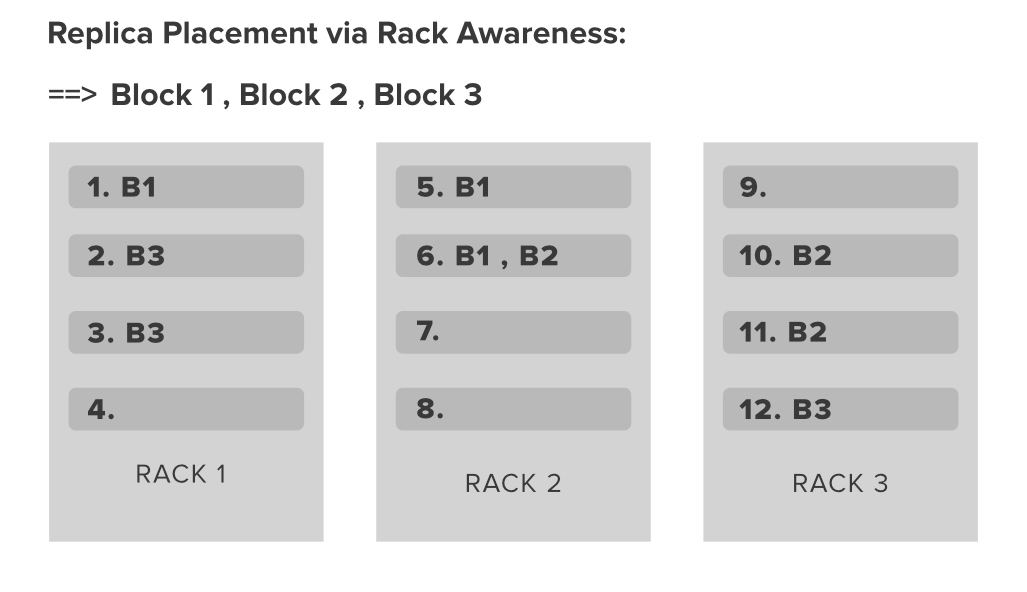 In the above image, we have 3 different Racks in our Hadoop cluster each Rack contains 4 Datanode. Now suppose you have 3 file blocks(Block 1, Block 2, Block 3) that you want to put in this data node. As we all know Hadoop has a Feature to make Replica’s of the file blocks to provide the high availability and fault tolerance. By default, the Replication Factor is 3 so Hadoop is so smart that it will place the replica’s of Blocks in Racks in such a way that we can achieve a good network bandwidth. For that Hadoop has some Rack awareness policies.
In the above image, we have 3 different Racks in our Hadoop cluster each Rack contains 4 Datanode. Now suppose you have 3 file blocks(Block 1, Block 2, Block 3) that you want to put in this data node. As we all know Hadoop has a Feature to make Replica’s of the file blocks to provide the high availability and fault tolerance. By default, the Replication Factor is 3 so Hadoop is so smart that it will place the replica’s of Blocks in Racks in such a way that we can achieve a good network bandwidth. For that Hadoop has some Rack awareness policies.
- There should not be more than 1 replica on the same Datanode.
- More than 2 replica’s of a single block is not allowed on the same Rack.
- The number of racks used inside a Hadoop cluster must be smaller than the number of replicas.
Now let’s continue with our above example. In the diagram, we can easily found that we have block 1 in the first Datanode of Rack 1 and 2 replica’s of Block 1 in 5 and 6 number Data node of Rack which sum up to 3. Similarly, we also have a Replica distribution of 2 other blocks in different Racks which are following the above policies. Benefits of Implementing Rack Awareness in our Hadoop Cluster:
- With the rack awareness policy’s we store the data in different Racks so no way to lose our data.
- Rack awareness helps to maximize the network bandwidth because the data blocks transfer within the Racks.
- It also improves the cluster performance and provides high data availability.
HDFS Rack Awareness Example: 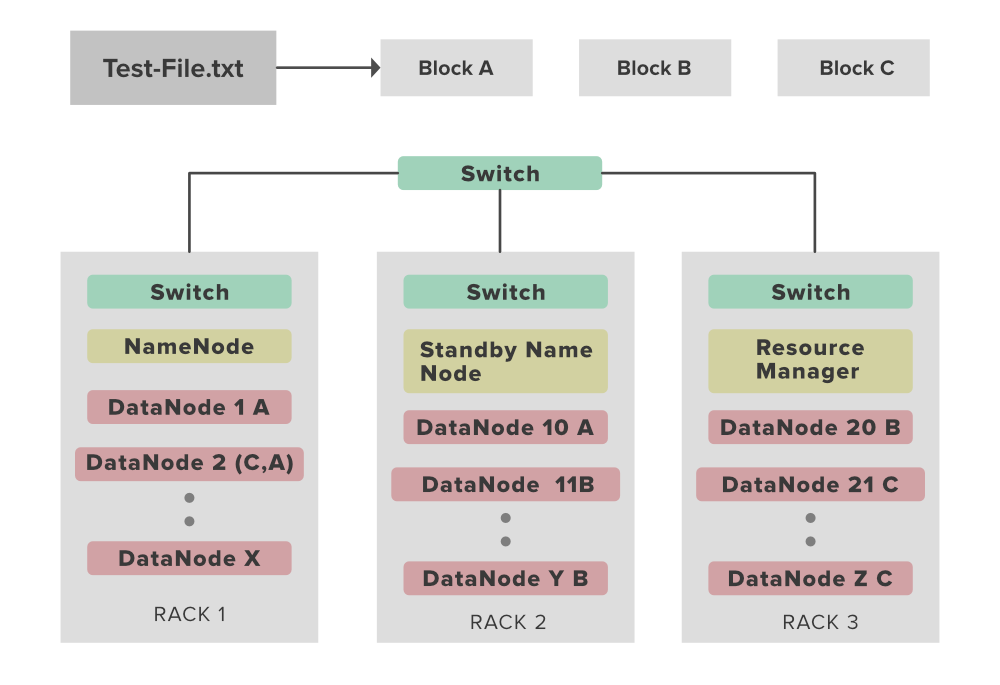
Share your thoughts in the comments
Please Login to comment...