Hadoop – A Solution For Big Data
Last Updated :
10 Jul, 2020
Wasting the useful information hidden behind the data can be a dangerous roadblock for industries, ignoring this information eventually pulls your industry growth back. Data? Big Data? How big you think it is, yes it’s really huge in volume with huge velocity, variety, veracity, and value. So how do you think humans find the solution to deal with this big data. Let’s discuss these various approaches one by one.
Traditional Approach
In traditional Approach, earlier the Big Giant tech company Handles the data on a single system storing and processing the data with the help of various database vendors available in the market like IBM, Oracle, etc. The databases used at that time use RDBMS(Relational Database Management System) which is used for storing the structured data. The developer uses a short Application that helps them to communicate with the databases and help them to maintain, analyze, modify, and visualize the data stored.
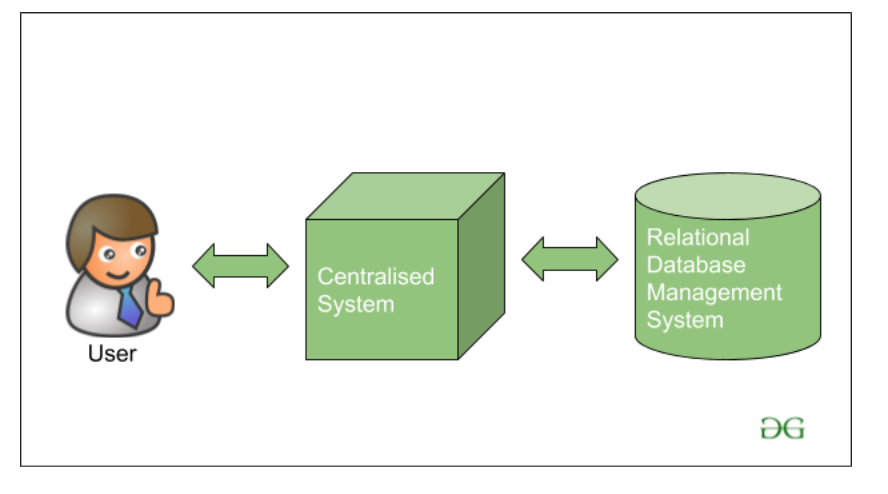
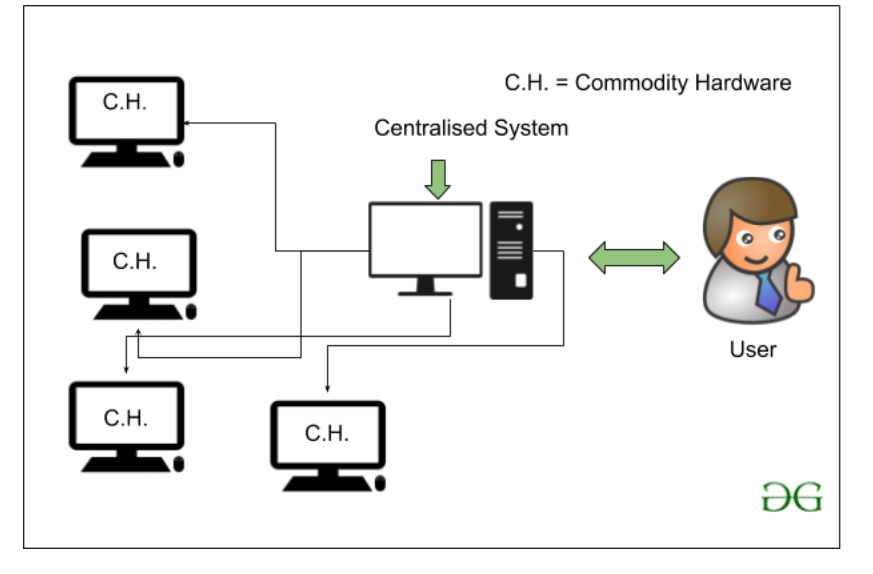
But there is a problem with using this traditional approach, the problem is that the database server at that time which is actually the commodity hardware is capable of only storing and maintaining a very less size of data. The data can only be processed up to a limit i.e. about the processing speed of the processors available at that time. Also, the servers are not very efficient or capable of handling the velocity and variety of data because we are not using a cluster of computer systems. A single database server is dedicated to handling all this data.
How Google finds it’s Solution for Big Data?
Google at that time introduced the algorithm name MapReduce. MapReduce works on a master-slave architecture means that rather than dedicating a single database server for handling the data google introduced a new terminology where there is Master who will guide the other slave nodes to handle this big data. The task should be divided into various blocks and then be distributed among these slaves. Then once the slaves process the data the Master will gather the result obtained from the various slaves’ nodes and make the final result Dataset.
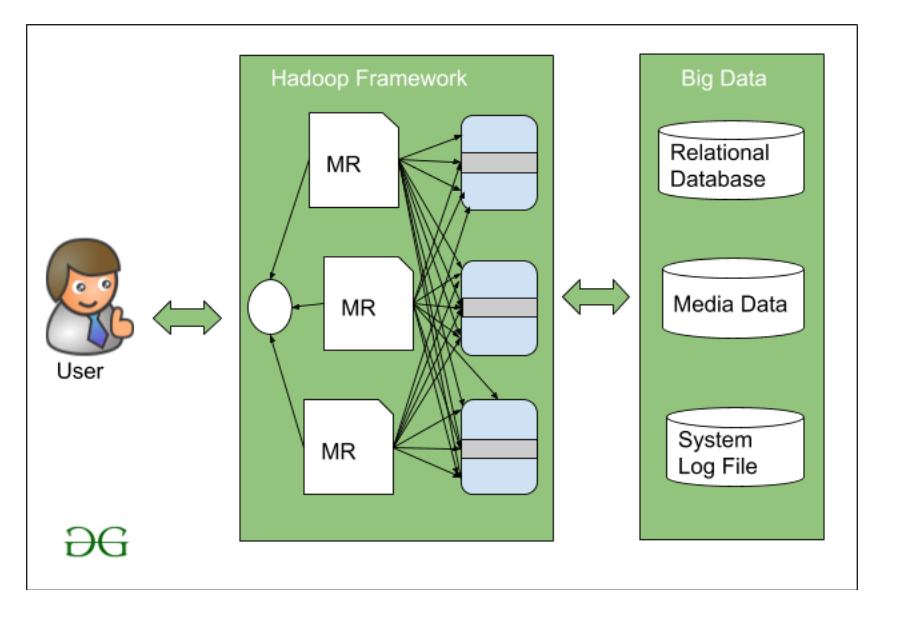
Later on, Doug Cutting and his co-worker Mike Cafarella in 2005 decided to make an open-source software that can work on this MapReduce algorithm. This is where the picture of Hadoop is introduced for the first time to deal with the very larger data set.
Hadoop is a framework written in Java that works over the collection of various simple commodity hardware to deal with the large dataset using a very basic level programming model.
Share your thoughts in the comments
Please Login to comment...