Azure Data Bricks For Spark-Based Analytics
Last Updated :
15 Mar, 2024
Microsoft Azure is a cloud computing platform that provides a variety of services, including virtual machines, Azure App Services, Azure Storage, Azure Data Bricks, and more. Businesses may use Azure to create, deploy, and manage apps and services over Microsoft’s worldwide data center network. Microsoft Azure competes with other major cloud platforms such as Amazon Web Services (AWS) and Google Cloud Platform (GCP), and it is utilized by organizations of all sizes in a variety of sectors for cloud computing.
What Is Spark?
Spark, often referred to as Apache Spark, is an open-source distributed computing platform that offers a programming interface for implicit data parallelism and fault tolerance that can be used to design whole clusters. Created at the University of California, Berkeley’s AMPLab, it became an Apache project in 2013.
Difference Between Hadoop And Spark
With its in-memory computing, Apache Spark outperforms Hadoop, enabling much faster processing through the caching of data over several computations and a decreased dependency on disk I/O. It makes programming more accessible by providing high-level APIs for a variety of workloads, including batch processing, real-time analytics, machine learning, and graph processing.
A core Spark data structure called the Resilient Distributed Dataset (RDD) allows for parallel processing and fault tolerance by representing a distributed collection of items over a cluster.
|
Hadoop
|
Spark
|
|
Batch processing mostly using the MapReduce concept.
|
Processing modes include batch, real-time, iterative, and interactive.
|
|
Disk based data processing.
|
In memory based data processing
|
|
It has java as primary language with mapreduce paradigm.
|
Supports APIs that are high-level in a variety of languages, including Scala, Python, and Java.
|
|
Fault tolerance is offered through replication of data.
|
Uses RDDs for fault tolerance.
|
|
Provides a diverse ecosystem with tools such as HDFS, Hive, and Pig.
|
Extending the ecosystem by adding libraries for streaming, graph processing, machine learning, etc.
|
Azure Databricks
Built on top of Apache Spark, Azure Databricks is a cloud-based platform for large data processing and analytics. It provides an integrated setting where analysts, data engineers, and data scientists may work together on big data projects. Azure Databricks blends Microsoft Azure’s managed services and ease of use with Apache Spark’s performance and scalability.
What Does Spark Do In Azure Databricks?
Spark is the distributed computing engine behind Azure Databricks, which is used to handle massive amounts of data and carry out analytics. By offering high-level APIs and libraries for diverse activities including data transformation, machine learning, streaming analytics, and graph processing, it makes it possible for data scientists, engineers, and analysts to work with enormous datasets effectively. with essence, Spark with Azure Databricks makes it easier to process, explore, and do advanced analytics on data in a cloud environment that is scalable and collaborative.
How To Use Azure Databricks?
The first step is to register for an Azure account. If you are a student, you can join up using your student ID to receive USD 100 credit annually. Alternatively, you can create a free account on Azure and receive USD 200 credit to spend in 30 days.
Step 1: Open Azure Portal
- As soon as you log into your Azure account, a dashboard will show up on your screen.
- A button to create a resource is visible at the top of the dashboard. Following that, you can use the search option to look for Azure DataBricks and click on it.
Step 2: Create Databricks Workspace
- The next step is to construct an Azure Databricks workspace, which requires the creation of a resource group first. Choose “create new” to start a resource group. Subsequently, provide further information such as the workspace name, region, and price tier.
- It will take some time for deployment after that. To build a workspace, click the review and create option. Go to your workspace and select Launch the workspace after it has been deployed. The workspace for Azure Databricks will open in a new tab.

Step 3: Launch Azure Databricks
In Azure Databricks:
- Data can be imported and transformed.
- Create a new notebook for data analysis, transformation and machine learning.
- Facilitate ML model training to enable effective iteration and discovery.
- The dashboard of Azure Databricks, where you may create your notebook and carry out tasks, is visible in the newly created tab.
- However, we must import the dataset into the Azure storage account before we can begin working on the project.
- By selecting Upload Data, you may load it straight into an Azure Storage account. Alternatively, you can use Azure Data Factory to build pipelines that load the data.
.png)
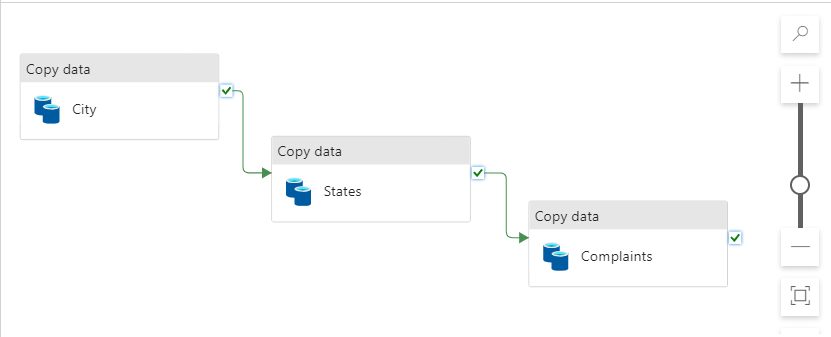
Step 4: Load Data Using Azure Data Factory
- To be familiar with using Azure DataBricks we’ll use a basic Kaggle dataset regarding crimes in India. We used Azure Data Factory to create pipelines for data intake after uploading the dataset to Gihub.
- We used Azure Data Lake Storage Gen1 to create the dataset on the source side, then uploaded the raw dataset to github using the connection we gave on the new link service.

- The github link format should look like this: <user-name>/<repo-name>/blob/main/dataset/data.csv on github.com
- A Data Pipeline is a set of procedures that gathers information from multiple sources, modifies it, and loads it somewhere, usually for analysis.
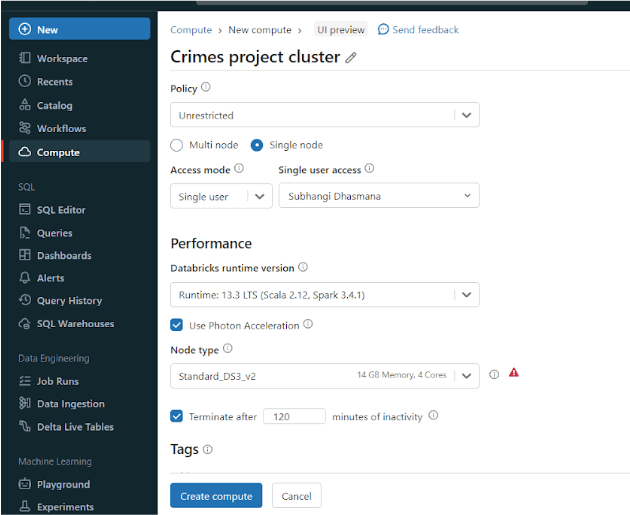
Step 5: Create Cluster In Azure Databricks
- In Azure Databricks, a cluster must be created in order to carry out distributed data processing operations effectively. Multiple computing nodes work together to handle sophisticated computations and vast volumes of data in clusters. You may take advantage of parallel processing by grouping computers together to form a cluster, which will speed up operations like data exploration, analysis, and machine learning. Clusters enable resource and cost optimization by scaling up or down in response to workload needs.
- Cluster: A collection of networked computers that collaborate to process and analyze big datasets simultaneously.
- In order to construct a cluster in data bricks, we will first click on compute. With version 13.3 LTS and the Standard_D53_v2 node type, I have used the single-user access mode.
Step 6: Create App Registration
- To give Azure access to the dataset in the “crimesdata” storage account, the “crimesapp” app registration was made. The IDs of the tenants and clients were copied and safely kept in a notepad for later use.
- A discrete key is generated and discreetly stored, which is essential for data recovery. Safeguarding the secret key and client ID is essential to guaranteeing restricted and safe access to Azure data storage.

Step 7: Create New Notebook In Azure Databricks
- To create a new notebook in Azure Databricks, click new, as shown below:

- Write the following code to create a connection after adding a new notebook to Azure Databricks.
configs = {
"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth.client.id": "<client-id>",
"fs.azure.account.oauth.client.secret": "<client-secret>",
"fs.azure.account.oauth.client.endpoint": "https://login.microsoftonline.com/<tenant-id>/oauth2/token"
}
dbutils.fs.mount(
source="abfss://crimescontainer@crimesdata.dfs.core.window.net",
mount_point="/mnt/crimes",
extra_configs=configs
)
- The scope feature of Azure Databricks was employed to safeguard credentials. Because secrets are created and kept there for extra protection, Key Vault is crucial.
- Sensitive data is protected through integration with Key Vault, and credentials can be accessed by Databricks notebooks without being directly exposed.
Step 8: Load Data Into Azure Databricks
- The data must now be shown in Azure DataBricks, which are kept in an Azure Storage Account.
- With the following command, we can see the path of the data that is stored:
%fs
ls "/mnt/<actual-folder-name>"
Use the below commands to load data and display:
data = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/mnt/crimes/raw-data/crimes.csv")
data.show()
Step 9: Execute The Operation
Total Crime On Basis Of Year
We started by creating a spark session and then determined the overall number of crimes. We added the total number of offenses to a newly constructed dataframe called crime_df. We created a bar graph of the result using the matplotlib library.
from pyspark.sql import SparkSession
from pyspark.sql.functions import sum
import matplotlib.pyplot as plt
import pandas as pd
# Create spark session
spark = SparkSession.builder.appName("CrimesPlot").getOrCreate()
# Assuming you have a DataFrame named 'states'
# If not, replace 'states' with the actual DataFrame name
states = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load("/path/to/your/data.csv")
# Calculate total crimes
crimes_totals = states.groupBy().agg(sum("2019").alias("2019"), sum("2020").alias("2020"), sum("2021").alias("2021")).collect()[0]
# Create a Pandas DataFrame for plotting
crimes_df = pd.DataFrame({'Year': ['2019', '2020', '2021'], 'Cases': [crimes_totals['2019'], crimes_totals['2020'], crimes_totals['2021']]})
# Plot the graph
crimes_df.plot(kind='bar', x='Year', y='Cases', color='skyblue')
plt.xlabel("Year", color="red")
plt.ylabel("Cases (in millions)", color="red")
plt.title("Crimes each year (State/UT)")
plt.show()
Output

Azure DataBricks – FAQ’s
What Is Cloud Computing?
The provision of computer services via the internet (also referred to as “the cloud”) includes servers, storage, databases, networking, software, and more. It frees users from having to own or maintain the physical infrastructure by enabling them to access and use resources as needed.
What Is Hadoop?
Hadoop is an open-source framework that uses straightforward programming models to distribute large dataset processing and storage across computer clusters. It provides fault tolerance and reliability and can scale up from single servers to thousands of machines.
What Benefits Does Utilizing Azure Databricks Have Over More Conventional Approaches To Data Processing?
Faster data processing, smooth integration with other Azure services, integrated security features, and a team-friendly collaborative workspace are all provided by Azure Databricks.
Use Cases Of Azure Databricks
Use cases span a variety of industries, including banking, healthcare, retail, and manufacturing. They include data preparation and exploration, real-time analytics, machine learning model creation, predictive analytics, and IoT data processing.
Can You Utilize Azure Databricks For Real-Time Data Processing?
Azure Databricks enables real-time data processing by integrating with streaming services such as Azure Event Hubs and Azure Stream Analytics, allowing for near real-time analytics and insights.
Share your thoughts in the comments
Please Login to comment...